Τα μοντέλα μεγάλων γλωσσών (LLM) εκπαιδεύονται γενικά σε μεγάλα δημόσια διαθέσιμα σύνολα δεδομένων που είναι αγνωστικιστικά στον τομέα. Για παράδειγμα, Ο Λάμα του Μέτα τα μοντέλα εκπαιδεύονται σε σύνολα δεδομένων όπως CommonCrawl, C4, Βικιπαίδεια και ArXiv. Αυτά τα σύνολα δεδομένων περιλαμβάνουν ένα ευρύ φάσμα θεμάτων και τομέων. Αν και τα μοντέλα που προκύπτουν αποδίδουν εκπληκτικά καλά αποτελέσματα για γενικές εργασίες, όπως η δημιουργία κειμένου και η αναγνώριση οντοτήτων, υπάρχουν ενδείξεις ότι τα μοντέλα που εκπαιδεύονται με σύνολα δεδομένων συγκεκριμένου τομέα μπορούν να βελτιώσουν περαιτέρω την απόδοση του LLM. Για παράδειγμα, τα δεδομένα εκπαίδευσης που χρησιμοποιούνται για BloombergGPT είναι 51% έγγραφα ειδικά για τον τομέα, συμπεριλαμβανομένων οικονομικών ειδήσεων, αρχειοθετήσεων και άλλων οικονομικών υλικών. Το προκύπτον LLM υπερέχει των LLM που έχουν εκπαιδευτεί σε σύνολα δεδομένων που δεν αφορούν συγκεκριμένους τομείς, όταν δοκιμάζονται σε εργασίες που αφορούν συγκεκριμένα οικονομικά. Οι συγγραφείς του BloombergGPT κατέληξαν στο συμπέρασμα ότι το μοντέλο τους υπερέχει όλων των άλλων μοντέλων που δοκιμάστηκαν για τέσσερις από τις πέντε χρηματοοικονομικές εργασίες. Το μοντέλο παρείχε ακόμη καλύτερες επιδόσεις όταν δοκιμάστηκε για τις εσωτερικές οικονομικές εργασίες του Bloomberg με μεγάλο περιθώριο - έως και 60 μονάδες καλύτερο (από 100). Αν και μπορείτε να μάθετε περισσότερα σχετικά με τα αποτελέσματα ολοκληρωμένης αξιολόγησης στο χαρτί, το ακόλουθο δείγμα ελήφθη από το BloombergGPT Το χαρτί μπορεί να σας δώσει μια γεύση από τα πλεονεκτήματα της εκπαίδευσης LLM χρησιμοποιώντας δεδομένα για συγκεκριμένο οικονομικό τομέα. Όπως φαίνεται στο παράδειγμα, το μοντέλο BloombergGPT παρείχε σωστές απαντήσεις ενώ άλλα μοντέλα που δεν ήταν συγκεκριμένα για τον τομέα δυσκολεύτηκαν:
Αυτή η ανάρτηση παρέχει έναν οδηγό για την εκπαίδευση LLM ειδικά για τον οικονομικό τομέα. Καλύπτουμε τους ακόλουθους βασικούς τομείς:
- Συλλογή και προετοιμασία δεδομένων – Καθοδήγηση σχετικά με την προμήθεια και την επιμέλεια σχετικών οικονομικών δεδομένων για αποτελεσματική εκπαίδευση μοντέλων
- Συνεχής προ-προπόνηση έναντι τελειοποίησης – Πότε να χρησιμοποιήσετε κάθε τεχνική για να βελτιστοποιήσετε την απόδοση του LLM σας
- Αποτελεσματική συνεχής προ-προπόνηση – Στρατηγικές για τον εξορθολογισμό της συνεχούς προεκπαιδευτικής διαδικασίας, εξοικονομώντας χρόνο και πόρους
Αυτή η ανάρτηση συγκεντρώνει την τεχνογνωσία της ερευνητικής ομάδας εφαρμοσμένης επιστήμης της Amazon Finance Technology και της ομάδας ειδικών AWS Worldwide για την Παγκόσμια Χρηματοοικονομική Βιομηχανία. Κάποιο από το περιεχόμενο βασίζεται στο χαρτί Αποτελεσματική συνεχής προεκπαίδευση για τη δημιουργία μοντέλων μεγάλων γλωσσών ειδικών τομέα.
Συλλογή και προετοιμασία χρηματοοικονομικών δεδομένων
Η συνεχής προεκπαίδευση τομέα απαιτεί ένα σύνολο δεδομένων μεγάλης κλίμακας, υψηλής ποιότητας, για συγκεκριμένο τομέα. Τα ακόλουθα είναι τα κύρια βήματα για την επιμέλεια δεδομένων τομέα:
- Προσδιορίστε τις πηγές δεδομένων – Οι πιθανές πηγές δεδομένων για το σώμα του τομέα περιλαμβάνουν τον ανοιχτό ιστό, τη Wikipedia, βιβλία, μέσα κοινωνικής δικτύωσης και εσωτερικά έγγραφα.
