Ο όγκος των δεδομένων που παράγονται παγκοσμίως συνεχίζει να αυξάνεται, από τα τυχερά παιχνίδια, το λιανικό εμπόριο και τη χρηματοδότηση, μέχρι την κατασκευή, την υγειονομική περίθαλψη και τα ταξίδια. Οι οργανισμοί αναζητούν περισσότερους τρόπους για να χρησιμοποιούν γρήγορα τη συνεχή εισροή δεδομένων για να καινοτομούν για τις επιχειρήσεις και τους πελάτες τους. Πρέπει να συλλάβουν, να επεξεργαστούν, να αναλύσουν και να φορτώσουν αξιόπιστα τα δεδομένα σε μια μυριάδα αποθηκών δεδομένων, όλα σε πραγματικό χρόνο.
Το Apache Kafka είναι μια δημοφιλής επιλογή για αυτές τις ανάγκες ροής σε πραγματικό χρόνο. Ωστόσο, μπορεί να είναι δύσκολο να δημιουργήσετε ένα σύμπλεγμα Kafka μαζί με άλλα στοιχεία επεξεργασίας δεδομένων που κλιμακώνονται αυτόματα ανάλογα με τις ανάγκες της εφαρμογής σας. Κινδυνεύετε να υποβάλετε σε ανεπάρκεια για την κυκλοφορία αιχμής, η οποία μπορεί να οδηγήσει σε διακοπές λειτουργίας ή υπερβολική πρόβλεψη για βασικό φορτίο, που οδηγεί σε σπατάλη. Το AWS προσφέρει πολλές υπηρεσίες χωρίς διακομιστή όπως Amazon Managed Streaming για το Apache Kafka (Amazon MSK), Amazon Data Firehose, Amazon DynamoDB, να AWS Lambda αυτή η κλίμακα αυτόματα ανάλογα με τις ανάγκες σας.
Σε αυτήν την ανάρτηση, εξηγούμε πώς μπορείτε να χρησιμοποιήσετε ορισμένες από αυτές τις υπηρεσίες, μεταξύ των οποίων MSK χωρίς διακομιστή, για να δημιουργήσετε μια πλατφόρμα δεδομένων χωρίς διακομιστή για να καλύψετε τις ανάγκες σας σε πραγματικό χρόνο.
Επισκόπηση λύσεων
Ας φανταστούμε ένα σενάριο. Είστε υπεύθυνοι για τη διαχείριση χιλιάδων μόντεμ για έναν πάροχο υπηρεσιών Διαδικτύου που αναπτύσσονται σε πολλές γεωγραφικές περιοχές. Θέλετε να παρακολουθείτε την ποιότητα συνδεσιμότητας του μόντεμ που έχει σημαντικό αντίκτυπο στην παραγωγικότητα και την ικανοποίηση των πελατών. Η ανάπτυξή σας περιλαμβάνει διαφορετικά μόντεμ που πρέπει να παρακολουθούνται και να συντηρούνται για να διασφαλίζεται ελάχιστος χρόνος διακοπής λειτουργίας. Κάθε συσκευή μεταδίδει χιλιάδες εγγραφές 1 KB κάθε δευτερόλεπτο, όπως χρήση CPU, χρήση μνήμης, συναγερμό και κατάσταση σύνδεσης. Θέλετε πρόσβαση σε πραγματικό χρόνο σε αυτά τα δεδομένα, ώστε να μπορείτε να παρακολουθείτε την απόδοση σε πραγματικό χρόνο και να εντοπίζετε και να μετριάζετε προβλήματα γρήγορα. Χρειάζεστε επίσης μακροπρόθεσμη πρόσβαση σε αυτά τα δεδομένα για μοντέλα μηχανικής εκμάθησης (ML) για την εκτέλεση προγνωστικών αξιολογήσεων συντήρησης, την εύρεση ευκαιριών βελτιστοποίησης και την πρόβλεψη ζήτησης.
