Αυτή η ανάρτηση ιστολογίου συντάχθηκε με την Caroline Chung από το Veoneer.
Η Veoneer είναι μια παγκόσμια εταιρεία ηλεκτρονικών αυτοκινήτων και παγκόσμιος ηγέτης στα ηλεκτρονικά συστήματα ασφαλείας αυτοκινήτου. Προσφέρουν τα καλύτερα στην κατηγορία τους συστήματα ελέγχου συγκράτησης και έχουν παραδώσει πάνω από 1 δισεκατομμύριο ηλεκτρονικές μονάδες ελέγχου και αισθητήρες σύγκρουσης σε κατασκευαστές αυτοκινήτων παγκοσμίως. Η εταιρεία συνεχίζει να βασίζεται σε μια ιστορία 70 χρόνων ανάπτυξης της ασφάλειας του αυτοκινήτου, με εξειδίκευση σε εξοπλισμό και συστήματα αιχμής που αποτρέπουν τροχαία συμβάντα και μετριάζουν τα ατυχήματα.
Το Automotive in-cabin sensing (ICS) είναι ένας αναδυόμενος χώρος που χρησιμοποιεί έναν συνδυασμό πολλών τύπων αισθητήρων, όπως κάμερες και ραντάρ, και αλγόριθμους βασισμένους στην τεχνητή νοημοσύνη (AI) και τη μηχανική μάθηση (ML) για τη βελτίωση της ασφάλειας και τη βελτίωση της οδηγικής εμπειρίας. Η κατασκευή ενός τέτοιου συστήματος μπορεί να είναι μια πολύπλοκη εργασία. Οι προγραμματιστές πρέπει να σχολιάζουν με μη αυτόματο τρόπο μεγάλους όγκους εικόνων για σκοπούς εκπαίδευσης και δοκιμής. Αυτό είναι πολύ χρονοβόρο και απαιτεί πόρους. Ο χρόνος διεκπεραίωσης για μια τέτοια εργασία είναι αρκετές εβδομάδες. Επιπλέον, οι εταιρείες πρέπει να αντιμετωπίσουν ζητήματα όπως ασυνεπείς ετικέτες λόγω ανθρώπινων σφαλμάτων.
Το AWS επικεντρώνεται στο να σας βοηθήσει να αυξήσετε την ταχύτητα ανάπτυξής σας και να μειώσετε το κόστος για την κατασκευή τέτοιων συστημάτων μέσω προηγμένων αναλυτικών στοιχείων όπως το ML. Το όραμά μας είναι να χρησιμοποιήσουμε την ML για αυτοματοποιημένο σχολιασμό, επιτρέποντας την επανεκπαίδευση μοντέλων ασφαλείας και διασφαλίζοντας συνεπείς και αξιόπιστες μετρήσεις απόδοσης. Σε αυτήν την ανάρτηση, μοιραζόμαστε τον τρόπο, συνεργαζόμενοι με τον Παγκόσμιο Οργανισμό Ειδικών της Amazon και το Generative AI Innovation Center, αναπτύξαμε μια διοχέτευση ενεργής εκμάθησης για κουτιά οριοθέτησης κεφαλής εικόνας στην καμπίνα και σχολιασμούς βασικών σημείων. Η λύση μειώνει το κόστος πάνω από 90%, επιταχύνει τη διαδικασία σχολιασμού από εβδομάδες σε ώρες όσον αφορά τον χρόνο διεκπεραίωσης και επιτρέπει την επαναχρησιμοποίηση για παρόμοιες εργασίες επισήμανσης δεδομένων ML.
Επισκόπηση λύσεων
Η ενεργός μάθηση είναι μια προσέγγιση ML που περιλαμβάνει μια επαναληπτική διαδικασία επιλογής και σχολιασμού των πιο ενημερωτικών δεδομένων για την εκπαίδευση ενός μοντέλου. Λαμβάνοντας υπόψη ένα μικρό σύνολο δεδομένων με ετικέτα και ένα μεγάλο σύνολο δεδομένων χωρίς ετικέτα, η ενεργή μάθηση βελτιώνει την απόδοση του μοντέλου, μειώνει την προσπάθεια επισήμανσης και ενσωματώνει την ανθρώπινη τεχνογνωσία για αξιόπιστα αποτελέσματα. Σε αυτήν την ανάρτηση, χτίζουμε έναν ενεργό αγωγό εκμάθησης για σχολιασμούς εικόνων με υπηρεσίες AWS.