- Φίλτρα δεδομένων τομέα – Επειδή ο απώτερος στόχος είναι η επιμέλεια του σώματος τομέα, ίσως χρειαστεί να εφαρμόσετε πρόσθετα βήματα για να φιλτράρετε δείγματα που δεν σχετίζονται με τον τομέα-στόχο. Αυτό μειώνει τα άχρηστα σώματα για συνεχή προ-προπόνηση και μειώνει το κόστος εκπαίδευσης.
- Προεπεξεργασία – Μπορείτε να εξετάσετε μια σειρά βημάτων προεπεξεργασίας για να βελτιώσετε την ποιότητα των δεδομένων και την αποτελεσματικότητα της εκπαίδευσης. Για παράδειγμα, ορισμένες πηγές δεδομένων μπορεί να περιέχουν αρκετό αριθμό θορυβωδών διακριτικών. Το deduplication θεωρείται ένα χρήσιμο βήμα για τη βελτίωση της ποιότητας των δεδομένων και τη μείωση του κόστους εκπαίδευσης.
Για την ανάπτυξη οικονομικών LLM, μπορείτε να χρησιμοποιήσετε δύο σημαντικές πηγές δεδομένων: News CommonCrawl και αρχεία SEC. Η κατάθεση SEC είναι μια οικονομική κατάσταση ή άλλο επίσημο έγγραφο που υποβάλλεται στην Επιτροπή Κεφαλαιαγοράς των ΗΠΑ (SEC). Οι εισηγμένες εταιρείες υποχρεούνται να υποβάλλουν τακτικά διάφορα έγγραφα. Αυτό δημιουργεί μεγάλο αριθμό εγγράφων με τα χρόνια. Το News CommonCrawl είναι ένα σύνολο δεδομένων που κυκλοφόρησε από την CommonCrawl το 2016. Περιέχει ειδησεογραφικά άρθρα από ειδησεογραφικούς ιστότοπους σε όλο τον κόσμο.
Το News CommonCrawl είναι διαθέσιμο στις Απλή υπηρεσία αποθήκευσης Amazon (Amazon S3) στο commoncrawl κουβά στο crawl-data/CC-NEWS/. Μπορείτε να λάβετε τις λίστες των αρχείων χρησιμοποιώντας το Διεπαφή γραμμής εντολών AWS (AWS CLI) και την ακόλουθη εντολή:
In Αποτελεσματική συνεχής προεκπαίδευση για τη δημιουργία μοντέλων μεγάλων γλωσσών ειδικών τομέα, οι συγγραφείς χρησιμοποιούν μια προσέγγιση που βασίζεται σε URL και λέξεις-κλειδιά για να φιλτράρουν άρθρα οικονομικών ειδήσεων από γενικές ειδήσεις. Συγκεκριμένα, οι συγγραφείς διατηρούν μια λίστα με σημαντικά οικονομικά μέσα ενημέρωσης και ένα σύνολο λέξεων-κλειδιών που σχετίζονται με τα οικονομικά νέα. Εντοπίζουμε ένα άρθρο ως οικονομικές ειδήσεις εάν είτε προέρχεται από καταστήματα οικονομικών ειδήσεων είτε τυχόν λέξεις-κλειδιά εμφανίζονται στη διεύθυνση URL. Αυτή η απλή αλλά αποτελεσματική προσέγγιση σάς δίνει τη δυνατότητα να προσδιορίζετε οικονομικές ειδήσεις όχι μόνο από οικονομικές ειδήσεις αλλά και από τμήματα γενικών ειδήσεων.
Οι αρχειοθετήσεις SEC είναι διαθέσιμες στο διαδίκτυο μέσω της βάσης δεδομένων EDGAR (Ηλεκτρονική Συλλογή, Ανάλυση και Ανάκτηση Δεδομένων) της SEC, η οποία παρέχει ανοιχτή πρόσβαση σε δεδομένα. Μπορείτε να ξύσετε τα αρχεία από το EDGAR απευθείας ή να χρησιμοποιήσετε API Amazon Sage Maker με λίγες γραμμές κώδικα, για οποιαδήποτε χρονική περίοδο και για μεγάλο αριθμό σημείων (δηλαδή, το αναγνωριστικό που έχει εκχωρηθεί από την SEC). Για να μάθετε περισσότερα, ανατρέξτε στο Ανάκτηση αρχειοθέτησης SEC.
Ο παρακάτω πίνακας συνοψίζει τις βασικές λεπτομέρειες και των δύο πηγών δεδομένων.