Οι πελάτες σας που συλλέγουν τα δεδομένα στον ιστότοπο είναι γραμμένοι σε Python και μπορούν να στείλουν όλα τα δεδομένα ως θέματα Apache Kafka στο Amazon MSK. Για πρόσβαση σε δεδομένα χαμηλής καθυστέρησης και σε πραγματικό χρόνο της εφαρμογής σας, μπορείτε να χρησιμοποιήσετε Lambda και DynamoDB. Για μακροπρόθεσμη αποθήκευση δεδομένων, μπορείτε να χρησιμοποιήσετε διαχειριζόμενη υπηρεσία σύνδεσης χωρίς διακομιστή Amazon Data Firehose για να στείλετε δεδομένα στη λίμνη δεδομένων σας.
Το παρακάτω διάγραμμα δείχνει πώς μπορείτε να δημιουργήσετε αυτήν την εφαρμογή χωρίς διακομιστή από άκρο σε άκρο.
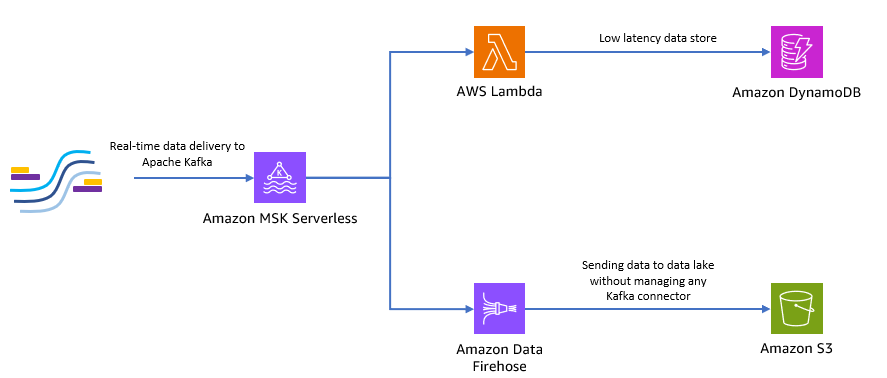
Ας ακολουθήσουμε τα βήματα στις ακόλουθες ενότητες για να εφαρμόσουμε αυτήν την αρχιτεκτονική.
Δημιουργήστε ένα σύμπλεγμα Kafka χωρίς διακομιστή στο Amazon MSK
Χρησιμοποιούμε το Amazon MSK για την απορρόφηση δεδομένων τηλεμετρίας σε πραγματικό χρόνο από μόντεμ. Η δημιουργία ενός συμπλέγματος Kafka χωρίς διακομιστή είναι απλή στο Amazon MSK. Χρειάζονται μόνο λίγα λεπτά χρησιμοποιώντας το Κονσόλα διαχείρισης AWS ή AWS SDK. Για να χρησιμοποιήσετε την κονσόλα, ανατρέξτε στο Ξεκινώντας με τη χρήση συμπλεγμάτων χωρίς διακομιστή MSK. Δημιουργείτε ένα σύμπλεγμα χωρίς διακομιστή, Διαχείριση ταυτότητας και πρόσβασης AWS ρόλος (IAM) και μηχανή πελάτη.
Δημιουργήστε ένα θέμα Kafka χρησιμοποιώντας Python
Όταν το σύμπλεγμα και ο υπολογιστής-πελάτης σας είναι έτοιμοι, SSH στον υπολογιστή-πελάτη σας και εγκαταστήστε το Kafka Python και τη βιβλιοθήκη MSK IAM για Python.
- Εκτελέστε τις παρακάτω εντολές για να εγκαταστήσετε το Kafka Python και το Βιβλιοθήκη MSK IAM:
- Δημιουργήστε ένα νέο αρχείο που ονομάζεται
createTopic.py. - Αντιγράψτε τον ακόλουθο κώδικα σε αυτό το αρχείο, αντικαθιστώντας το
bootstrap_serversκαιregionπληροφορίες με τις λεπτομέρειες για το σύμπλεγμα σας. Για οδηγίες σχετικά με την ανάκτηση τουbootstrap_serversπληροφορίες για το σύμπλεγμα MSK σας, βλ Λήψη των μεσιτών εκκίνησης για ένα σύμπλεγμα Amazon MSK.
