Το ξεκλείδωμα ακριβών και διορατικών απαντήσεων από τεράστιες ποσότητες κειμένου είναι μια συναρπαστική δυνατότητα που ενεργοποιείται από μεγάλα γλωσσικά μοντέλα (LLM). Κατά τη δημιουργία εφαρμογών LLM, είναι συχνά απαραίτητο να συνδέεστε και να αναζητάτε εξωτερικές πηγές δεδομένων για να παρέχετε σχετικό πλαίσιο στο μοντέλο. Μια δημοφιλής προσέγγιση είναι η χρήση του Retrieval Augmented Generation (RAG) για τη δημιουργία συστημάτων Q&A που κατανοούν πολύπλοκες πληροφορίες και παρέχουν φυσικές απαντήσεις σε ερωτήματα. Το RAG επιτρέπει στα μοντέλα να αξιοποιούν τεράστιες βάσεις γνώσεων και να προσφέρουν διάλογο που μοιάζει με άνθρωπο για εφαρμογές όπως τα chatbot και οι βοηθοί εταιρικής αναζήτησης.
Σε αυτήν την ανάρτηση, εξερευνούμε πώς να αξιοποιήσουμε τη δύναμη του CallIndex, Llama 2-70B-Chat, να LangChain για τη δημιουργία ισχυρών εφαρμογών Q&A. Με αυτές τις τεχνολογίες αιχμής, μπορείτε να προσλαμβάνετε σώματα κειμένου, να ευρετηριάζετε την κριτική γνώση και να δημιουργείτε κείμενο που απαντά στις ερωτήσεις των χρηστών με ακρίβεια και σαφήνεια.
Llama 2-70B-Chat
Το Llama 2-70B-Chat είναι ένα ισχυρό LLM που ανταγωνίζεται κορυφαία μοντέλα. Είναι προεκπαιδευμένο σε δύο τρισεκατομμύρια διακριτικά κειμένου και προορίζεται από τη Meta να χρησιμοποιηθεί για βοήθεια συνομιλίας στους χρήστες. Τα δεδομένα προεκπαίδευσης προέρχονται από δημόσια διαθέσιμα δεδομένα και ολοκληρώνονται από τον Σεπτέμβριο του 2022 και τα δεδομένα λεπτομέρειας ολοκληρώνονται τον Ιούλιο του 2023. Για περισσότερες λεπτομέρειες σχετικά με τη διαδικασία εκπαίδευσης του μοντέλου, τα ζητήματα ασφάλειας, τα μαθήματα και τις προβλεπόμενες χρήσεις, ανατρέξτε στο έγγραφο Llama 2: Open Foundation και Fine-Tuned Chat Models. Τα μοντέλα Llama 2 είναι διαθέσιμα στο Amazon SageMaker JumpStart για γρήγορη και άμεση ανάπτυξη.
CallIndex
CallIndex είναι ένα πλαίσιο δεδομένων που επιτρέπει τη δημιουργία εφαρμογών LLM. Παρέχει εργαλεία που προσφέρουν συνδέσεις δεδομένων για την απορρόφηση των υπαρχόντων δεδομένων σας με διάφορες πηγές και μορφές (PDF, έγγραφα, API, SQL και άλλα). Είτε έχετε αποθηκευμένα δεδομένα σε βάσεις δεδομένων είτε σε αρχεία PDF, το LlamaIndex καθιστά εύκολη τη χρήση αυτών των δεδομένων για LLM. Όπως αποδεικνύουμε σε αυτήν την ανάρτηση, τα API του LlamaIndex κάνουν την πρόσβαση στα δεδομένα αβίαστη και σας δίνουν τη δυνατότητα να δημιουργήσετε ισχυρές προσαρμοσμένες εφαρμογές LLM και ροές εργασίας.
Εάν πειραματίζεστε και χτίζετε με LLM, πιθανότατα είστε εξοικειωμένοι με το LangChain, το οποίο προσφέρει ένα ισχυρό πλαίσιο, απλοποιώντας την ανάπτυξη και την ανάπτυξη εφαρμογών που υποστηρίζονται από LLM. Παρόμοια με το LangChain, το LlamaIndex προσφέρει μια σειρά εργαλείων, όπως συνδέσεις δεδομένων, ευρετήρια δεδομένων, μηχανές και πράκτορες δεδομένων, καθώς και ενσωματώσεις εφαρμογών όπως εργαλεία και παρατηρησιμότητα, ανίχνευση και αξιολόγηση. Το LlamaIndex εστιάζει στη γεφύρωση του χάσματος μεταξύ των δεδομένων και των ισχυρών LLM, βελτιστοποιώντας τις εργασίες δεδομένων με φιλικές προς το χρήστη λειτουργίες. Το LlamaIndex έχει σχεδιαστεί και βελτιστοποιηθεί ειδικά για τη δημιουργία εφαρμογών αναζήτησης και ανάκτησης, όπως το RAG, επειδή παρέχει μια απλή διεπαφή για την αναζήτηση LLM και την ανάκτηση σχετικών εγγράφων.