| . | Ειδήσεις CommonCrawl | SEC αρχειοθέτηση |
| Κάλυψη | 2016-2022 | 1993-2022 |
| Μέγεθος | 25.8 δισεκατομμύρια λέξεις | 5.1 δισεκατομμύρια λέξεις |
Οι συγγραφείς περνούν από μερικά επιπλέον βήματα προεπεξεργασίας προτού τα δεδομένα τροφοδοτηθούν σε έναν αλγόριθμο εκπαίδευσης. Πρώτον, παρατηρούμε ότι τα αρχεία SEC περιέχουν θορυβώδες κείμενο λόγω της αφαίρεσης πινάκων και σχημάτων, επομένως οι συγγραφείς αφαιρούν σύντομες προτάσεις που θεωρούνται ετικέτες πινάκων ή σχημάτων. Δεύτερον, εφαρμόζουμε έναν αλγόριθμο κατακερματισμού ευαίσθητης τοποθεσίας για την κατάργηση των διπλότυπων των νέων άρθρων και αρχειοθετήσεων. Για αρχειοθετήσεις SEC, κάνουμε κατάργηση αντιγράφων σε επίπεδο ενότητας αντί για επίπεδο εγγράφου. Τέλος, συνενώνουμε έγγραφα σε μια μεγάλη συμβολοσειρά, την κάνουμε διακριτική και τεμαχίζουμε τη διακριτική σε κομμάτια μέγιστου μήκους εισόδου που υποστηρίζονται από το μοντέλο που πρόκειται να εκπαιδευτεί. Αυτό βελτιώνει την απόδοση της συνεχούς προ-προπόνησης και μειώνει το κόστος εκπαίδευσης.
Συνεχής προ-προπόνηση έναντι τελειοποίησης
Τα περισσότερα διαθέσιμα LLM είναι γενικού σκοπού και δεν διαθέτουν ειδικές ικανότητες για τον τομέα. Τα Domain LLMs έχουν δείξει σημαντικές επιδόσεις σε ιατρικούς, χρηματοοικονομικούς ή επιστημονικούς τομείς. Για να αποκτήσει ένα LLM γνώσεις για συγκεκριμένο τομέα, υπάρχουν τέσσερις μέθοδοι: εκπαίδευση από το μηδέν, συνεχής προ-εκπαίδευση, λεπτομερής ρύθμιση εντολών για εργασίες τομέα και Ανάκτηση Αυξημένης Γενιάς (RAG).
Στα παραδοσιακά μοντέλα, η λεπτομέρεια χρησιμοποιείται συνήθως για τη δημιουργία μοντέλων για συγκεκριμένες εργασίες για έναν τομέα. Αυτό σημαίνει διατήρηση πολλαπλών μοντέλων για πολλαπλές εργασίες όπως εξαγωγή οντοτήτων, ταξινόμηση προθέσεων, ανάλυση συναισθήματος ή απάντηση ερωτήσεων. Με την έλευση των LLM, η ανάγκη διατήρησης ξεχωριστών μοντέλων έχει καταστεί παρωχημένη με τη χρήση τεχνικών όπως η μάθηση εντός πλαισίου ή η προτροπή. Αυτό εξοικονομεί την προσπάθεια που απαιτείται για τη διατήρηση μιας στοίβας μοντέλων για σχετικές αλλά ξεχωριστές εργασίες.
Διαισθητικά, μπορείτε να εκπαιδεύσετε LLM από την αρχή με δεδομένα για συγκεκριμένο τομέα. Αν και το μεγαλύτερο μέρος της εργασίας για τη δημιουργία domain LLM έχει επικεντρωθεί στην εκπαίδευση από την αρχή, είναι απαγορευτικά δαπανηρή. Για παράδειγμα, το μοντέλο GPT-4 κοστίζει πάνω από $ 100 εκατομμύρια να εκπαιδεύσω. Αυτά τα μοντέλα εκπαιδεύονται σε έναν συνδυασμό δεδομένων ανοιχτού τομέα και δεδομένων τομέα. Η συνεχής προεκπαίδευση μπορεί να βοηθήσει τα μοντέλα να αποκτήσουν γνώσεις για συγκεκριμένο τομέα χωρίς να επιβαρυνθούν με το κόστος της προεκπαίδευσης από την αρχή, επειδή εκπαιδεύετε εκ των προτέρων ένα υπάρχον LLM ανοιχτού τομέα μόνο στα δεδομένα τομέα.
Με τη λεπτομερή ρύθμιση εντολών σε μια εργασία, δεν μπορείτε να κάνετε το μοντέλο να αποκτήσει γνώσεις τομέα, επειδή το LLM αποκτά μόνο πληροφορίες τομέα που περιέχονται στο σύνολο δεδομένων λεπτομέρειας εντολών. Αν δεν χρησιμοποιηθεί ένα πολύ μεγάλο σύνολο δεδομένων για την τελειοποίηση εντολών, δεν αρκεί η απόκτηση γνώσης τομέα. Η προμήθεια συνόλων δεδομένων οδηγιών υψηλής ποιότητας είναι συνήθως προκλητική και είναι ο λόγος για τη χρήση των LLM στην πρώτη θέση. Επίσης, η προσαρμογή εντολών σε μια εργασία μπορεί να επηρεάσει την απόδοση σε άλλες εργασίες (όπως φαίνεται στο αυτό το χαρτί). Ωστόσο, η τελειοποίηση των εντολών είναι πιο αποδοτική από πλευράς κόστους από οποιαδήποτε από τις εναλλακτικές λύσεις πριν από την εκπαίδευση.
Το παρακάτω σχήμα συγκρίνει την παραδοσιακή λεπτομέρεια για συγκεκριμένη εργασία. έναντι του παραδείγματος μάθησης εντός πλαισίου με LLMs.