Το παρακάτω διάγραμμα δείχνει το συνολικό πλαίσιο για την ενεργή μάθηση. Ο αγωγός επισήμανσης λαμβάνει εικόνες από ένα Απλή υπηρεσία αποθήκευσης Amazon (Amazon S3) κουβάς και βγάζει σχολιασμένες εικόνες με τη συνεργασία μοντέλων ML και ανθρώπινης τεχνογνωσίας. Ο αγωγός εκπαίδευσης προεπεξεργάζεται δεδομένα και τα χρησιμοποιεί για να εκπαιδεύσει μοντέλα ML. Το αρχικό μοντέλο ρυθμίζεται και εκπαιδεύεται σε ένα μικρό σύνολο δεδομένων με μη αυτόματο τρόπο και θα χρησιμοποιηθεί στη διοχέτευση ετικετών. Ο αγωγός ετικετών και ο αγωγός εκπαίδευσης μπορούν να επαναληφθούν σταδιακά με περισσότερα δεδομένα με ετικέτα για τη βελτίωση της απόδοσης του μοντέλου.
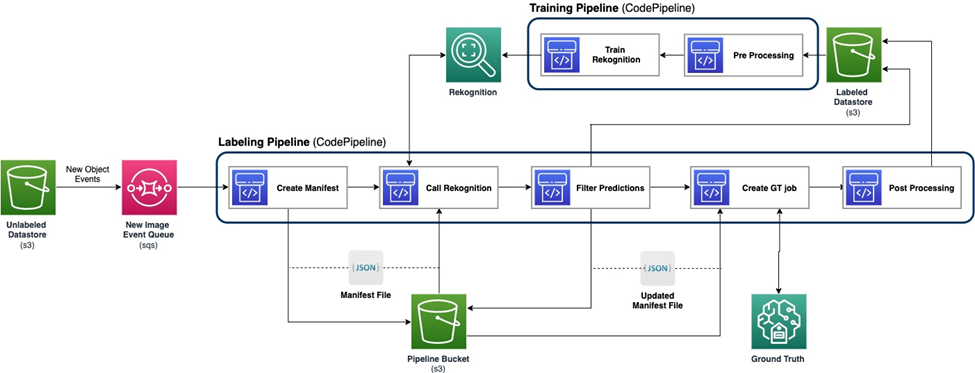
Στον αγωγό επισήμανσης, ένα Ειδοποίηση συμβάντος Amazon S3 καλείται όταν μια νέα παρτίδα εικόνων μπαίνει στον κάδο Unlabeled Datastore S3, ενεργοποιώντας τη διοχέτευση ετικετών. Το μοντέλο παράγει τα αποτελέσματα συμπερασμάτων στις νέες εικόνες. Μια προσαρμοσμένη συνάρτηση κρίσης επιλέγει μέρη των δεδομένων με βάση τη βαθμολογία εμπιστοσύνης συμπερασμάτων ή άλλες λειτουργίες που καθορίζονται από τον χρήστη. Αυτά τα δεδομένα, με τα συμπεράσματά τους, αποστέλλονται για εργασία επισήμανσης ανθρώπων Amazon SageMaker Ground Αλήθεια που δημιουργήθηκε από τον αγωγό. Η διαδικασία ανθρώπινης επισήμανσης βοηθά στον σχολιασμό των δεδομένων και τα τροποποιημένα αποτελέσματα συνδυάζονται με τα υπόλοιπα δεδομένα με αυτόματο σχολιασμό, τα οποία μπορούν να χρησιμοποιηθούν αργότερα από τη γραμμή εκπαίδευσης.