Επισκόπηση λύσεων
Σε αυτήν την ανάρτηση, δείχνουμε πώς να δημιουργήσετε μια εφαρμογή που βασίζεται σε RAG χρησιμοποιώντας το LlamaIndex και ένα LLM. Το παρακάτω διάγραμμα δείχνει την αρχιτεκτονική βήμα προς βήμα αυτής της λύσης που περιγράφεται στις ακόλουθες ενότητες.
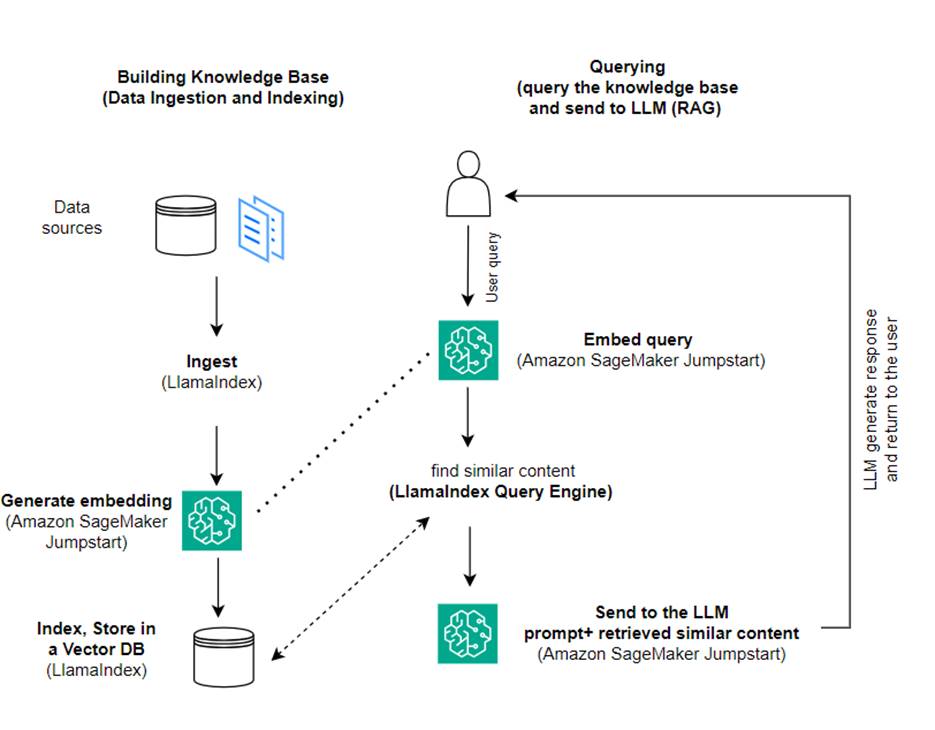
Το RAG συνδυάζει την ανάκτηση πληροφοριών με τη δημιουργία φυσικής γλώσσας για να παράγει πιο διορατικές απαντήσεις. Όταν σας ζητηθεί, το RAG αναζητά πρώτα τα σώματα κειμένου για να ανακτήσει τα πιο σχετικά παραδείγματα στην είσοδο. Κατά τη δημιουργία απόκρισης, το μοντέλο θεωρεί αυτά τα παραδείγματα για να αυξήσει τις δυνατότητές του. Με την ενσωμάτωση σχετικών ανακτημένων αποσπασμάτων, οι απαντήσεις RAG τείνουν να είναι πιο πραγματικές, συνεκτικές και συνεπείς με το πλαίσιο σε σύγκριση με βασικά μοντέλα παραγωγής. Αυτό το πλαίσιο δημιουργίας ανάκτησης εκμεταλλεύεται τα δυνατά σημεία τόσο της ανάκτησης όσο και της δημιουργίας, βοηθώντας στην αντιμετώπιση ζητημάτων όπως η επανάληψη και η έλλειψη πλαισίου που μπορεί να προκύψουν από αμιγώς αυτοπαλινδρομικά μοντέλα συνομιλίας. Το RAG εισάγει μια αποτελεσματική προσέγγιση για τη δημιουργία συνομιλητών και βοηθών τεχνητής νοημοσύνης με αποκρίσεις υψηλής ποιότητας με βάση τα συμφραζόμενα.