 Το RAG είναι ο πιο αποτελεσματικός τρόπος καθοδήγησης ενός LLM για τη δημιουργία αποκρίσεων γειωμένων σε έναν τομέα. Παρόλο που μπορεί να καθοδηγήσει ένα μοντέλο για τη δημιουργία αποκρίσεων παρέχοντας γεγονότα από τον τομέα ως βοηθητικές πληροφορίες, δεν αποκτά τη γλώσσα του τομέα, επειδή το LLM εξακολουθεί να βασίζεται σε στυλ γλώσσας μη τομέα για τη δημιουργία των απαντήσεων.
Το RAG είναι ο πιο αποτελεσματικός τρόπος καθοδήγησης ενός LLM για τη δημιουργία αποκρίσεων γειωμένων σε έναν τομέα. Παρόλο που μπορεί να καθοδηγήσει ένα μοντέλο για τη δημιουργία αποκρίσεων παρέχοντας γεγονότα από τον τομέα ως βοηθητικές πληροφορίες, δεν αποκτά τη γλώσσα του τομέα, επειδή το LLM εξακολουθεί να βασίζεται σε στυλ γλώσσας μη τομέα για τη δημιουργία των απαντήσεων.
Η συνεχής προεκπαίδευση είναι η μέση λύση μεταξύ της προεκπαίδευσης και της τελειοποίησης των οδηγιών από άποψη κόστους, ενώ αποτελεί μια ισχυρή εναλλακτική λύση για την απόκτηση γνώσεων και στυλ για συγκεκριμένο τομέα. Μπορεί να παρέχει ένα γενικό μοντέλο πάνω στο οποίο μπορεί να πραγματοποιηθεί περαιτέρω λεπτομέρεια εντολών σε περιορισμένα δεδομένα εντολών. Η συνεχής προεκπαίδευση μπορεί να είναι μια οικονομικά αποδοτική στρατηγική για εξειδικευμένους τομείς όπου το σύνολο των εργασιών κατάντη είναι μεγάλο ή άγνωστο και τα δεδομένα συντονισμού εντολών με ετικέτα είναι περιορισμένα. Σε άλλα σενάρια, η τελειοποίηση εντολών ή το RAG μπορεί να είναι πιο κατάλληλο.
Για να μάθετε περισσότερα σχετικά με τη λεπτομερή ρύθμιση, το RAG και την εκπαίδευση μοντέλων, ανατρέξτε στο Βελτιώστε ένα μοντέλο θεμελίωσης, Ανάκτηση επαυξημένης γενιάς (RAG), να Εκπαιδεύστε ένα μοντέλο με το Amazon SageMaker, αντίστοιχα. Για αυτήν την ανάρτηση, εστιάζουμε στην αποτελεσματική συνεχή προ-προπόνηση.
Μεθοδολογία αποτελεσματικής συνεχούς προεκπαίδευσης
Η συνεχής προεκπαίδευση αποτελείται από την ακόλουθη μεθοδολογία:
- Συνεχής προεκπαίδευση με προσαρμογή τομέα (DACP) – Στο χαρτί Αποτελεσματική συνεχής προεκπαίδευση για τη δημιουργία μοντέλων μεγάλων γλωσσών ειδικών τομέα, οι συγγραφείς εκπαιδεύουν συνεχώς τη σουίτα γλωσσικών μοντέλων Pythia στο χρηματοοικονομικό σώμα για να την προσαρμόσουν στον χρηματοοικονομικό τομέα. Ο στόχος είναι η δημιουργία χρηματοοικονομικών LLM με την τροφοδότηση δεδομένων από ολόκληρο τον χρηματοοικονομικό τομέα σε ένα μοντέλο ανοιχτού κώδικα. Επειδή το σώμα εκπαίδευσης περιέχει όλα τα επιμελημένα σύνολα δεδομένων στον τομέα, το προκύπτον μοντέλο θα πρέπει να αποκτήσει γνώσεις σχετικά με τα οικονομικά, καθιστώντας έτσι ένα ευέλικτο μοντέλο για διάφορες χρηματοοικονομικές εργασίες. Αυτό έχει ως αποτέλεσμα μοντέλα FinPythia.
