Εικόνα από συγγραφέα
Η χρήση αγωγών Scikit-learn μπορεί να απλοποιήσει τα βήματα προεπεξεργασίας και μοντελοποίησης, να μειώσει την πολυπλοκότητα του κώδικα, να εξασφαλίσει συνέπεια στην προεπεξεργασία δεδομένων, να βοηθήσει στον συντονισμό υπερπαραμέτρων και να κάνει τη ροή εργασίας σας πιο οργανωμένη και ευκολότερη στη συντήρηση. Ενσωματώνοντας πολλαπλούς μετασχηματισμούς και το τελικό μοντέλο σε μια ενιαία οντότητα, οι Pipelines ενισχύουν την αναπαραγωγιμότητα και κάνουν τα πάντα πιο αποτελεσματικά.
Σε αυτό το σεμινάριο, θα εργαστούμε με το Bank Churn σύνολο δεδομένων από το Kaggle για την εκπαίδευση ενός τυχαίου ταξινομητή δασών. Θα συγκρίνουμε τη συμβατική προσέγγιση της προεπεξεργασίας δεδομένων και της εκπαίδευσης μοντέλων με μια πιο αποτελεσματική μέθοδο χρησιμοποιώντας αγωγούς Scikit-learn και ColumnTransformers.
Στη γραμμή επεξεργασίας δεδομένων, θα μάθουμε πώς να μετασχηματίζουμε τις κατηγορίες και τις αριθμητικές στήλες ξεχωριστά. Θα ξεκινήσουμε με ένα παραδοσιακό στυλ κώδικα και στη συνέχεια θα δείξουμε έναν καλύτερο τρόπο εκτέλεσης παρόμοιας επεξεργασίας.
Αφού εξαγάγετε τα δεδομένα από το αρχείο zip, φορτώστε το αρχείο `train.csv` με το "id" ως στήλη ευρετηρίου. Αποθέστε τις περιττές στήλες και ανακατέψτε το σύνολο δεδομένων.
import pandas as pd
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(['CustomerId', 'Surname'], axis=1)
bank_df = bank_df.sample(frac=1)
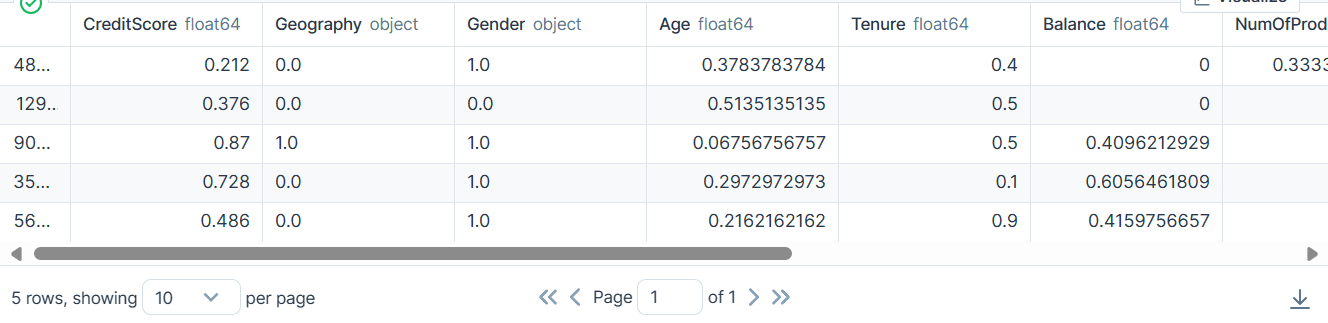
bank_df.head()
Έχουμε κατηγορικές, ακέραιες και κινητήριες στήλες. Το σύνολο δεδομένων φαίνεται αρκετά καθαρό.

Απλός κώδικας Scikit-learn
Ως επιστήμονας δεδομένων, έχω γράψει αυτόν τον κώδικα πολλές φορές. Στόχος μας είναι να συμπληρώσουμε τις τιμές που λείπουν τόσο για τα κατηγορικά όσο και για τα αριθμητικά χαρακτηριστικά. Για να το πετύχουμε αυτό, θα χρησιμοποιήσουμε ένα «SimpleImputer» με διαφορετικές στρατηγικές για κάθε τύπο δυνατότητας.
Αφού συμπληρωθούν οι τιμές που λείπουν, θα μετατρέψουμε τα κατηγορικά χαρακτηριστικά σε ακέραιους αριθμούς και θα εφαρμόσουμε κλίμακα ελάχιστης μέγιστης κλίμακας στα αριθμητικά χαρακτηριστικά.