Η κατασκευή της λύσης αποτελείται από τα ακόλουθα βήματα:
- Ρύθμιση Στούντιο Amazon SageMaker ως περιβάλλον ανάπτυξης και να εγκαταστήσετε τις απαιτούμενες εξαρτήσεις.
- Αναπτύξτε ένα μοντέλο ενσωμάτωσης από τον κόμβο Amazon SageMaker JumpStart.
- Κατεβάστε δελτία τύπου για χρήση ως εξωτερική βάση γνώσεων.
- Δημιουργήστε ένα ευρετήριο από τα δελτία τύπου για να μπορείτε να κάνετε ερωτήσεις και να προσθέσετε ως πρόσθετο πλαίσιο στην προτροπή.
- Ζητήστε τη βάση γνώσεων.
- Δημιουργήστε μια εφαρμογή Q&A χρησιμοποιώντας πράκτορες LlamaIndex και LangChain.
Όλος ο κώδικας σε αυτήν την ανάρτηση είναι διαθέσιμος στο GitHub repo.
Προϋποθέσεις
Για αυτό το παράδειγμα, χρειάζεστε έναν λογαριασμό AWS με τομέα SageMaker και κατάλληλο Διαχείριση ταυτότητας και πρόσβασης AWS άδειες (IAM). Για οδηγίες ρύθμισης λογαριασμού, βλ Δημιουργήστε έναν λογαριασμό AWS. Εάν δεν διαθέτετε ήδη τομέα SageMaker, ανατρέξτε στο Τομέας Amazon SageMaker επισκόπηση για να δημιουργήσετε ένα. Σε αυτήν την ανάρτηση, χρησιμοποιούμε το AmazonSageMakerFullAccess ρόλος. Δεν συνιστάται η χρήση αυτού του διαπιστευτηρίου σε περιβάλλον παραγωγής. Αντίθετα, θα πρέπει να δημιουργήσετε και να χρησιμοποιήσετε έναν ρόλο με δικαιώματα ελάχιστων προνομίων. Μπορείτε επίσης να εξερευνήσετε πώς μπορείτε να χρησιμοποιήσετε Amazon SageMaker Role Manager για τη δημιουργία και τη διαχείριση ρόλων IAM που βασίζονται σε πρόσωπα για κοινές ανάγκες μηχανικής μάθησης απευθείας μέσω της κονσόλας SageMaker.
Επιπλέον, χρειάζεστε πρόσβαση σε ένα ελάχιστο από τα ακόλουθα μεγέθη εμφάνισης:
- ml.g5.2xμεγάλο για χρήση τελικού σημείου κατά την ανάπτυξη του Αγκαλιασμένο πρόσωπο GPT-J μοντέλο ενσωματώσεων κειμένου
- ml.g5.48xμεγάλο για χρήση τελικού σημείου κατά την ανάπτυξη του τελικού σημείου του μοντέλου Llama 2-Chat
Για να αυξήσετε το όριο σας, ανατρέξτε στο Αίτημα αύξησης ποσόστωσης.
Αναπτύξτε ένα μοντέλο ενσωμάτωσης GPT-J χρησιμοποιώντας το SageMaker JumpStart
Αυτή η ενότητα σάς παρέχει δύο επιλογές κατά την ανάπτυξη μοντέλων SageMaker JumpStart. Μπορείτε να χρησιμοποιήσετε μια ανάπτυξη που βασίζεται σε κώδικα χρησιμοποιώντας τον παρεχόμενο κώδικα ή να χρησιμοποιήσετε τη διεπαφή χρήστη (UI) του SageMaker JumpStart.
Αναπτύξτε με το SageMaker Python SDK
Μπορείτε να χρησιμοποιήσετε το SageMaker Python SDK για να αναπτύξετε τα LLM, όπως φαίνεται στο κωδικός διαθέσιμο στο αποθετήριο. Ολοκληρώστε τα παρακάτω βήματα:
- Ορίστε το μέγεθος του στιγμιότυπου που θα χρησιμοποιηθεί για την ανάπτυξη του μοντέλου ενσωματώσεων χρησιμοποιώντας
instance_type = "ml.g5.2xlarge" - Εντοπίστε το αναγνωριστικό του μοντέλου που θα χρησιμοποιηθεί για ενσωματώσεις. Στο SageMaker JumpStart, προσδιορίζεται ως
model_id = "huggingface-textembedding-gpt-j-6b-fp16" - Ανακτήστε το προεκπαιδευμένο κοντέινερ μοντέλου και αναπτύξτε το για συμπεράσματα.