- Συνεχής Προεκπαίδευση με Προσαρμογή Εργασιών (TACP) – Οι συγγραφείς εκπαιδεύουν εκ των προτέρων τα μοντέλα περαιτέρω σε δεδομένα εργασιών με ετικέτα και χωρίς ετικέτα για να τα προσαρμόσουν για συγκεκριμένες εργασίες. Σε ορισμένες περιπτώσεις, οι προγραμματιστές μπορεί να προτιμούν μοντέλα που παρέχουν καλύτερη απόδοση σε μια ομάδα εργασιών εντός τομέα αντί για ένα γενικό μοντέλο τομέα. Το TACP έχει σχεδιαστεί ως συνεχής προεκπαίδευση με στόχο τη βελτίωση της απόδοσης σε στοχευμένες εργασίες, χωρίς απαιτήσεις για δεδομένα με ετικέτα. Συγκεκριμένα, οι συγγραφείς εκπαιδεύουν συνεχώς τα μοντέλα ανοιχτού κώδικα στα διακριτικά εργασιών (χωρίς ετικέτες). Ο πρωταρχικός περιορισμός του TACP έγκειται στην κατασκευή LLM ειδικά για εργασία αντί για θεμελιώδη LLM, λόγω της αποκλειστικής χρήσης δεδομένων εργασιών χωρίς ετικέτα για εκπαίδευση. Αν και το DACP χρησιμοποιεί ένα πολύ μεγαλύτερο σώμα, είναι απαγορευτικά ακριβό. Για να εξισορροπηθούν αυτοί οι περιορισμοί, οι συγγραφείς προτείνουν δύο προσεγγίσεις που στοχεύουν στη δημιουργία βασικών LLM για συγκεκριμένο τομέα διατηρώντας παράλληλα την ανώτερη απόδοση στις εργασίες-στόχους:
- Αποτελεσματικό DACP με παρόμοια εργασία (ETS-DACP) – Οι συγγραφείς προτείνουν την επιλογή ενός υποσυνόλου χρηματοοικονομικού σώματος που είναι πολύ παρόμοιο με τα δεδομένα εργασιών χρησιμοποιώντας ομοιότητα ενσωμάτωσης. Αυτό το υποσύνολο χρησιμοποιείται για συνεχή προ-προπόνηση για να γίνει πιο αποτελεσματικό. Συγκεκριμένα, οι συγγραφείς εκπαιδεύουν συνεχώς το LLM ανοιχτού κώδικα σε ένα μικρό σώμα που εξάγεται από το χρηματοοικονομικό σώμα που είναι κοντά στις στοχευόμενες εργασίες στη διανομή. Αυτό μπορεί να συμβάλει στη βελτίωση της απόδοσης των εργασιών, επειδή υιοθετούμε το μοντέλο για τη διανομή των διακριτικών εργασιών, παρόλο που δεν απαιτούνται δεδομένα με ετικέτα.
- Αποτελεσματικό Task-Agnostic DACP (ETA-DACP) – Οι συγγραφείς προτείνουν τη χρήση μετρήσεων όπως η αμηχανία και η εντροπία τύπου token που δεν απαιτούν δεδομένα εργασιών για την επιλογή δειγμάτων από το χρηματοοικονομικό σώμα για αποτελεσματική συνεχή προεκπαίδευση. Αυτή η προσέγγιση έχει σχεδιαστεί για να αντιμετωπίζει σενάρια όπου τα δεδομένα εργασιών δεν είναι διαθέσιμα ή προτιμώνται πιο ευέλικτα μοντέλα τομέα για τον ευρύτερο τομέα. Οι συγγραφείς υιοθετούν δύο διαστάσεις για να επιλέξουν δείγματα δεδομένων που είναι σημαντικά για τη λήψη πληροφοριών τομέα από ένα υποσύνολο δεδομένων τομέα πριν από την εκπαίδευση: καινοτομία και ποικιλομορφία. Η καινοτομία, που μετριέται με την αμηχανία που καταγράφηκε από το μοντέλο στόχου, αναφέρεται στις πληροφορίες που δεν είχαν δει προηγουμένως το LLM. Τα δεδομένα με υψηλή καινοτομία υποδεικνύουν νέες γνώσεις για το LLM και αυτά τα δεδομένα θεωρούνται πιο δύσκολα στην εκμάθηση. Αυτό ενημερώνει τα γενικά LLM με εντατική γνώση τομέα κατά τη διάρκεια της συνεχούς προεκπαίδευσης. Η διαφορετικότητα, από την άλλη πλευρά, καταγράφει την ποικιλομορφία των διανομών των τύπων διακριτικών στο σώμα του τομέα, η οποία έχει τεκμηριωθεί ως χρήσιμο χαρακτηριστικό στην έρευνα της μάθησης του προγράμματος σπουδών για τη μοντελοποίηση γλώσσας.
Το παρακάτω σχήμα συγκρίνει ένα παράδειγμα ETS-DACP (αριστερά) έναντι ETA-DACP (δεξιά).

Υιοθετούμε δύο σχήματα δειγματοληψίας για την ενεργή επιλογή σημείων δεδομένων από επιμελημένα χρηματοοικονομικά σώματα: σκληρή δειγματοληψία και ομαλή δειγματοληψία. Το πρώτο γίνεται κατατάσσοντας πρώτα το χρηματοοικονομικό σώμα με αντίστοιχες μετρήσεις και στη συνέχεια επιλέγοντας τα top-k δείγματα, όπου το k είναι προκαθορισμένο σύμφωνα με τον προϋπολογισμό εκπαίδευσης. Για το τελευταίο, οι συγγραφείς εκχωρούν βάρη δειγματοληψίας για κάθε σημείο δεδομένων σύμφωνα με τις μετρικές τιμές και, στη συνέχεια, δειγματίζουν τυχαία k σημεία δεδομένων για να καλύψουν τον προϋπολογισμό εκπαίδευσης.