- Εκτελέστε το
createTopic.pyσενάριο για τη δημιουργία ενός νέου θέματος Κάφκα που ονομάζεταιmytopicστο σύμπλεγμα χωρίς διακομιστή:
Δημιουργήστε εγγραφές χρησιμοποιώντας Python
Ας δημιουργήσουμε μερικά δείγματα δεδομένων τηλεμετρίας μόντεμ.
- Δημιουργήστε ένα νέο αρχείο που ονομάζεται
kafkaDataGen.py. - Αντιγράψτε τον ακόλουθο κώδικα σε αυτό το αρχείο, ενημερώνοντας το
BROKERSκαιregionπληροφορίες με τις λεπτομέρειες για το σύμπλεγμα σας:
- Εκτελέστε το
kafkaDataGen.pyγια να δημιουργεί συνεχώς τυχαία δεδομένα και να τα δημοσιεύει στο καθορισμένο θέμα Κάφκα:
Αποθηκεύστε εκδηλώσεις στο Amazon S3
Τώρα αποθηκεύετε όλα τα ανεπεξέργαστα δεδομένα συμβάντων σε ένα Απλή υπηρεσία αποθήκευσης Amazon (Amazon S3) λίμνη δεδομένων για αναλυτικά στοιχεία. Μπορείτε να χρησιμοποιήσετε τα ίδια δεδομένα για να εκπαιδεύσετε μοντέλα ML. ο ενσωμάτωση με το Amazon Data Firehose επιτρέπει στο Amazon MSK να φορτώνει απρόσκοπτα δεδομένα από τα συμπλέγματά σας Apache Kafka σε μια λίμνη δεδομένων S3. Ολοκληρώστε τα παρακάτω βήματα για τη συνεχή ροή δεδομένων από το Kafka στο Amazon S3, εξαλείφοντας την ανάγκη να δημιουργήσετε ή να διαχειριστείτε τις δικές σας εφαρμογές σύνδεσης:
- Στην κονσόλα Amazon S3, δημιουργήστε έναν νέο κάδο. Μπορείτε επίσης να χρησιμοποιήσετε έναν υπάρχοντα κάδο.
- Δημιουργήστε έναν νέο φάκελο στον κάδο S3 που ονομάζεται
streamingDataLake. - Στην κονσόλα Amazon MSK, επιλέξτε το σύμπλεγμα χωρίς διακομιστή MSK.
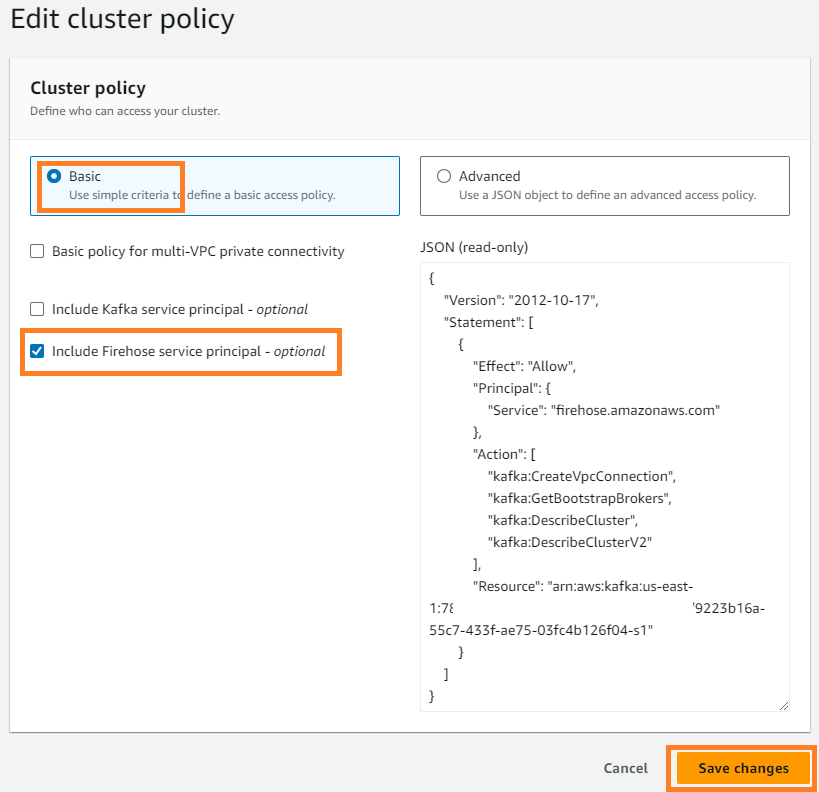
- Στις Δράσεις μενού, επιλέξτε Επεξεργασία πολιτικής συμπλέγματος.