Η επανεκπαίδευση μοντέλων πραγματοποιείται στη γραμμή εκπαίδευσης, όπου χρησιμοποιούμε το σύνολο δεδομένων που περιέχει τα δεδομένα με ετικέτα ανθρώπου για να επανεκπαιδεύσουμε το μοντέλο. Παράγεται ένα αρχείο δήλωσης για να περιγράψει πού αποθηκεύονται τα αρχεία και το ίδιο αρχικό μοντέλο επανεκπαιδεύεται στα νέα δεδομένα. Μετά την επανεκπαίδευση, το νέο μοντέλο αντικαθιστά το αρχικό μοντέλο και ξεκινά η επόμενη επανάληψη του ενεργού αγωγού εκμάθησης.
Ανάπτυξη μοντέλου
Τόσο ο αγωγός επισήμανσης όσο και ο αγωγός εκπαίδευσης αναπτύσσονται στον Αγωγός κώδικα AWS. AWS CodeBuild Τα στιγμιότυπα χρησιμοποιούνται για υλοποίηση, η οποία είναι ευέλικτη και γρήγορη για μικρό όγκο δεδομένων. Όταν χρειάζεται ταχύτητα, χρησιμοποιούμε Amazon Sage Maker τελικά σημεία που βασίζονται στην παρουσία της GPU για την κατανομή περισσότερων πόρων για την υποστήριξη και την επιτάχυνση της διαδικασίας.
Ο αγωγός επανεκπαίδευσης του μοντέλου μπορεί να γίνει επίκληση όταν υπάρχει νέο σύνολο δεδομένων ή όταν η απόδοση του μοντέλου χρειάζεται βελτίωση. Ένα κρίσιμο καθήκον στον αγωγό επανεκπαίδευσης είναι να υπάρχει το σύστημα ελέγχου έκδοσης τόσο για τα δεδομένα εκπαίδευσης όσο και για το μοντέλο. Αν και οι υπηρεσίες AWS όπως π.χ Αναγνώριση Amazon διαθέτουν την ενσωματωμένη δυνατότητα ελέγχου έκδοσης, η οποία καθιστά εύκολη την εφαρμογή της διοχέτευσης, τα προσαρμοσμένα μοντέλα απαιτούν καταγραφή μεταδεδομένων ή πρόσθετα εργαλεία ελέγχου έκδοσης.
Ολόκληρη η ροή εργασίας υλοποιείται χρησιμοποιώντας το Κιτ ανάπτυξης AWS Cloud (AWS CDK) για τη δημιουργία των απαραίτητων στοιχείων AWS, συμπεριλαμβανομένων των εξής:
- Δύο ρόλοι για εργασίες CodePipeline και SageMaker
- Δύο εργασίες CodePipeline, οι οποίες ενορχηστρώνουν τη ροή εργασίας
- Δύο κάδοι S3 για τα τεχνουργήματα κωδικών των αγωγών
- Ένας κάδος S3 για την επισήμανση της δήλωσης εργασίας, των συνόλων δεδομένων και των μοντέλων
- Προεπεξεργασία και μετεπεξεργασία AWS Lambda λειτουργίες για τις εργασίες επισήμανσης του SageMaker Ground Truth
Οι στοίβες CDK AWS είναι εξαιρετικά διαμορφωμένες και επαναχρησιμοποιήσιμες σε διαφορετικές εργασίες. Η εκπαίδευση, ο κώδικας συμπερασμάτων και το πρότυπο SageMaker Ground Truth μπορούν να αντικατασταθούν για οποιαδήποτε παρόμοια ενεργά σενάρια εκμάθησης.
Εκπαίδευση μοντέλων
Η εκπαίδευση μοντέλων περιλαμβάνει δύο εργασίες: σχολιασμό πλαισίου οριοθέτησης κεφαλιού και σχολιασμό σημείων βασικών ανθρώπων. Τα παρουσιάζουμε και τα δύο σε αυτή την ενότητα.