Το SageMaker θα επιστρέψει το όνομα του τελικού σημείου του μοντέλου και το ακόλουθο μήνυμα όταν το μοντέλο ενσωματώσεων έχει αναπτυχθεί με επιτυχία:
Αναπτύξτε με το SageMaker JumpStart στο SageMaker Studio
Για να αναπτύξετε το μοντέλο χρησιμοποιώντας το SageMaker JumpStart στο Studio, ολοκληρώστε τα παρακάτω βήματα:
- Στην κονσόλα SageMaker Studio, επιλέξτε JumpStart στο παράθυρο πλοήγησης.

- Αναζητήστε και επιλέξτε το μοντέλο GPT-J 6B Embedding FP16.
- Επιλέξτε Ανάπτυξη και προσαρμόστε τη διαμόρφωση ανάπτυξης.

- Για αυτό το παράδειγμα, χρειαζόμαστε μια παρουσία ml.g5.2xlarge, η οποία είναι η προεπιλεγμένη παρουσία που προτείνεται από το SageMaker JumpStart.
- Επιλέξτε Ανάπτυξη ξανά για να δημιουργήσετε το τελικό σημείο.
Το τελικό σημείο θα χρειαστεί περίπου 5–10 λεπτά για να είναι σε λειτουργία.

Αφού αναπτύξετε το μοντέλο ενσωματώσεων, για να χρησιμοποιήσετε την ενσωμάτωση LangChain με τα API SageMaker, πρέπει να δημιουργήσετε μια συνάρτηση για το χειρισμό εισόδων (ακατέργαστο κείμενο) και τη μετατροπή τους σε ενσωματώσεις χρησιμοποιώντας το μοντέλο. Αυτό το κάνετε δημιουργώντας μια κλάση που ονομάζεται ContentHandler, το οποίο λαμβάνει ένα JSON δεδομένων εισόδου και επιστρέφει ένα JSON ενσωματώσεων κειμένου: class ContentHandler(EmbeddingsContentHandler).
Περάστε το όνομα του τελικού σημείου του μοντέλου στο ContentHandler λειτουργία μετατροπής κειμένου και επιστροφής ενσωματώσεων:
Μπορείτε να εντοπίσετε το όνομα του τελικού σημείου είτε στην έξοδο του SDK είτε στις λεπτομέρειες ανάπτυξης στο SageMaker JumpStart UI.
Μπορείτε να δοκιμάσετε ότι το ContentHandler η συνάρτηση και το τελικό σημείο λειτουργούν όπως αναμένεται, εισάγοντας κάποιο ακατέργαστο κείμενο και εκτελώντας το embeddings.embed_query(text) λειτουργία. Μπορείτε να χρησιμοποιήσετε το παράδειγμα που παρέχεται text = "Hi! It's time for the beach" ή δοκιμάστε το δικό σας κείμενο.
Αναπτύξτε και δοκιμάστε το Llama 2-Chat χρησιμοποιώντας το SageMaker JumpStart
Τώρα μπορείτε να αναπτύξετε το μοντέλο που μπορεί να έχει διαδραστικές συνομιλίες με τους χρήστες σας. Σε αυτήν την περίπτωση, επιλέγουμε ένα από τα μοντέλα Llama 2-chat, που προσδιορίζεται μέσω
Το μοντέλο πρέπει να αναπτυχθεί σε τελικό σημείο σε πραγματικό χρόνο χρησιμοποιώντας predictor = my_model.deploy(). Το SageMaker θα επιστρέψει το όνομα τελικού σημείου του μοντέλου, το οποίο μπορείτε να χρησιμοποιήσετε για το endpoint_name μεταβλητή για αναφορά αργότερα.
Ορίζεις α print_dialogue λειτουργία αποστολής εισόδου στο μοντέλο συνομιλίας και λήψης απόκρισης εξόδου του. Το ωφέλιμο φορτίο περιλαμβάνει υπερπαραμέτρους για το μοντέλο, συμπεριλαμβανομένων των εξής:
- max_new_tokens – Αναφέρεται στον μέγιστο αριθμό διακριτικών που μπορεί να δημιουργήσει το μοντέλο στις εξόδους του.