- Αγορά Συμπεριλάβετε τον κύριο σέρβις της Firehose Και επιλέξτε Αποθηκεύστε τις αλλαγές.
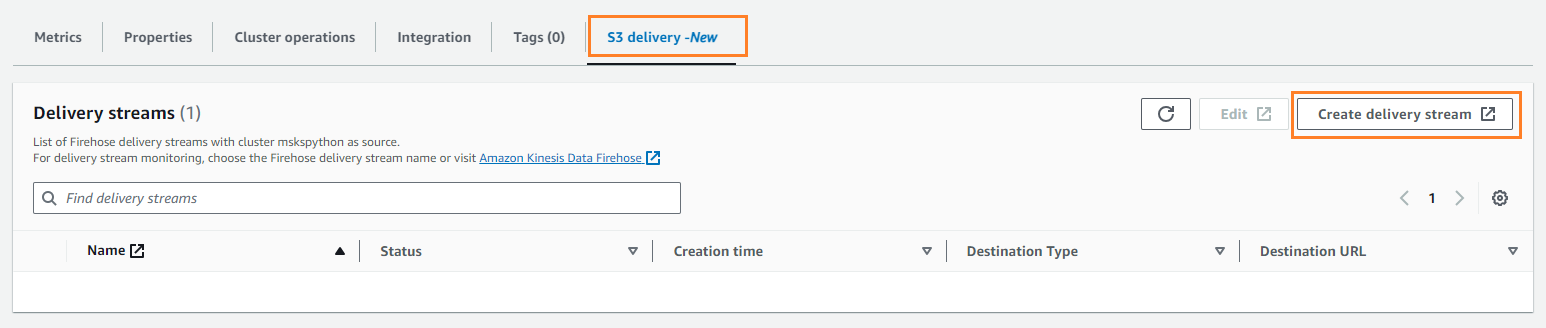
- Στις Παράδοση S3 καρτέλα, επιλέξτε Δημιουργία ροής παράδοσης.
- Για Πηγή, επιλέξτε Amazon MSK.
- Για Προορισμός, επιλέξτε Amazon S3.

- Για Συνδεσιμότητα συμπλέγματος Amazon MSK, Επιλέξτε Ιδιωτικοί μεσίτες bootstrap.
- Για Θέμα, πληκτρολογήστε ένα όνομα θέματος (για αυτήν την ανάρτηση,
mytopic).
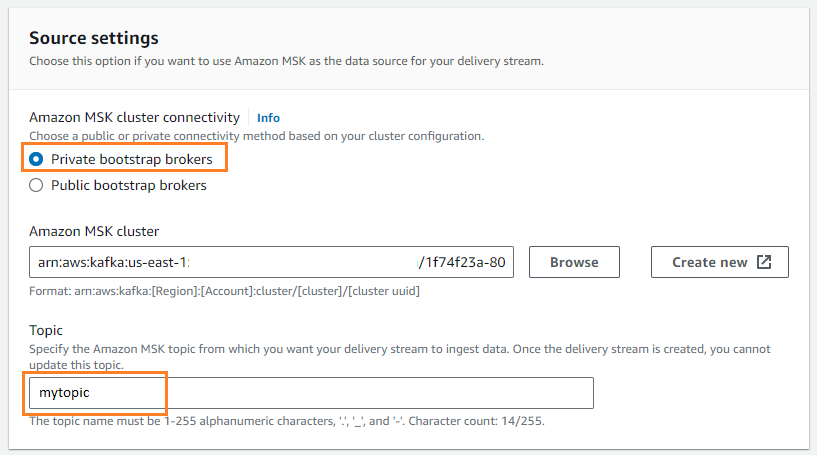
- Για Κάδος S3, επιλέξτε Αναζήτηση και επιλέξτε τον κάδο S3 σας.