Σχολιασμός πλαισίου οριοθέτησης κεφαλιού
Ο σχολιασμός πλαισίου οριοθέτησης κεφαλιού είναι μια εργασία για την πρόβλεψη της θέσης ενός πλαισίου οριοθέτησης του ανθρώπινου κεφαλιού σε μια εικόνα. Χρησιμοποιούμε ένα Προσαρμοσμένες ετικέτες αναγνώρισης Amazon μοντέλο για σχολιασμούς πλαισίου οριοθέτησης κεφαλής. Το ακόλουθο δείγμα σημειωματάριου παρέχει έναν οδηγό βήμα προς βήμα σχετικά με τον τρόπο εκπαίδευσης ενός μοντέλου προσαρμοσμένων ετικετών αναγνώρισης μέσω του SageMaker.
Πρώτα πρέπει να προετοιμάσουμε τα δεδομένα για να ξεκινήσουμε την εκπαίδευση. Δημιουργούμε ένα αρχείο δήλωσης για την εκπαίδευση και ένα αρχείο δήλωσης για το σύνολο δεδομένων δοκιμής. Ένα αρχείο δήλωσης περιέχει πολλά στοιχεία, καθένα από τα οποία είναι για μια εικόνα. Το παρακάτω είναι ένα παράδειγμα του αρχείου δήλωσης, το οποίο περιλαμβάνει τη διαδρομή εικόνας, το μέγεθος και τις πληροφορίες σχολιασμού:
Χρησιμοποιώντας τα αρχεία δήλωσης, μπορούμε να φορτώσουμε σύνολα δεδομένων σε ένα μοντέλο προσαρμοσμένων ετικετών αναγνώρισης για εκπαίδευση και δοκιμή. Επαναλάβαμε το μοντέλο με διαφορετικές ποσότητες δεδομένων εκπαίδευσης και το δοκιμάσαμε στις ίδιες 239 αόρατες εικόνες. Σε αυτό το τεστ, το mAP_50 Η βαθμολογία αυξήθηκε από 0.33 με 114 προπονητικές εικόνες σε 0.95 με 957 προπονητικές εικόνες. Το παρακάτω στιγμιότυπο οθόνης δείχνει τις μετρήσεις απόδοσης του τελικού μοντέλου προσαρμοσμένων ετικετών αναγνώρισης, το οποίο αποδίδει εξαιρετική απόδοση όσον αφορά τη βαθμολογία F1, την ακρίβεια και την ανάκληση.

Δοκιμάσαμε περαιτέρω το μοντέλο σε ένα συγκρατημένο σύνολο δεδομένων που έχει 1,128 εικόνες. Το μοντέλο προβλέπει με συνέπεια ακριβείς προβλέψεις πλαισίου οριοθέτησης στα αόρατα δεδομένα, αποδίδοντας υψηλό mAP_50 του 94.9%. Το ακόλουθο παράδειγμα δείχνει μια εικόνα με αυτόματο σχολιασμό με πλαίσιο οριοθέτησης κεφαλής.

Σχολιασμός βασικών σημείων
Ο σχολιασμός βασικών σημείων δημιουργεί τοποθεσίες βασικών σημείων, συμπεριλαμβανομένων των ματιών, των αυτιών, της μύτης, του στόματος, του λαιμού, των ώμων, των αγκώνων, των καρπών, των γοφών και των αστραγάλων. Εκτός από την πρόβλεψη τοποθεσίας, απαιτείται ορατότητα κάθε σημείου για την πρόβλεψη σε αυτή τη συγκεκριμένη εργασία, για την οποία σχεδιάζουμε μια νέα μέθοδο.
Για τον σχολιασμό βασικών σημείων, χρησιμοποιούμε α Μοντέλο Yolo 8 Pose στο SageMaker ως αρχικό μοντέλο. Αρχικά προετοιμάζουμε τα δεδομένα για εκπαίδευση, συμπεριλαμβανομένης της δημιουργίας αρχείων ετικετών και ενός αρχείου διαμόρφωσης .yaml σύμφωνα με τις απαιτήσεις του Yolo. Μετά την προετοιμασία των δεδομένων, εκπαιδεύουμε το μοντέλο και αποθηκεύουμε αντικείμενα, συμπεριλαμβανομένου του αρχείου βαρών μοντέλου. Με το εκπαιδευμένο αρχείο βαρών μοντέλου, μπορούμε να σχολιάσουμε τις νέες εικόνες.