Αποτέλεσμα και ανάλυση
Οι συγγραφείς αξιολογούν τα χρηματοοικονομικά LLM που προκύπτουν σε μια σειρά οικονομικών εργασιών για να διερευνήσουν την αποτελεσματικότητα της συνεχούς προεκπαίδευσης:
- Τράπεζα οικονομικών φράσεων – Μια εργασία ταξινόμησης συναισθημάτων στις οικονομικές ειδήσεις.
- FiQA Α.Ε – Μια εργασία ταξινόμησης συναισθημάτων που βασίζεται σε πτυχές και βασίζεται σε οικονομικές ειδήσεις και τίτλους.
- Επικεφαλίδα – Μια δυαδική εργασία ταξινόμησης σχετικά με το εάν ένας τίτλος σε μια οικονομική οντότητα περιέχει ορισμένες πληροφορίες.
- NER – Μια εργασία εξόρυξης οντότητας με χρηματοοικονομική επωνυμία που βασίζεται στην ενότητα αξιολόγησης πιστωτικού κινδύνου των εκθέσεων SEC. Οι λέξεις σε αυτήν την εργασία σχολιάζονται με PER, LOC, ORG και MISC.
Επειδή τα χρηματοοικονομικά LLM είναι τελειοποιημένα με τις οδηγίες, οι συγγραφείς αξιολογούν τα μοντέλα σε μια ρύθμιση 5 λήψεων για κάθε εργασία για λόγους ευρωστίας. Κατά μέσο όρο, το FinPythia 6.9B ξεπερνά το Pythia 6.9B κατά 10% σε τέσσερις εργασίες, γεγονός που καταδεικνύει την αποτελεσματικότητα της συνεχούς προεκπαίδευσης για συγκεκριμένο τομέα. Για το μοντέλο 1B, η βελτίωση είναι λιγότερο βαθιά, αλλά η απόδοση εξακολουθεί να βελτιώνεται κατά 2% κατά μέσο όρο.
Το παρακάτω σχήμα δείχνει τη διαφορά απόδοσης πριν και μετά το DACP και στα δύο μοντέλα.

Το παρακάτω σχήμα παρουσιάζει δύο ποιοτικά παραδείγματα που δημιουργήθηκαν από τα Pythia 6.9B και FinPythia 6.9B. Για δύο ερωτήσεις που σχετίζονται με τα οικονομικά σχετικά με έναν διαχειριστή επενδυτών και έναν χρηματοοικονομικό όρο, το Pythia 6.9B δεν κατανοεί τον όρο ούτε αναγνωρίζει το όνομα, ενώ το FinPythia 6.9B παράγει λεπτομερείς απαντήσεις σωστά. Τα ποιοτικά παραδείγματα καταδεικνύουν ότι η συνεχής προεκπαίδευση επιτρέπει στους LLMs να αποκτήσουν γνώσεις τομέα κατά τη διάρκεια της διαδικασίας.

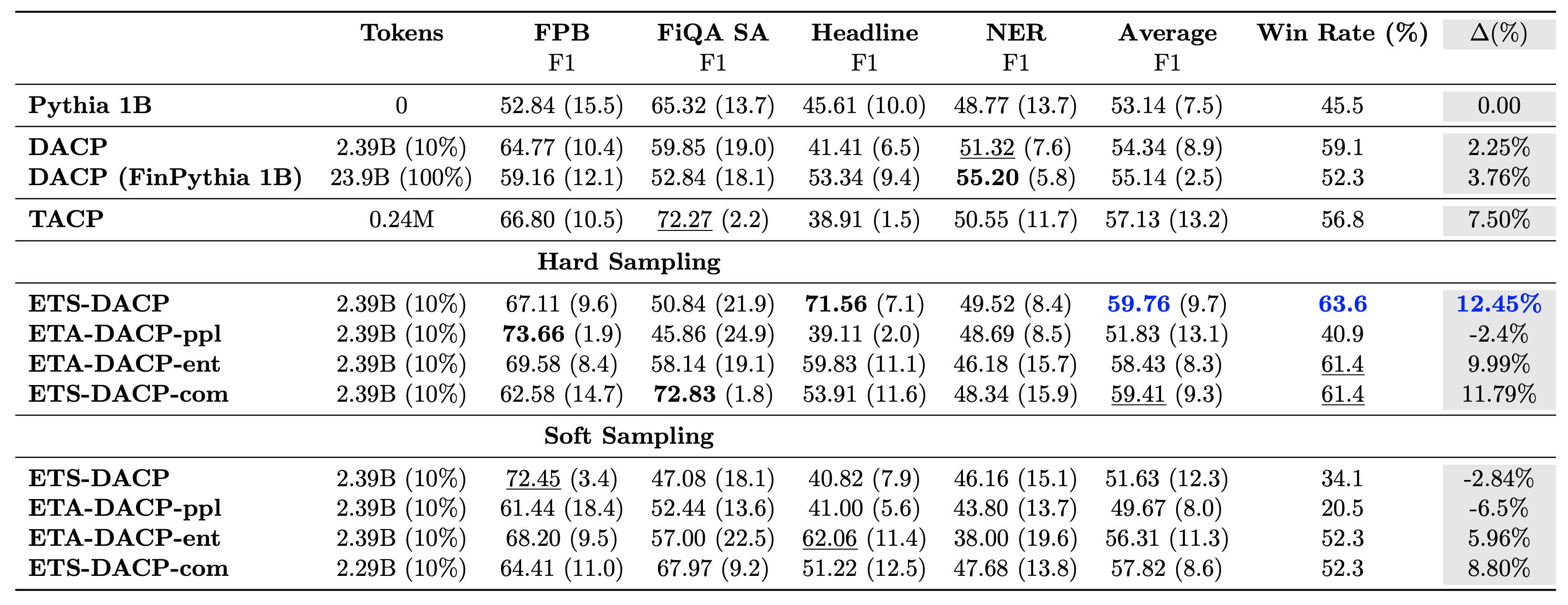
Ο παρακάτω πίνακας συγκρίνει διάφορες αποτελεσματικές προσεγγίσεις συνεχούς προ-προπόνησης. Το ETA-DACP-ppl είναι το ETA-DACP που βασίζεται στην αμηχανία (καινοτομία) και το ETA-DACP-ent βασίζεται στην εντροπία (διαφορετικότητα). Το ETS-DACP-com είναι παρόμοιο με το DACP με την επιλογή δεδομένων βάσει του μέσου όρου και των τριών μετρήσεων. Τα παρακάτω είναι μερικά στοιχεία από τα αποτελέσματα:
- Οι μέθοδοι επιλογής δεδομένων είναι αποτελεσματικές – Ξεπερνούν την τυπική συνεχή προ-προπόνηση με μόλις 10% των δεδομένων προπόνησης. Η αποτελεσματική συνεχής προεκπαίδευση, συμπεριλαμβανομένου του Task-Similar DACP (ETS-DACP), του Task-Agnostic DACP based on entropy (ESA-DACP-ent) και του Task-Similar DACP που βασίζεται και στις τρεις μετρήσεις (ETS-DACP-com) ξεπερνά το τυπικό DACP κατά μέσο όρο παρά το γεγονός ότι εκπαιδεύονται μόνο στο 10% του χρηματοοικονομικού σώματος.
- Η επιλογή δεδομένων με επίγνωση των εργασιών λειτουργεί καλύτερα σύμφωνα με την έρευνα για μικρά γλωσσικά μοντέλα – Το ETS-DACP καταγράφει την καλύτερη μέση απόδοση μεταξύ όλων των μεθόδων και, με βάση και τις τρεις μετρήσεις, καταγράφει τη δεύτερη καλύτερη απόδοση εργασιών. Αυτό υποδηλώνει ότι η χρήση δεδομένων εργασιών χωρίς ετικέτα εξακολουθεί να είναι μια αποτελεσματική προσέγγιση για την ενίσχυση της απόδοσης εργασιών στην περίπτωση των LLM.
- Η επιλογή Task-agnostic data είναι κοντά σε δεύτερη μοίρα – Το ESA-DACP-ent ακολουθεί την απόδοση της προσέγγισης επιλογής δεδομένων με επίγνωση εργασιών, υπονοώντας ότι θα μπορούσαμε ακόμα να ενισχύσουμε την απόδοση εργασιών επιλέγοντας ενεργά δείγματα υψηλής ποιότητας που δεν συνδέονται με συγκεκριμένες εργασίες. Αυτό ανοίγει το δρόμο για τη δημιουργία οικονομικών LLM για ολόκληρο τον τομέα, επιτυγχάνοντας παράλληλα ανώτερη απόδοση εργασιών.
Ένα κρίσιμο ερώτημα σχετικά με τη συνεχή προ-εκπαίδευση είναι εάν επηρεάζει αρνητικά την απόδοση σε εργασίες εκτός τομέα. Οι συγγραφείς αξιολογούν επίσης το συνεχώς προεκπαιδευμένο μοντέλο σε τέσσερις ευρέως χρησιμοποιούμενες γενικές εργασίες: ARC, MMLU, TruthQA και HellaSwag, που μετρούν την ικανότητα απάντησης ερωτήσεων, συλλογισμού και ολοκλήρωσης. Οι συγγραφείς διαπιστώνουν ότι η συνεχής προ-εκπαίδευση δεν επηρεάζει αρνητικά την απόδοση εκτός τομέα. Για περισσότερες λεπτομέρειες, ανατρέξτε στο Αποτελεσματική συνεχής προεκπαίδευση για τη δημιουργία μοντέλων μεγάλων γλωσσών ειδικών τομέα.
Συμπέρασμα
Αυτή η ανάρτηση πρόσφερε πληροφορίες σχετικά με τη συλλογή δεδομένων και τις στρατηγικές συνεχούς προεκπαίδευσης για την εκπαίδευση LLM για χρηματοοικονομικό τομέα. Μπορείτε να αρχίσετε να εκπαιδεύετε τα δικά σας LLM για οικονομικές εργασίες χρησιμοποιώντας Εκπαίδευση Amazon SageMaker or Θεμέλιο του Αμαζονίου σήμερα.