- εισάγετε
streamingDataLakeως πρόθεμα κάδου S3. - εισάγετε
streamingDataLakeErrως πρόθεμα εξόδου σφάλματος κάδου S3.

- Επιλέξτε Δημιουργία ροής παράδοσης.
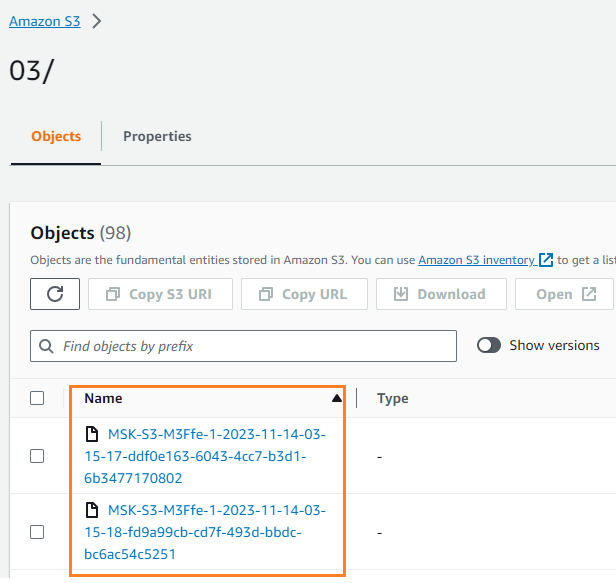
Μπορείτε να επαληθεύσετε ότι τα δεδομένα γράφτηκαν στον κάδο S3 σας. Θα πρέπει να δείτε ότι το streamingDataLake καταλόγου δημιουργήθηκε και τα αρχεία αποθηκεύονται σε κατατμήσεις.
Αποθηκεύστε συμβάντα στο DynamoDB
Για το τελευταίο βήμα, αποθηκεύετε τα πιο πρόσφατα δεδομένα μόντεμ στο DynamoDB. Αυτό επιτρέπει στην εφαρμογή πελάτη να έχει πρόσβαση στην κατάσταση του μόντεμ και να αλληλεπιδρά με το μόντεμ εξ αποστάσεως από οπουδήποτε, με χαμηλή καθυστέρηση και υψηλή διαθεσιμότητα. Το Lambda λειτουργεί άψογα με το Amazon MSK. Το Lambda εσωτερικά δημοσκοπεί για νέα μηνύματα από την πηγή συμβάντος και, στη συνέχεια, καλεί συγχρονισμένα τη συνάρτηση στόχο Lambda. Το Lambda διαβάζει τα μηνύματα σε παρτίδες και τα παρέχει στη λειτουργία σας ως ωφέλιμο φορτίο συμβάντων.
Ας δημιουργήσουμε πρώτα έναν πίνακα στο DynamoDB. Αναφέρομαι σε Δικαιώματα API DynamoDB: Αναφορά ενεργειών, πόρων και συνθηκών για να επαληθεύσετε ότι το μηχάνημα πελάτη σας διαθέτει τα απαραίτητα δικαιώματα.
- Δημιουργήστε ένα νέο αρχείο που ονομάζεται
createTable.py. - Αντιγράψτε τον παρακάτω κώδικα στο αρχείο, ενημερώνοντας το
regionπληροφορίες:
- Εκτελέστε το
createTable.pyscript για να δημιουργήσετε έναν πίνακα που ονομάζεταιdevice_statusστο DynamoDB:
Τώρα ας διαμορφώσουμε τη συνάρτηση Lambda.
- Στην κονσόλα Lambda, επιλέξτε Συναρτήσεις στο παράθυρο πλοήγησης.
- Επιλέξτε Δημιουργία λειτουργίας.
- Αγορά Συγγραφέας από το μηδέν.
- Για Όνομα λειτουργίας¸ εισαγάγετε ένα όνομα (για παράδειγμα,
my-notification-kafka). - Για Διάρκεια, επιλέξτε Python 3.11.