Στο στάδιο της εκπαίδευσης, όλα τα σημειωμένα σημεία με τοποθεσίες, συμπεριλαμβανομένων των ορατών σημείων και των αποφραγμένων σημείων, χρησιμοποιούνται για την εκπαίδευση. Επομένως, αυτό το μοντέλο παρέχει από προεπιλογή τη θέση και την εμπιστοσύνη της πρόβλεψης. Στο παρακάτω σχήμα, ένα μεγάλο όριο εμπιστοσύνης (κύριο όριο) κοντά στο 0.6 είναι ικανό να διαιρέσει τα σημεία που είναι ορατά ή αποφραγμένα σε σχέση με τα σημεία που βρίσκονται έξω από τις οπτικές γωνίες της κάμερας. Ωστόσο, τα αποφραγμένα σημεία και τα ορατά σημεία δεν διαχωρίζονται από την εμπιστοσύνη, πράγμα που σημαίνει ότι η προβλεπόμενη εμπιστοσύνη δεν είναι χρήσιμη για την πρόβλεψη της ορατότητας.

Για να έχουμε την πρόβλεψη της ορατότητας, εισάγουμε ένα πρόσθετο μοντέλο εκπαιδευμένο στο σύνολο δεδομένων που περιέχει μόνο ορατά σημεία, εξαιρουμένων τόσο των αποφραγμένων σημείων όσο και εκτός των οπτικών γωνιών της κάμερας. Το παρακάτω σχήμα δείχνει την κατανομή σημείων με διαφορετική ορατότητα. Ορατά σημεία και άλλα σημεία μπορούν να διαχωριστούν στο πρόσθετο μοντέλο. Μπορούμε να χρησιμοποιήσουμε ένα όριο (πρόσθετο όριο) κοντά στο 0.6 για να λάβουμε τα ορατά σημεία. Συνδυάζοντας αυτά τα δύο μοντέλα, σχεδιάζουμε μια μέθοδο πρόβλεψης της τοποθεσίας και της ορατότητας.

Ένα βασικό σημείο προβλέπεται πρώτα από το κύριο μοντέλο με την τοποθεσία και την κύρια εμπιστοσύνη, μετά παίρνουμε την πρόσθετη πρόβλεψη εμπιστοσύνης από το πρόσθετο μοντέλο. Στη συνέχεια, η ορατότητά του ταξινομείται ως εξής:
- Ορατό, εάν η κύρια εμπιστοσύνη του είναι μεγαλύτερη από το κύριο όριο και η πρόσθετη εμπιστοσύνη του είναι μεγαλύτερη από το πρόσθετο όριο
- Αποκλείεται, εάν η κύρια εμπιστοσύνη του είναι μεγαλύτερη από το κύριο όριο και η πρόσθετη εμπιστοσύνη είναι μικρότερη ή ίση με το πρόσθετο όριο
- Εκτός του ελέγχου της κάμερας, εάν είναι διαφορετικά
Ένα παράδειγμα σχολιασμού βασικών σημείων παρουσιάζεται στην ακόλουθη εικόνα, όπου τα συμπαγή σημάδια είναι ορατά σημεία και τα κοίλα σημάδια είναι αποφραγμένα σημεία. Τα σημεία ελέγχου εκτός της κάμερας δεν εμφανίζονται.

Με βάση το πρότυπο OKS ορισμός στο σύνολο δεδομένων MS-COCO, η μέθοδός μας είναι σε θέση να επιτύχει mAP_50 του 98.4% στο αόρατο σύνολο δεδομένων δοκιμής. Όσον αφορά την ορατότητα, η μέθοδος αποδίδει ακρίβεια ταξινόμησης 79.2% στο ίδιο σύνολο δεδομένων.