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Filling missing categorical values
cat_impute = SimpleImputer(strategy="most_frequent")
bank_df.iloc[:,cat_col] = cat_impute.fit_transform(bank_df.iloc[:,cat_col])
# Filling missing numerical values
num_impute = SimpleImputer(strategy="median")
bank_df.iloc[:,num_col] = num_impute.fit_transform(bank_df.iloc[:,num_col])
# Encode categorical features as an integer array.
cat_encode = OrdinalEncoder()
bank_df.iloc[:,cat_col] = cat_encode.fit_transform(bank_df.iloc[:,cat_col])
# Scaling numerical values.
scaler = MinMaxScaler()
bank_df.iloc[:,num_col] = scaler.fit_transform(bank_df.iloc[:,num_col])
bank_df.head()
Ως αποτέλεσμα, λάβαμε ένα σύνολο δεδομένων που είναι καθαρό και μετασχηματισμένο με μόνο ακέραιες ή float τιμές.
Scikit-learn Code Pipelines
Ας μετατρέψουμε τον παραπάνω κώδικα χρησιμοποιώντας το "Pipeline" και το "ColumnTransformer". Αντί να εφαρμόσουμε την τεχνική προεπεξεργασίας, θα δημιουργήσουμε δύο αγωγούς. Το ένα είναι για αριθμητικές στήλες και το άλλο για στήλες κατηγοριών.
- Στον αριθμητικό αγωγό, χρησιμοποιήσαμε ένα απλό τεκμαρτό με στρατηγική «μέση» και εφαρμόσαμε έναν διαβαθμιστή ελάχιστης μέγιστης κλίμακας για κανονικοποίηση.
- Στη γραμμή κατηγοριών, χρησιμοποιήσαμε τον απλό υπολογισμό με τη στρατηγική «πιο_συχνό» και τον αρχικό κωδικοποιητή για να μετατρέψουμε τις κατηγορίες σε αριθμητικές τιμές.
Συνδυάσαμε τους δύο αγωγούς χρησιμοποιώντας το ColumnTransformer και δώσαμε σε καθεμία το ευρετήριο στηλών. Θα σας βοηθήσει να εφαρμόσετε αυτούς τους αγωγούς σε ορισμένες στήλες. Για παράδειγμα, ένας κατηγορικός αγωγός μετασχηματιστή θα εφαρμοστεί μόνο στις στήλες 1 και 2.
Σημείωση: το υπόλοιπο =”passthrough” σημαίνει ότι οι στήλες που δεν έχουν υποστεί επεξεργασία θα προστεθούν στο τέλος. Στην περίπτωσή μας, είναι η στήλη προορισμού.
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# Identify numerical and categorical columns
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Transformers for numerical data
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
])
# Transformers for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
])
# Combine transformers into a ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
],
remainder="passthrough"
)
# Apply the preprocessing pipeline
bank_df = preproc_pipe.fit_transform(bank_df)
bank_df[0]
Μετά τον μετασχηματισμό, ο πίνακας που προκύπτει περιέχει αριθμητική τιμή μετασχηματισμού στην αρχή και κατηγορική τιμή μετασχηματισμού στο τέλος, με βάση τη σειρά των αγωγών στον μετασχηματιστή στήλης.
array([0.712 , 0.24324324, 0.6 , 0. , 0.33333333,
1. , 1. , 0.76443485, 2. , 0. ,
0. ])
Μπορείτε να εκτελέσετε το αντικείμενο διοχέτευσης στο Σημειωματάριο Jupyter για να οπτικοποιήσετε τη σωλήνωση. Βεβαιωθείτε ότι έχετε την πιο πρόσφατη έκδοση του Scikit-learn.
preproc_pipe

Για να εκπαιδεύσουμε και να αξιολογήσουμε το μοντέλο μας, πρέπει να χωρίσουμε το σύνολο δεδομένων μας σε δύο υποσύνολα: εκπαίδευση και δοκιμή.
Για να γίνει αυτό, θα δημιουργήσουμε πρώτα εξαρτημένες και ανεξάρτητες μεταβλητές και θα τις μετατρέψουμε σε πίνακες NumPy. Στη συνέχεια, θα χρησιμοποιήσουμε τη συνάρτηση «train_test_split» για να χωρίσουμε το σύνολο δεδομένων σε δύο υποσύνολα.
from sklearn.model_selection import train_test_split
X = bank_df.drop("Exited", axis=1).values
y = bank_df.Exited.values
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)Απλός κώδικας Scikit-learn
Ο συμβατικός τρόπος σύνταξης κώδικα εκπαίδευσης είναι να εκτελέσετε πρώτα την επιλογή χαρακτηριστικών χρησιμοποιώντας το «SelectKBest» και στη συνέχεια να παρέχετε τη νέα δυνατότητα στο μοντέλο μας Random Forest Classifier.