- Για Δικαιώματα, Επιλέξτε Χρησιμοποιήστε έναν υπάρχοντα ρόλο και επιλέξτε έναν ρόλο με δικαιώματα ανάγνωσης από το σύμπλεγμα σας.
- Δημιουργήστε τη συνάρτηση.
Στη σελίδα διαμόρφωσης της συνάρτησης Lambda, μπορείτε τώρα να διαμορφώσετε τις πηγές, τους προορισμούς και τον κώδικα της εφαρμογής σας.
- Επιλέξτε Προσθήκη σκανδάλης.
- Για Διαμόρφωση σκανδάλης, εισαγω
MSKγια να διαμορφώσετε το Amazon MSK ως έναυσμα για τη λειτουργία πηγής λάμδα. - Για Σύμπλεγμα MSK, εισαγω
myCluster. - Αποεπιλογή Ενεργοποίηση σκανδάλης, επειδή δεν έχετε διαμορφώσει ακόμα τη λειτουργία Lambda.
- Για Μέγεθος παρτίδας, εισαγω
100. - Για Θέση εκκίνησης, επιλέξτε Latest.
- Για Όνομα θέματος¸ εισαγάγετε ένα όνομα (για παράδειγμα,
mytopic). - Επιλέξτε Πρόσθεση.
- Στη σελίδα λεπτομερειών λειτουργίας Λάμδα, στο Κώδικας καρτέλα, εισαγάγετε τον ακόλουθο κωδικό:
- Αναπτύξτε τη λειτουργία Λάμδα.
- Στις διαμόρφωση καρτέλα, επιλέξτε Αλλαγή για να επεξεργαστείτε τη σκανδάλη.
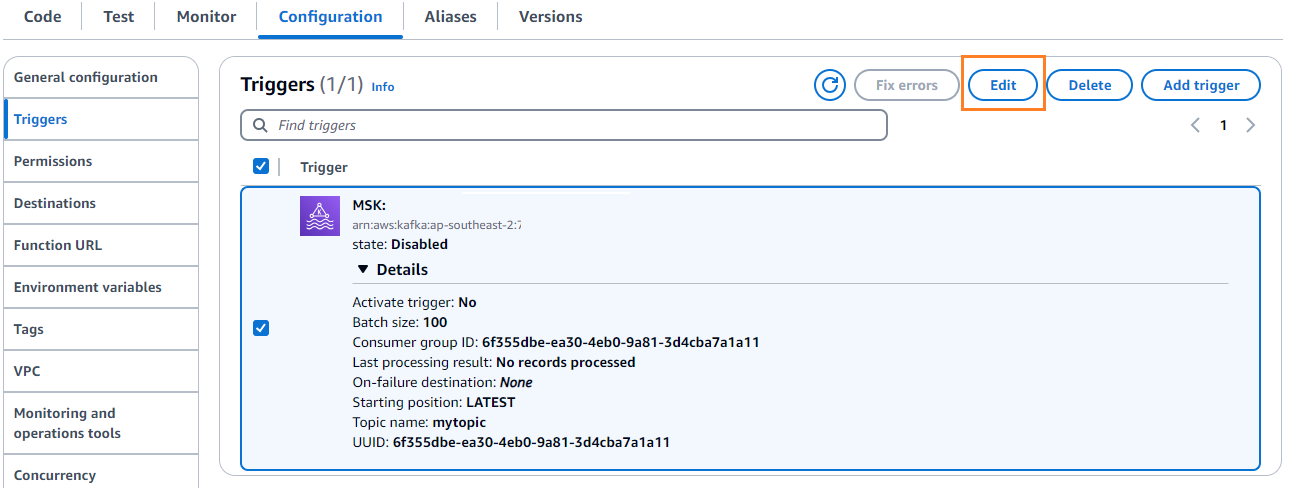
- Επιλέξτε το έναυσμα και μετά επιλέξτε Αποθήκευση.
- Στην κονσόλα DynamoDB, επιλέξτε Εξερευνήστε αντικείμενα στο παράθυρο πλοήγησης.