Επισήμανση και επανεκπαίδευση του ανθρώπου
Αν και τα μοντέλα επιτυγχάνουν εξαιρετική απόδοση σε δεδομένα δοκιμών, εξακολουθούν να υπάρχουν πιθανότητες να γίνουν λάθη σε νέα δεδομένα πραγματικού κόσμου. Η επισήμανση του ανθρώπου είναι η διαδικασία για τη διόρθωση αυτών των λαθών για τη βελτίωση της απόδοσης του μοντέλου με τη χρήση επανεκπαίδευσης. Σχεδιάσαμε μια συνάρτηση κρίσης που συνδύαζε την τιμή εμπιστοσύνης που εξάγεται από τα μοντέλα ML για την έξοδο όλων των πλαισίου οριοθέτησης κεφαλής ή των βασικών σημείων. Χρησιμοποιούμε την τελική βαθμολογία για να εντοπίσουμε αυτά τα λάθη και τις εικόνες που προκύπτουν με κακή επισήμανση, οι οποίες πρέπει να αποσταλούν στη διαδικασία ανθρώπινης επισήμανσης.
Εκτός από τις εικόνες με κακή ετικέτα, ένα μικρό μέρος των εικόνων επιλέγεται τυχαία για ανθρώπινη επισήμανση. Αυτές οι εικόνες με ανθρώπινη ετικέτα προστίθενται στην τρέχουσα έκδοση του σετ εκπαίδευσης για επανεκπαίδευση, βελτίωση της απόδοσης του μοντέλου και της συνολικής ακρίβειας σχολιασμού.
Στην υλοποίηση, χρησιμοποιούμε το SageMaker Ground Truth για το ανθρώπινη επισήμανση επεξεργάζομαι, διαδικασία. Το SageMaker Ground Truth παρέχει μια φιλική προς το χρήστη και εύχρηστη διεπαφή χρήστη για την επισήμανση δεδομένων. Το παρακάτω στιγμιότυπο οθόνης δείχνει μια εργασία επισήμανσης ετικετών SageMaker Ground Truth για σχολιασμό πλαισίου οριοθέτησης κεφαλιού.

Το ακόλουθο στιγμιότυπο οθόνης δείχνει μια εργασία επισήμανσης ετικετών SageMaker Ground Truth για σχολιασμούς βασικών σημείων.

Κόστος, ταχύτητα και επαναχρησιμοποίηση
Το κόστος και η ταχύτητα είναι τα βασικά πλεονεκτήματα της χρήσης της λύσης μας σε σύγκριση με την ανθρώπινη επισήμανση, όπως φαίνεται στους παρακάτω πίνακες. Χρησιμοποιούμε αυτούς τους πίνακες για να αναπαραστήσουμε την εξοικονόμηση κόστους και τις επιταχύνσεις ταχύτητας. Χρησιμοποιώντας την επιταχυνόμενη GPU SageMaker instance ml.g4dn.xlarge, το συνολικό κόστος εκπαίδευσης και συμπερασμάτων σε 100,000 εικόνες είναι 99% μικρότερο από το κόστος της ανθρώπινης επισήμανσης, ενώ η ταχύτητα είναι 10-10,000 φορές μεγαλύτερη από την ανθρώπινη ετικέτα, ανάλογα με το έργο.
Ο πρώτος πίνακας συνοψίζει τις μετρήσεις απόδοσης κόστους.
| Μοντέλο | mAP_50 με βάση 1,128 δοκιμαστικές εικόνες | Κόστος εκπαίδευσης με βάση 100,000 εικόνες | Κόστος συμπερασμάτων με βάση 100,000 εικόνες | Μείωση κόστους σε σύγκριση με τον ανθρώπινο σχολιασμό | Χρόνος συμπερασμάτων με βάση 100,000 εικόνες | Επιτάχυνση χρόνου σε σύγκριση με τον ανθρώπινο σχολιασμό |
| Κουτί οριοθέτησης κεφαλής αναγνώρισης | 0.949 | $4 | $22 | 99% λιγότερο | 5.5 h | Ημ. |
| Yolo Βασικά σημεία | 0.984 | $27.20 | * 10 $ | 99.9% λιγότερο | πρακτικά | Εβδ. |
Ο παρακάτω πίνακας συνοψίζει τις μετρήσεις απόδοσης.