Αρχικά θα εκπαιδεύσουμε το μοντέλο χρησιμοποιώντας το σετ εκπαίδευσης και θα αξιολογήσουμε τα αποτελέσματα χρησιμοποιώντας το σύνολο δεδομένων δοκιμής.
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
KBest = SelectKBest(chi2, k="all")
X_train = KBest.fit_transform(X_train, y_train)
X_test = KBest.transform(X_test)
model = RandomForestClassifier(n_estimators=100, random_state=125)
model.fit(X_train,y_train)
model.score(X_test, y_test)
Πετύχαμε μια αρκετά καλή βαθμολογία ακρίβειας.
0.8613035487063481Scikit-learn Code Pipelines
Ας χρησιμοποιήσουμε τη συνάρτηση «Pipeline» για να συνδυάσουμε και τα δύο βήματα εκπαίδευσης σε μια διοχέτευση. Στη συνέχεια, μπορούμε να προσαρμόσουμε το μοντέλο στο σετ εκπαίδευσης και να το αξιολογήσουμε στο σετ δοκιμών.
KBest = SelectKBest(chi2, k="all")
model = RandomForestClassifier(n_estimators=100, random_state=125)
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
train_pipe.fit(X_train,y_train)
train_pipe.score(X_test, y_test)
Πετύχαμε παρόμοια αποτελέσματα, αλλά ο κώδικας φαίνεται να είναι πιο αποτελεσματικός και απλός. Είναι πολύ εύκολο να προσθέσετε ή να αφαιρέσετε νέα βήματα από τη γραμμή εκπαίδευσης.
0.8613035487063481
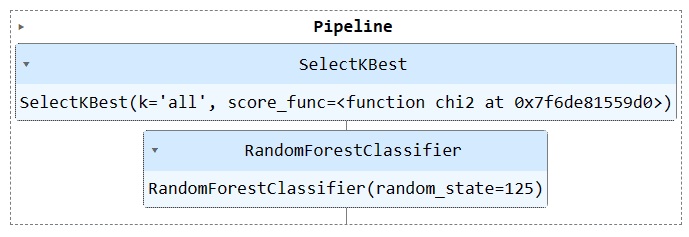
Εκτελέστε το αντικείμενο του αγωγού για να οπτικοποιήσετε τη σωλήνωση.
train_pipe
Τώρα, θα συνδυάσουμε τόσο την προεπεξεργασία όσο και τον αγωγό εκπαίδευσης δημιουργώντας έναν άλλο αγωγό και προσθέτοντας και τους δύο αγωγούς.
Εδώ είναι ο πλήρης κώδικας:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
#loading the data
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(['CustomerId', 'Surname'], axis=1)
bank_df = bank_df.sample(frac=1)
# Splitting data into training and testing sets
X = bank_df.drop(["Exited"],axis=1)
y = bank_df.Exited
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)
# Identify numerical and categorical columns
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Transformers for numerical data
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
])
# Transformers for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
])
# Combine pipelines using ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
],
remainder="passthrough"
)
# Selecting the best features
KBest = SelectKBest(chi2, k="all")
# Random Forest Classifier
model = RandomForestClassifier(n_estimators=100, random_state=125)
# KBest and model pipeline
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
# Combining the preprocessing and training pipelines
complete_pipe = Pipeline(
steps=[
("preprocessor", preproc_pipe),
("train", train_pipe),
]
)
# running the complete pipeline
complete_pipe.fit(X_train,y_train)
# model accuracy
complete_pipe.score(X_test, y_test)
Παραγωγή:
0.8592837955201874
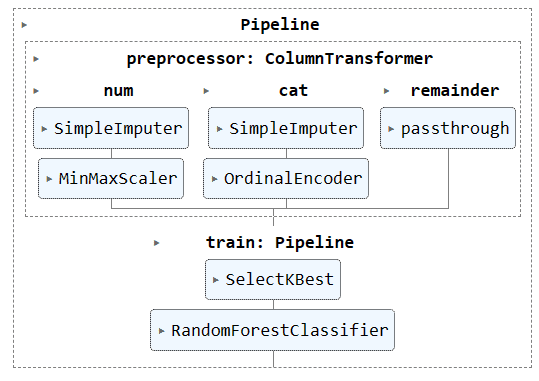
Οπτικοποίηση ολόκληρου του αγωγού.
