Εισαγωγή
Στην όραση υπολογιστή, υπάρχουν διαφορετικές τεχνικές για την ανίχνευση ζωντανών αντικειμένων, συμπεριλαμβανομένου του Faster R-CNN, SSD, να YOLO. Κάθε τεχνική έχει τους περιορισμούς και τα πλεονεκτήματά της. Ενώ το ταχύτερο R-CNN μπορεί να υπερέχει σε ακρίβεια, μπορεί να μην αποδίδει το ίδιο καλά σε σενάρια σε πραγματικό χρόνο, προκαλώντας μια στροφή προς το Αλγόριθμος YOLO.
Η ανίχνευση αντικειμένων είναι θεμελιώδης στην όραση υπολογιστή, επιτρέποντας στις μηχανές να αναγνωρίζουν και να εντοπίζουν αντικείμενα μέσα σε ένα πλαίσιο ή οθόνη. Με τα χρόνια, έχουν αναπτυχθεί διάφοροι αλγόριθμοι ανίχνευσης αντικειμένων, με τον YOLO να αναδεικνύεται ως ένας από τους πιο επιτυχημένους. Πρόσφατα παρουσιάστηκε το YOLOv8, ενισχύοντας περαιτέρω τις δυνατότητες του αλγορίθμου.
Σε αυτόν τον περιεκτικό οδηγό, εξερευνούμε τρεις εξέχοντες αλγόριθμους ανίχνευσης αντικειμένων: Ταχύτερο R-CNN, SSD (Single Shot MultiBox Detector) και YOLOv8. Συζητάμε τις πρακτικές πτυχές της εφαρμογής αυτών των αλγορίθμων, συμπεριλαμβανομένης της δημιουργίας ενός εικονικού περιβάλλοντος και της ανάπτυξης μιας εφαρμογής Streamlit.
Στόχος της μάθησης
- Κατανοήστε το Faster R-CNN, το SSD και το YOLO και αναλύστε τις διαφορές μεταξύ τους.
- Αποκτήστε πρακτική εμπειρία στην εφαρμογή συστημάτων ανίχνευσης ζωντανών αντικειμένων χρησιμοποιώντας OpenCV, Supervision και YOLOv8.
- Κατανόηση του μοντέλου τμηματοποίησης εικόνας χρησιμοποιώντας τον σχολιασμό Roboflow.
- Δημιουργήστε μια εφαρμογή Streamlit για εύκολη διεπαφή χρήστη.
Ας εξερευνήσουμε πώς να κάνουμε τμηματοποίηση εικόνας με το YOLOv8!
Πίνακας περιεχομένων
Αυτό το άρθρο δημοσιεύθηκε ως μέρος του Data Science Blogathon.
Ταχύτερο R-CNN
Το Faster R-CNN (Faster Region-based Convolutional Neural Network) είναι ένας αλγόριθμος ανίχνευσης αντικειμένων που βασίζεται σε βαθιά μάθηση. Αξιολογείται χρησιμοποιώντας τα πλαίσια R-CNN και Fast R-CNN και μπορεί να θεωρηθεί επέκταση του Fast R-CNN.
Αυτός ο αλγόριθμος εισάγει το Δίκτυο Προτάσεων Περιοχής (RPN) για τη δημιουργία προτάσεων περιοχής, αντικαθιστώντας την επιλεκτική αναζήτηση που χρησιμοποιείται στο R-CNN. Το RPN μοιράζεται συνελικτικά επίπεδα με το δίκτυο ανίχνευσης, επιτρέποντας αποτελεσματική εκπαίδευση από άκρο σε άκρο.
Οι προτάσεις περιοχών που δημιουργούνται τροφοδοτούνται στη συνέχεια σε ένα δίκτυο Fast R-CNN για τελειοποίηση πλαισίων οριοθέτησης και ταξινόμηση αντικειμένων.