- Επιλέξτε τον πίνακα
device_status.
Θα δείτε το Lambda να γράφει συμβάντα που δημιουργούνται στο θέμα Kafka στο DynamoDB.

Χαρακτηριστικά
Οι αγωγοί ροής δεδομένων είναι κρίσιμοι για τη δημιουργία εφαρμογών σε πραγματικό χρόνο. Ωστόσο, η εγκατάσταση και η διαχείριση της υποδομής μπορεί να είναι αποθαρρυντική. Σε αυτήν την ανάρτηση, περιηγηθήκαμε στον τρόπο δημιουργίας ενός αγωγού ροής χωρίς διακομιστή στο AWS χρησιμοποιώντας Amazon MSK, Lambda, DynamoDB, Amazon Data Firehose και άλλες υπηρεσίες. Τα βασικά πλεονεκτήματα είναι η έλλειψη διακομιστών για διαχείριση, η αυτόματη επεκτασιμότητα της υποδομής και το μοντέλο πληρωμής που χρησιμοποιεί πλήρως διαχειριζόμενες υπηρεσίες.
Είστε έτοιμοι να φτιάξετε τον δικό σας αγωγό σε πραγματικό χρόνο; Ξεκινήστε σήμερα με έναν δωρεάν λογαριασμό AWS. Με τη δύναμη του serverless, μπορείτε να εστιάσετε στη λογική της εφαρμογής σας, ενώ το AWS χειρίζεται την αδιαφοροποίητη άρση βαρέων βαρών. Ας φτιάξουμε κάτι φοβερό στο AWS!
Σχετικά με τους Συγγραφείς
 Masudur Rahaman Sayem είναι αρχιτέκτονας δεδομένων ροής στην AWS. Συνεργάζεται με πελάτες της AWS παγκοσμίως για να σχεδιάσει και να δημιουργήσει αρχιτεκτονικές ροής δεδομένων για την επίλυση επιχειρηματικών προβλημάτων του πραγματικού κόσμου. Ειδικεύεται στη βελτιστοποίηση λύσεων που χρησιμοποιούν υπηρεσίες ροής δεδομένων και NoSQL. Ο Sayem είναι πολύ παθιασμένος με τους κατανεμημένους υπολογιστές.
Masudur Rahaman Sayem είναι αρχιτέκτονας δεδομένων ροής στην AWS. Συνεργάζεται με πελάτες της AWS παγκοσμίως για να σχεδιάσει και να δημιουργήσει αρχιτεκτονικές ροής δεδομένων για την επίλυση επιχειρηματικών προβλημάτων του πραγματικού κόσμου. Ειδικεύεται στη βελτιστοποίηση λύσεων που χρησιμοποιούν υπηρεσίες ροής δεδομένων και NoSQL. Ο Sayem είναι πολύ παθιασμένος με τους κατανεμημένους υπολογιστές.
 Michael Oguike είναι Υπεύθυνος Προϊόντων για το Amazon MSK. Είναι παθιασμένος με τη χρήση δεδομένων για να αποκαλύψει ιδέες που οδηγούν στη δράση. Του αρέσει να βοηθά πελάτες από ένα ευρύ φάσμα βιομηχανιών να βελτιώσουν τις επιχειρήσεις τους χρησιμοποιώντας ροή δεδομένων. Ο Michael λατρεύει επίσης να μαθαίνει για την επιστήμη της συμπεριφοράς και την ψυχολογία από βιβλία και podcast.
Michael Oguike είναι Υπεύθυνος Προϊόντων για το Amazon MSK. Είναι παθιασμένος με τη χρήση δεδομένων για να αποκαλύψει ιδέες που οδηγούν στη δράση. Του αρέσει να βοηθά πελάτες από ένα ευρύ φάσμα βιομηχανιών να βελτιώσουν τις επιχειρήσεις τους χρησιμοποιώντας ροή δεδομένων. Ο Michael λατρεύει επίσης να μαθαίνει για την επιστήμη της συμπεριφοράς και την ψυχολογία από βιβλία και podcast.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-serverless-streaming-pipeline-with-apache-kafka-on-amazon-msk-using-python/