| Εργασία σχολιασμού | mAP_50 (%) | Κόστος εκπαίδευσης ($) | Κόστος συμπερασμάτων ($) | Χρόνος συμπερασμάτων |
| Κουτί οριοθέτησης κεφαλιού | 94.9 | 4 | 22 | 5.5 ώρες |
| Βασικά σημεία | 98.4 | 27 | 10 | 5 λεπτά |
Επιπλέον, η λύση μας παρέχει δυνατότητα επαναχρησιμοποίησης για παρόμοιες εργασίες. Οι εξελίξεις στην αντίληψη της κάμερας για άλλα συστήματα, όπως το προηγμένο σύστημα υποβοήθησης οδηγού (ADAS) και τα συστήματα στην καμπίνα, μπορούν επίσης να υιοθετήσουν τη λύση μας.
Χαρακτηριστικά
Σε αυτήν την ανάρτηση, δείξαμε πώς να δημιουργήσουμε έναν ενεργό αγωγό εκμάθησης για αυτόματο σχολιασμό εικόνων στην καμπίνα χρησιμοποιώντας υπηρεσίες AWS. Επιδεικνύουμε τη δύναμη της ML, η οποία σας δίνει τη δυνατότητα να αυτοματοποιήσετε και να επιταχύνετε τη διαδικασία σχολιασμού, καθώς και την ευελιξία του πλαισίου που χρησιμοποιεί μοντέλα που είτε υποστηρίζονται από υπηρεσίες AWS είτε προσαρμοσμένα στο SageMaker. Με το Amazon S3, το SageMaker, το Lambda και το SageMaker Ground Truth, μπορείτε να βελτιστοποιήσετε την αποθήκευση δεδομένων, τον σχολιασμό, την εκπαίδευση και την ανάπτυξη και να επιτύχετε επαναχρησιμοποίηση, ενώ μειώνετε σημαντικά το κόστος. Με την εφαρμογή αυτής της λύσης, οι αυτοκινητοβιομηχανίες μπορούν να γίνουν πιο ευέλικτες και οικονομικά αποδοτικές χρησιμοποιώντας προηγμένα αναλυτικά στοιχεία που βασίζονται σε ML, όπως ο αυτοματοποιημένος σχολιασμός εικόνας.
Ξεκινήστε σήμερα και ξεκλειδώστε τη δύναμη του Υπηρεσίες AWS και μηχανική εκμάθηση για τις θήκες χρήσης ανίχνευσης στην καμπίνα του αυτοκινήτου σας!
Σχετικά με τους Συγγραφείς
 Yanxiang Yu είναι Εφαρμοσμένος Επιστήμονας στο Amazon Generative AI Innovation Center. Με περισσότερα από 9 χρόνια εμπειρίας στην κατασκευή λύσεων τεχνητής νοημοσύνης και μηχανικής εκμάθησης για βιομηχανικές εφαρμογές, ειδικεύεται στη γενετική τεχνητή νοημοσύνη, την όραση υπολογιστών και τη μοντελοποίηση χρονοσειρών.
Yanxiang Yu είναι Εφαρμοσμένος Επιστήμονας στο Amazon Generative AI Innovation Center. Με περισσότερα από 9 χρόνια εμπειρίας στην κατασκευή λύσεων τεχνητής νοημοσύνης και μηχανικής εκμάθησης για βιομηχανικές εφαρμογές, ειδικεύεται στη γενετική τεχνητή νοημοσύνη, την όραση υπολογιστών και τη μοντελοποίηση χρονοσειρών.
 Τιάνγι Μάο είναι Εφαρμοσμένος Επιστήμονας στο AWS με έδρα την περιοχή του Σικάγο. Έχει 5+ χρόνια εμπειρίας στην κατασκευή λύσεων μηχανικής μάθησης και βαθιάς μάθησης και εστιάζει στην όραση υπολογιστών και την ενίσχυση της μάθησης με ανθρώπινες ανατροφοδοτήσεις. Του αρέσει να εργάζεται με πελάτες για να κατανοήσει τις προκλήσεις τους και να τις λύσει δημιουργώντας καινοτόμες λύσεις χρησιμοποιώντας υπηρεσίες AWS.