- top_p – Αναφέρεται στη αθροιστική πιθανότητα των διακριτικών που μπορούν να διατηρηθούν από το μοντέλο κατά τη δημιουργία των εξόδων του
- θερμοκρασία – Αναφέρεται στην τυχαιότητα των εξόδων που παράγονται από το μοντέλο. Μια θερμοκρασία μεγαλύτερη από 0 ή ίση με 1 αυξάνει το επίπεδο τυχαιότητας, ενώ μια θερμοκρασία 0 θα δημιουργήσει τα πιο πιθανά διακριτικά.
Θα πρέπει να επιλέξετε τις υπερπαραμέτρους σας με βάση την περίπτωση χρήσης σας και να τις δοκιμάσετε κατάλληλα. Μοντέλα όπως η οικογένεια Llama απαιτούν να συμπεριλάβετε μια πρόσθετη παράμετρο που υποδεικνύει ότι έχετε διαβάσει και αποδεχτεί την Άδεια Χρήσης Τελικού Χρήστη (EULA):
Για να δοκιμάσετε το μοντέλο, αντικαταστήστε την ενότητα περιεχομένου του ωφέλιμου φορτίου εισόδου: "content": "what is the recipe of mayonnaise?". Μπορείτε να χρησιμοποιήσετε τις δικές σας τιμές κειμένου και να ενημερώσετε τις υπερπαραμέτρους για να τις κατανοήσετε καλύτερα.
Παρόμοια με την ανάπτυξη του μοντέλου ενσωματώσεων, μπορείτε να αναπτύξετε το Llama-70B-Chat χρησιμοποιώντας το SageMaker JumpStart UI:
- Στην κονσόλα SageMaker Studio, επιλέξτε εκκίνηση με άλμα στο παράθυρο πλοήγησης
- Αναζητήστε και επιλέξτε το
Llama-2-70b-Chat model - Αποδεχτείτε την EULA και επιλέξτε Ανάπτυξη, χρησιμοποιώντας ξανά την προεπιλεγμένη παρουσία
Παρόμοια με το μοντέλο ενσωμάτωσης, μπορείτε να χρησιμοποιήσετε την ενσωμάτωση LangChain δημιουργώντας ένα πρότυπο χειριστή περιεχομένου για τις εισόδους και τις εξόδους του μοντέλου συνομιλίας σας. Σε αυτήν την περίπτωση, ορίζετε τις εισόδους ως αυτές που προέρχονται από έναν χρήστη και υποδεικνύετε ότι διέπονται από το system prompt. ο system prompt ενημερώνει το μοντέλο για τον ρόλο του στην παροχή βοήθειας στον χρήστη για μια συγκεκριμένη περίπτωση χρήσης.
Αυτός ο χειριστής περιεχομένου μεταβιβάζεται στη συνέχεια κατά την επίκληση του μοντέλου, επιπλέον των προαναφερθέντων υπερπαραμέτρων και προσαρμοσμένων χαρακτηριστικών (αποδοχή EULA). Αναλύετε όλα αυτά τα χαρακτηριστικά χρησιμοποιώντας τον ακόλουθο κώδικα:
Όταν το τελικό σημείο είναι διαθέσιμο, μπορείτε να ελέγξετε ότι λειτουργεί όπως αναμένεται. Μπορείτε να ενημερώσετε llm("what is amazon sagemaker?") με το δικό σου κείμενο. Πρέπει επίσης να ορίσετε το συγκεκριμένο ContentHandler για να καλέσετε το LLM χρησιμοποιώντας LangChain, όπως φαίνεται στο κωδικός και το ακόλουθο απόσπασμα κώδικα:
Χρησιμοποιήστε το LlamaIndex για να δημιουργήσετε το RAG
Για να συνεχίσετε, εγκαταστήστε το LlamaIndex για να δημιουργήσετε την εφαρμογή RAG. Μπορείτε να εγκαταστήσετε το LlamaIndex χρησιμοποιώντας το pip: pip install llama_index
Πρώτα πρέπει να φορτώσετε τα δεδομένα σας (γνωστική βάση) στο LlamaIndex για ευρετηρίαση. Αυτό περιλαμβάνει μερικά βήματα:
- Επιλέξτε ένα πρόγραμμα φόρτωσης δεδομένων:
Το LlamaIndex παρέχει έναν αριθμό υποδοχών δεδομένων που είναι διαθέσιμες σε LlamaHub για κοινούς τύπους δεδομένων όπως αρχεία JSON, CSV και κειμένου, καθώς και άλλες πηγές δεδομένων, που σας επιτρέπουν να απορροφάτε μια ποικιλία συνόλων δεδομένων. Σε αυτή την ανάρτηση, χρησιμοποιούμε SimpleDirectoryReader για να απορροφήσετε μερικά αρχεία PDF όπως φαίνεται στον κώδικα. Το δείγμα δεδομένων μας είναι δύο δελτία τύπου της Amazon σε έκδοση PDF στο Δελτία Τύπου φάκελο στο αποθετήριο κωδικών μας. Αφού φορτώσετε τα PDF, μπορείτε να δείτε ότι έχουν μετατραπεί σε μια λίστα 11 στοιχείων.