complete_pipe

Ένα από τα σημαντικότερα πλεονεκτήματα της χρήσης αγωγών είναι ότι μπορείτε να αποθηκεύσετε τη σωλήνωση με το μοντέλο. Κατά την εξαγωγή συμπερασμάτων, χρειάζεται μόνο να φορτώσετε το αντικείμενο του αγωγού, το οποίο θα είναι έτοιμο να επεξεργαστεί τα πρωτογενή δεδομένα και να σας παρέχει ακριβείς προβλέψεις. Δεν χρειάζεται να ξαναγράψετε τις λειτουργίες επεξεργασίας και μετασχηματισμού στο αρχείο της εφαρμογής, καθώς θα λειτουργήσει εκτός του πλαισίου. Αυτό κάνει τη ροή εργασιών μηχανικής εκμάθησης πιο αποτελεσματική και εξοικονομεί χρόνο.
Ας αποθηκεύσουμε πρώτα τον αγωγό χρησιμοποιώντας το skops-dev/skops βιβλιοθήκη.
import skops.io as sio
sio.dump(complete_pipe, "bank_pipeline.skops")
Στη συνέχεια, φορτώστε τον αποθηκευμένο αγωγό και εμφανίστε τον αγωγό.
new_pipe = sio.load("bank_pipeline.skops", trusted=True)
new_pipe
Όπως μπορούμε να δούμε, φορτώσαμε με επιτυχία τον αγωγό.
Για να αξιολογήσουμε τον φορτωμένο αγωγό μας, θα κάνουμε προβλέψεις για το σετ δοκιμών και στη συνέχεια θα υπολογίσουμε την ακρίβεια και τις βαθμολογίες F1.
from sklearn.metrics import accuracy_score, f1_score
predictions = new_pipe.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
f1 = f1_score(y_test, predictions, average="macro")
print("Accuracy:", str(round(accuracy, 2) * 100) + "%", "F1:", round(f1, 2))
Αποδεικνύεται ότι πρέπει να επικεντρωθούμε στις μειονοτικές τάξεις για να βελτιώσουμε τη βαθμολογία μας στο f1.
Accuracy: 86.0% F1: 0.76
Τα αρχεία και ο κώδικας του έργου είναι διαθέσιμα στο Deepnote Workspace. Ο χώρος εργασίας έχει δύο Σημειωματάρια: Ένα με τη διοχέτευση Scikit-learn και ένα χωρίς αυτό.
Σε αυτό το σεμινάριο, μάθαμε πώς οι αγωγοί Scikit-learn μπορούν να βοηθήσουν στον εξορθολογισμό των ροών εργασιών μηχανικής μάθησης συνδέοντας αλληλουχίες μετασχηματισμών δεδομένων και μοντέλων. Συνδυάζοντας την προεπεξεργασία και την εκπαίδευση μοντέλων σε ένα ενιαίο αντικείμενο Pipeline, μπορούμε να απλοποιήσουμε τον κώδικα, να εξασφαλίσουμε συνεπείς μετασχηματισμούς δεδομένων και να κάνουμε τις ροές εργασίας μας πιο οργανωμένες και αναπαραγώγιμες.
Αμπίντ Αλί Αουάν (@1abidaliawan) είναι πιστοποιημένος επαγγελματίας επιστήμονας δεδομένων που λατρεύει την κατασκευή μοντέλων μηχανικής μάθησης. Επί του παρόντος, εστιάζει στη δημιουργία περιεχομένου και στη σύνταξη τεχνικών ιστολογίων για τη μηχανική μάθηση και τις τεχνολογίες επιστήμης δεδομένων. Ο Abid είναι κάτοχος μεταπτυχιακού τίτλου στη Διοίκηση Τεχνολογίας και πτυχίου στη Μηχανική Τηλεπικοινωνιών. Το όραμά του είναι να δημιουργήσει ένα προϊόν τεχνητής νοημοσύνης χρησιμοποιώντας ένα νευρωνικό δίκτυο γραφημάτων για μαθητές που παλεύουν με ψυχικές ασθένειες.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://www.kdnuggets.com/streamline-your-machine-learning-workflow-with-scikit-learn-pipelines?utm_source=rss&utm_medium=rss&utm_campaign=streamline-your-machine-learning-workflow-with-scikit-learn-pipelines