Τιάνγι Μάο είναι Εφαρμοσμένος Επιστήμονας στο AWS με έδρα την περιοχή του Σικάγο. Έχει 5+ χρόνια εμπειρίας στην κατασκευή λύσεων μηχανικής μάθησης και βαθιάς μάθησης και εστιάζει στην όραση υπολογιστών και την ενίσχυση της μάθησης με ανθρώπινες ανατροφοδοτήσεις. Του αρέσει να εργάζεται με πελάτες για να κατανοήσει τις προκλήσεις τους και να τις λύσει δημιουργώντας καινοτόμες λύσεις χρησιμοποιώντας υπηρεσίες AWS.
 Γιανρού Σιάο είναι Εφαρμοσμένος Επιστήμονας στο Amazon Generative AI Innovation Center, όπου κατασκευάζει λύσεις AI/ML για τα πραγματικά επιχειρηματικά προβλήματα των πελατών. Έχει εργαστεί σε πολλούς τομείς, όπως η μεταποίηση, η ενέργεια και η γεωργία. Ο Yanru απέκτησε το διδακτορικό του. στην Επιστήμη Υπολογιστών από το Old Dominion University.
Γιανρού Σιάο είναι Εφαρμοσμένος Επιστήμονας στο Amazon Generative AI Innovation Center, όπου κατασκευάζει λύσεις AI/ML για τα πραγματικά επιχειρηματικά προβλήματα των πελατών. Έχει εργαστεί σε πολλούς τομείς, όπως η μεταποίηση, η ενέργεια και η γεωργία. Ο Yanru απέκτησε το διδακτορικό του. στην Επιστήμη Υπολογιστών από το Old Dominion University.
 Πολ Τζορτζ είναι ένας ολοκληρωμένος ηγέτης προϊόντων με πάνω από 15 χρόνια εμπειρίας στις τεχνολογίες αυτοκινήτων. Είναι ικανός σε ηγετικές ομάδες διαχείρισης προϊόντων, στρατηγικής, Go-to-Market και μηχανικών συστημάτων. Έχει επωάσει και λανσάρει πολλά νέα προϊόντα αίσθησης και αντίληψης παγκοσμίως. Στην AWS, πρωτοστατεί στη στρατηγική και στην αγορά για φόρτους εργασίας αυτόνομων οχημάτων.
Πολ Τζορτζ είναι ένας ολοκληρωμένος ηγέτης προϊόντων με πάνω από 15 χρόνια εμπειρίας στις τεχνολογίες αυτοκινήτων. Είναι ικανός σε ηγετικές ομάδες διαχείρισης προϊόντων, στρατηγικής, Go-to-Market και μηχανικών συστημάτων. Έχει επωάσει και λανσάρει πολλά νέα προϊόντα αίσθησης και αντίληψης παγκοσμίως. Στην AWS, πρωτοστατεί στη στρατηγική και στην αγορά για φόρτους εργασίας αυτόνομων οχημάτων.
 Caroline Chung είναι διευθυντής μηχανικής στη Veoneer (που αποκτήθηκε από τη Magna International), έχει πάνω από 14 χρόνια εμπειρίας στην ανάπτυξη συστημάτων αίσθησης και αντίληψης. Επί του παρόντος ηγείται προγραμμάτων προ-ανάπτυξης ανίχνευσης εσωτερικών χώρων στη Magna International, διαχειριζόμενος μια ομάδα μηχανικών υπολογιστικής όρασης και επιστημόνων δεδομένων.
Caroline Chung είναι διευθυντής μηχανικής στη Veoneer (που αποκτήθηκε από τη Magna International), έχει πάνω από 14 χρόνια εμπειρίας στην ανάπτυξη συστημάτων αίσθησης και αντίληψης. Επί του παρόντος ηγείται προγραμμάτων προ-ανάπτυξης ανίχνευσης εσωτερικών χώρων στη Magna International, διαχειριζόμενος μια ομάδα μηχανικών υπολογιστικής όρασης και επιστημόνων δεδομένων.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/build-an-active-learning-pipeline-for-automatic-annotation-of-images-with-aws-services/