Αντί να φορτώνετε τα έγγραφα απευθείας, μπορείτε επίσης να τα κρύψετε Document αντικείμενο σε Node αντικείμενα πριν τα στείλετε στο ευρετήριο. Η επιλογή μεταξύ αποστολής ολόκληρου Document αντικείμενο στο ευρετήριο ή μετατροπή του Εγγράφου σε Node αντικείμενα πριν από την ευρετηρίαση εξαρτάται από τη συγκεκριμένη περίπτωση χρήσης και τη δομή των δεδομένων σας. Η προσέγγιση κόμβων είναι γενικά μια καλή επιλογή για μεγάλα έγγραφα, όπου θέλετε να σπάσετε και να ανακτήσετε συγκεκριμένα μέρη ενός εγγράφου και όχι ολόκληρο το έγγραφο. Για περισσότερες πληροφορίες, ανατρέξτε στο Έγγραφα / Κόμβοι.
- Δημιουργήστε το πρόγραμμα φόρτωσης και φορτώστε τα έγγραφα:
Αυτό το βήμα προετοιμάζει την κλάση φόρτωσης και οποιαδήποτε απαραίτητη ρύθμιση παραμέτρων, όπως εάν θα αγνοηθούν τα κρυφά αρχεία. Για περισσότερες λεπτομέρειες, ανατρέξτε στο SimpleDirectoryReader.
- Καλέστε τον φορτωτή
load_dataμέθοδος για να αναλύσετε τα αρχεία προέλευσης και τα δεδομένα σας και να τα μετατρέψετε σε αντικείμενα LlamaIndex Document, έτοιμα για ευρετηρίαση και αναζήτηση. Μπορείτε να χρησιμοποιήσετε τον ακόλουθο κώδικα για να ολοκληρώσετε την απορρόφηση δεδομένων και την προετοιμασία για αναζήτηση πλήρους κειμένου χρησιμοποιώντας τις δυνατότητες ευρετηρίασης και ανάκτησης του LlamaIndex:
- Δημιουργήστε το ευρετήριο:
Το βασικό χαρακτηριστικό του LlamaIndex είναι η ικανότητά του να δημιουργεί οργανωμένα ευρετήρια πάνω σε δεδομένα, τα οποία αναπαρίστανται ως έγγραφα ή κόμβοι. Η ευρετηρίαση διευκολύνει την αποτελεσματική αναζήτηση των δεδομένων. Δημιουργούμε το ευρετήριό μας με το προεπιλεγμένο διανυσματικό χώρο αποθήκευσης στη μνήμη και με την καθορισμένη διαμόρφωση ρυθμίσεων. Το LlamaIndex ρυθμίσεις είναι ένα αντικείμενο διαμόρφωσης που παρέχει πόρους και ρυθμίσεις που χρησιμοποιούνται συνήθως για λειτουργίες ευρετηρίου και αναζήτησης σε μια εφαρμογή LlamaIndex. Λειτουργεί ως αντικείμενο singleton, ώστε να σας επιτρέπει να ορίζετε καθολικές διαμορφώσεις, ενώ σας επιτρέπει επίσης να παρακάμπτετε συγκεκριμένα στοιχεία τοπικά περνώντας τα απευθείας στις διεπαφές (όπως LLM, ενσωμάτωση μοντέλων) που τα χρησιμοποιούν. Όταν ένα συγκεκριμένο στοιχείο δεν παρέχεται ρητά, το πλαίσιο LlamaIndex επιστρέφει στις ρυθμίσεις που ορίζονται στο Settings αντικείμενο ως καθολική προεπιλογή. Για να χρησιμοποιήσετε τα μοντέλα ενσωμάτωσης και LLM με το LangChain και να ρυθμίσετε το Settings πρέπει να εγκαταστήσουμε llama_index.embeddings.langchain και llama_index.llms.langchain. Μπορούμε να διαμορφώσουμε το Settings αντικείμενο όπως στον παρακάτω κώδικα:
Από προεπιλογή, VectorStoreIndex χρησιμοποιεί μια μνήμη SimpleVectorStore που έχει αρχικοποιηθεί ως μέρος του προεπιλεγμένου περιβάλλοντος αποθήκευσης. Σε περιπτώσεις πραγματικής χρήσης, συχνά χρειάζεται να συνδεθείτε σε εξωτερικά καταστήματα διανυσμάτων, όπως π.χ Amazon OpenSearch Service. Για περισσότερες λεπτομέρειες, ανατρέξτε στο Vector Engine για Amazon OpenSearch χωρίς διακομιστή.