Σχετικά με τους Συγγραφείς
 Yong Xie είναι εφαρμοσμένος επιστήμονας στο Amazon FinTech. Επικεντρώνεται στην ανάπτυξη μεγάλων γλωσσικών μοντέλων και εφαρμογών Generative AI για χρηματοδότηση.
Yong Xie είναι εφαρμοσμένος επιστήμονας στο Amazon FinTech. Επικεντρώνεται στην ανάπτυξη μεγάλων γλωσσικών μοντέλων και εφαρμογών Generative AI για χρηματοδότηση.
 Karan Aggarwal είναι Ανώτερος Εφαρμοσμένος Επιστήμονας με το Amazon FinTech με εστίαση στο Generative AI για χρηματοοικονομικές χρήσεις. Ο Karan έχει εκτενή εμπειρία στην ανάλυση χρονοσειρών και στο NLP, με ιδιαίτερο ενδιαφέρον να μάθει από περιορισμένα δεδομένα με ετικέτα
Karan Aggarwal είναι Ανώτερος Εφαρμοσμένος Επιστήμονας με το Amazon FinTech με εστίαση στο Generative AI για χρηματοοικονομικές χρήσεις. Ο Karan έχει εκτενή εμπειρία στην ανάλυση χρονοσειρών και στο NLP, με ιδιαίτερο ενδιαφέρον να μάθει από περιορισμένα δεδομένα με ετικέτα
 Αϊτζάζ Αχμάντ είναι Διευθυντής Εφαρμοσμένης Επιστήμης στην Amazon όπου ηγείται μιας ομάδας επιστημόνων που κατασκευάζουν διάφορες εφαρμογές Μηχανικής Μάθησης και Δημιουργικής Τεχνητής Νοημοσύνης στα Οικονομικά. Τα ερευνητικά του ενδιαφέροντα είναι στους NLP, Generative AI και LLM Agents. Έλαβε το διδακτορικό του στον Ηλεκτρολόγο Μηχανικό από το Texas A&M University.
Αϊτζάζ Αχμάντ είναι Διευθυντής Εφαρμοσμένης Επιστήμης στην Amazon όπου ηγείται μιας ομάδας επιστημόνων που κατασκευάζουν διάφορες εφαρμογές Μηχανικής Μάθησης και Δημιουργικής Τεχνητής Νοημοσύνης στα Οικονομικά. Τα ερευνητικά του ενδιαφέροντα είναι στους NLP, Generative AI και LLM Agents. Έλαβε το διδακτορικό του στον Ηλεκτρολόγο Μηχανικό από το Texas A&M University.
 Κινγκγουέι Λι είναι ειδικός μηχανικής μάθησης στο Amazon Web Services. Έλαβε το διδακτορικό του. στην Επιχειρησιακή Έρευνα αφού έσπασε τον λογαριασμό της ερευνητικής επιχορήγησης του συμβούλου του και απέτυχε να παραδώσει το βραβείο Νόμπελ που υποσχέθηκε. Επί του παρόντος, βοηθά τους πελάτες στις χρηματοοικονομικές υπηρεσίες να δημιουργήσουν λύσεις μηχανικής εκμάθησης στο AWS.
Κινγκγουέι Λι είναι ειδικός μηχανικής μάθησης στο Amazon Web Services. Έλαβε το διδακτορικό του. στην Επιχειρησιακή Έρευνα αφού έσπασε τον λογαριασμό της ερευνητικής επιχορήγησης του συμβούλου του και απέτυχε να παραδώσει το βραβείο Νόμπελ που υποσχέθηκε. Επί του παρόντος, βοηθά τους πελάτες στις χρηματοοικονομικές υπηρεσίες να δημιουργήσουν λύσεις μηχανικής εκμάθησης στο AWS.
 Raghvender Arni ηγείται της Ομάδας Επιτάχυνσης Πελατών (CAT) εντός της AWS Industries. Η CAT είναι μια παγκόσμια διαλειτουργική ομάδα από αρχιτέκτονες cloud, μηχανικούς λογισμικού, επιστήμονες δεδομένων και ειδικούς και σχεδιαστές AI/ML που οδηγεί την καινοτομία μέσω προηγμένων πρωτοτύπων και οδηγεί στην επιχειρησιακή αριστεία του cloud μέσω εξειδικευμένης τεχνικής τεχνογνωσίας.
Raghvender Arni ηγείται της Ομάδας Επιτάχυνσης Πελατών (CAT) εντός της AWS Industries. Η CAT είναι μια παγκόσμια διαλειτουργική ομάδα από αρχιτέκτονες cloud, μηχανικούς λογισμικού, επιστήμονες δεδομένων και ειδικούς και σχεδιαστές AI/ML που οδηγεί την καινοτομία μέσω προηγμένων πρωτοτύπων και οδηγεί στην επιχειρησιακή αριστεία του cloud μέσω εξειδικευμένης τεχνικής τεχνογνωσίας.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