Τώρα μπορείτε να εκτελέσετε Q&A πάνω από τα έγγραφά σας χρησιμοποιώντας το query_engine από το LlamaIndex. Για να το κάνετε αυτό, περάστε το ευρετήριο που δημιουργήσατε νωρίτερα για ερωτήματα και κάντε την ερώτησή σας. Η μηχανή ερωτημάτων είναι μια γενική διεπαφή για την αναζήτηση δεδομένων. Λαμβάνει ένα ερώτημα φυσικής γλώσσας ως είσοδο και επιστρέφει μια πλούσια απάντηση. Η μηχανή αναζήτησης είναι συνήθως κατασκευασμένη πάνω από ένα ή περισσότερα δείκτες χρησιμοποιώντας ριτρίβερ.
Μπορείτε να δείτε ότι η λύση RAG είναι σε θέση να ανακτήσει τη σωστή απάντηση από τα παρεχόμενα έγγραφα:
Χρησιμοποιήστε εργαλεία και πράκτορες LangChain
Loader τάξη. Ο φορτωτής έχει σχεδιαστεί για να φορτώνει δεδομένα στο LlamaIndex ή στη συνέχεια ως εργαλείο σε ένα Πράκτορας της LangChain. Αυτό σας δίνει περισσότερη δύναμη και ευελιξία για να το χρησιμοποιήσετε ως μέρος της εφαρμογής σας. Ξεκινάς ορίζοντας το δικό σου εργαλείο από την κατηγορία πρακτόρων LangChain. Η συνάρτηση που μεταβιβάζετε στο εργαλείο σας θέτει ερωτήματα στο ευρετήριο που δημιουργήσατε πάνω στα έγγραφά σας χρησιμοποιώντας το LlamaIndex.
Στη συνέχεια, επιλέγετε τον σωστό τύπο του πράκτορα που θα θέλατε να χρησιμοποιήσετε για την υλοποίηση του RAG. Σε αυτή την περίπτωση, χρησιμοποιείτε το chat-zero-shot-react-description μέσο. Με αυτόν τον πράκτορα, το LLM θα χρησιμοποιήσει το διαθέσιμο εργαλείο (σε αυτό το σενάριο, το RAG πάνω από τη βάση γνώσεων) για να παρέχει την απάντηση. Στη συνέχεια, αρχικοποιείτε τον πράκτορα περνώντας το εργαλείο, το LLM και τον τύπο πράκτορα:
Μπορείτε να δείτε τον πράκτορα να περνάει thoughts, actions, να observation , χρησιμοποιήστε το εργαλείο (σε αυτό το σενάριο, ερωτήματα για τα ευρετηριασμένα έγγραφά σας). και επιστρέψτε ένα αποτέλεσμα:
Μπορείτε να βρείτε τον κώδικα υλοποίησης από άκρο σε άκρο στο συνοδευτικό GitHub repo.
εκκαθάριση
Για να αποφύγετε περιττό κόστος, μπορείτε να καθαρίσετε τους πόρους σας, είτε μέσω των παρακάτω αποσπασμάτων κώδικα είτε μέσω του Amazon JumpStart UI.
Για να χρησιμοποιήσετε το Boto3 SDK, χρησιμοποιήστε τον ακόλουθο κώδικα για να διαγράψετε το τελικό σημείο του μοντέλου ενσωμάτωσης κειμένου και το τελικό σημείο του μοντέλου δημιουργίας κειμένου, καθώς και τις διαμορφώσεις τελικού σημείου:
Για να χρησιμοποιήσετε την κονσόλα SageMaker, ολοκληρώστε τα παρακάτω βήματα:
- Στην κονσόλα SageMaker, στην περιοχή Συμπερασματικά στο παράθυρο πλοήγησης, επιλέξτε Endpoints
- Αναζητήστε τα τελικά σημεία ενσωμάτωσης και δημιουργίας κειμένου.
- Στη σελίδα λεπτομερειών τελικού σημείου, επιλέξτε Διαγραφή.
- Επιλέξτε ξανά Διαγραφή για επιβεβαίωση.
Συμπέρασμα
Για περιπτώσεις χρήσης που επικεντρώνονται στην αναζήτηση και την ανάκτηση, το LlamaIndex παρέχει ευέλικτες δυνατότητες. Διαπρέπει στην ευρετηρίαση και την ανάκτηση για LLMs, καθιστώντας το ένα ισχυρό εργαλείο για τη βαθιά εξερεύνηση δεδομένων. Το LlamaIndex σάς δίνει τη δυνατότητα να δημιουργήσετε οργανωμένα ευρετήρια δεδομένων, να χρησιμοποιήσετε διαφορετικά LLM, να αυξήσετε τα δεδομένα για καλύτερη απόδοση LLM και να αναζητήσετε δεδομένα με φυσική γλώσσα.
Αυτή η ανάρτηση παρουσίασε ορισμένες βασικές έννοιες και δυνατότητες του LlamaIndex. Χρησιμοποιήσαμε το GPT-J για ενσωμάτωση και το Llama 2-Chat ως LLM για τη δημιουργία μιας εφαρμογής RAG, αλλά θα μπορούσατε να χρησιμοποιήσετε οποιοδήποτε κατάλληλο μοντέλο. Μπορείτε να εξερευνήσετε την ολοκληρωμένη γκάμα μοντέλων που είναι διαθέσιμα στο SageMaker JumpStart.
Δείξαμε επίσης πώς το LlamaIndex μπορεί να παρέχει ισχυρά, ευέλικτα εργαλεία για τη σύνδεση, την ευρετηρίαση, την ανάκτηση και την ενοποίηση δεδομένων με άλλα πλαίσια όπως το LangChain. Με τις ενσωματώσεις LlamaIndex και το LangChain, μπορείτε να δημιουργήσετε πιο ισχυρές, ευέλικτες και διορατικές εφαρμογές LLM.
Σχετικά με τους Συγγραφείς
 Δρ Romina Sharifpour είναι ανώτερος αρχιτέκτονας λύσεων μηχανικής μάθησης και τεχνητής νοημοσύνης στο Amazon Web Services (AWS). Έχει περάσει πάνω από 10 χρόνια ηγούμενη του σχεδιασμού και της εφαρμογής καινοτόμων λύσεων από άκρο σε άκρο που επιτρέπονται από τις εξελίξεις στον τομέα της ML και της τεχνητής νοημοσύνης. Οι τομείς ενδιαφέροντος της Romina είναι η επεξεργασία φυσικής γλώσσας, τα μεγάλα γλωσσικά μοντέλα και τα MLOps.
Δρ Romina Sharifpour είναι ανώτερος αρχιτέκτονας λύσεων μηχανικής μάθησης και τεχνητής νοημοσύνης στο Amazon Web Services (AWS). Έχει περάσει πάνω από 10 χρόνια ηγούμενη του σχεδιασμού και της εφαρμογής καινοτόμων λύσεων από άκρο σε άκρο που επιτρέπονται από τις εξελίξεις στον τομέα της ML και της τεχνητής νοημοσύνης. Οι τομείς ενδιαφέροντος της Romina είναι η επεξεργασία φυσικής γλώσσας, τα μεγάλα γλωσσικά μοντέλα και τα MLOps.
 Νικόλ Πίντο είναι Αρχιτέκτονας Specialist Solutions AI/ML με έδρα το Σίδνεϊ της Αυστραλίας. Το υπόβαθρό της στην υγειονομική περίθαλψη και τις χρηματοοικονομικές υπηρεσίες της δίνει μια μοναδική προοπτική στην επίλυση προβλημάτων πελατών. Είναι παθιασμένη με την παροχή δυνατοτήτων στους πελάτες μέσω της μηχανικής μάθησης και την ενδυνάμωση της επόμενης γενιάς γυναικών στο STEM.
Νικόλ Πίντο είναι Αρχιτέκτονας Specialist Solutions AI/ML με έδρα το Σίδνεϊ της Αυστραλίας. Το υπόβαθρό της στην υγειονομική περίθαλψη και τις χρηματοοικονομικές υπηρεσίες της δίνει μια μοναδική προοπτική στην επίλυση προβλημάτων πελατών. Είναι παθιασμένη με την παροχή δυνατοτήτων στους πελάτες μέσω της μηχανικής μάθησης και την ενδυνάμωση της επόμενης γενιάς γυναικών στο STEM.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/build-knowledge-powered-conversational-applications-using-llamaindex-and-llama-2-chat/