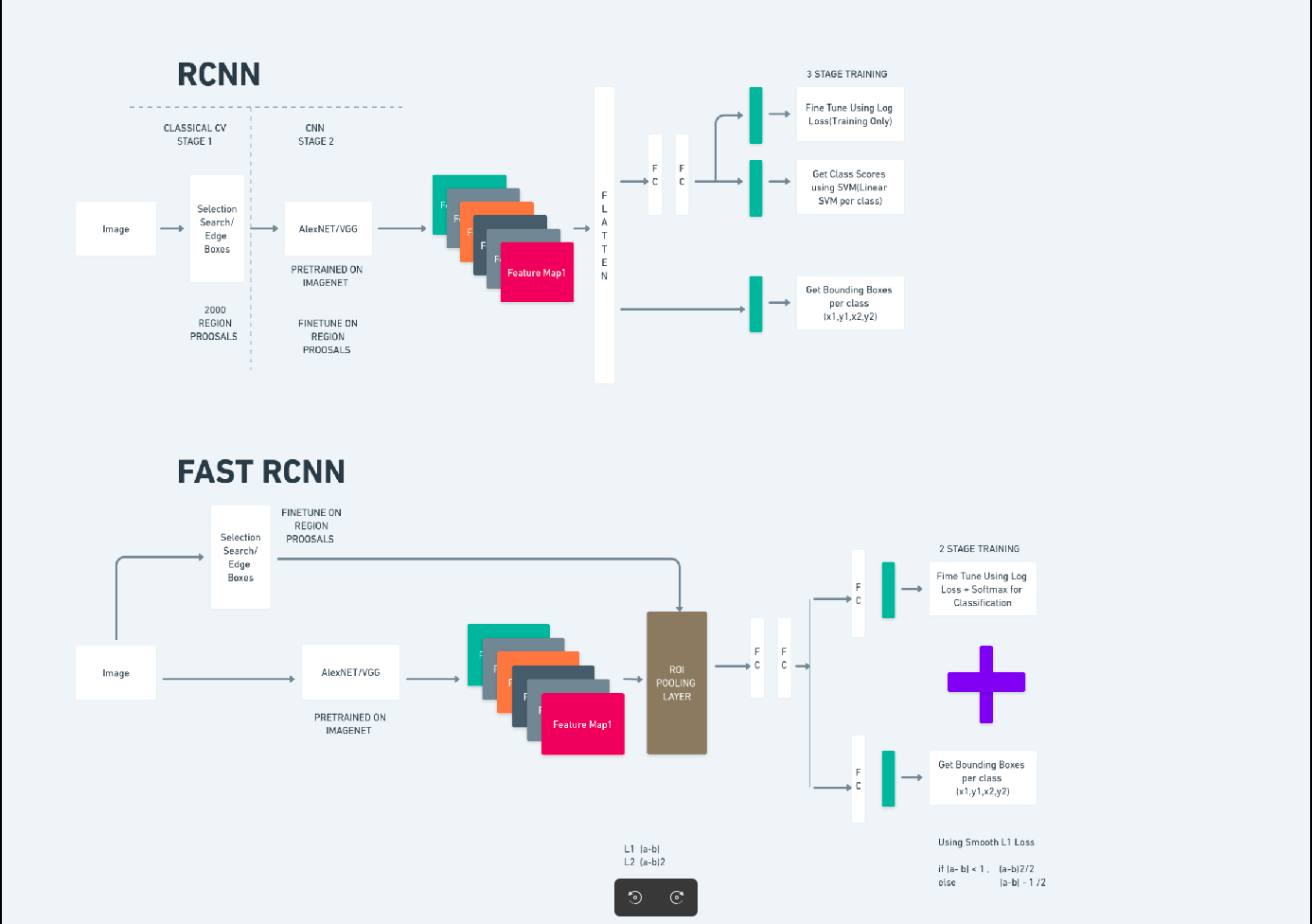
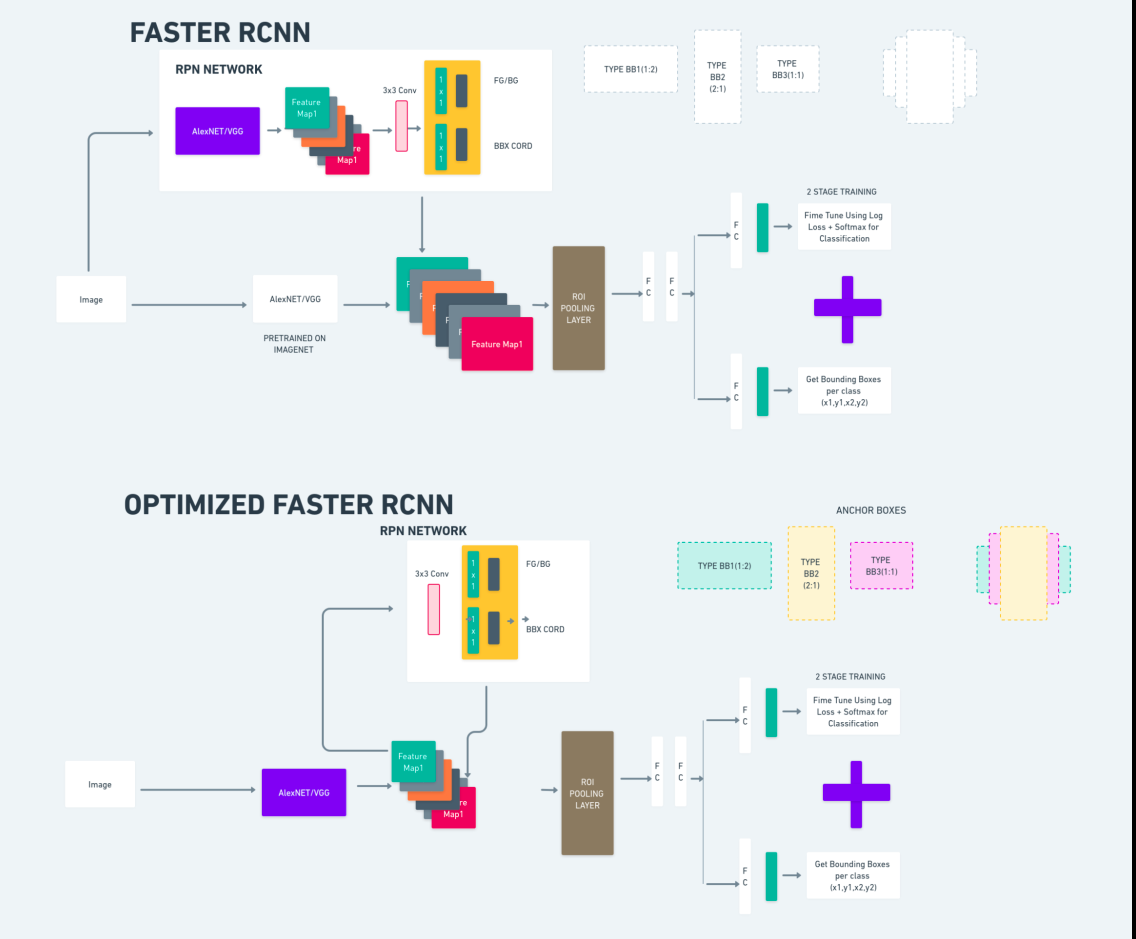
Το παραπάνω διάγραμμα απεικονίζει την οικογένεια Faster R-CNN ολοκληρωμένα και είναι εύκολο να γίνει κατανοητό για την αξιολόγηση κάθε αλγόριθμου.
Ανιχνευτής πολλαπλών κουτιών απλής λήψης (SSD)
Η Single Shot MultiBox Detector (SSD) είναι δημοφιλές στην ανίχνευση αντικειμένων και χρησιμοποιείται κυρίως σε εργασίες όρασης υπολογιστή. Στην προηγούμενη μέθοδο, Faster R-CNN, ακολουθήσαμε δύο βήματα: το πρώτο βήμα αφορούσε το τμήμα ανίχνευσης και το δεύτερο αφορούσε την παλινδρόμηση. Ωστόσο, με το SSD, εκτελούμε μόνο ένα βήμα ανίχνευσης. Ο SSD εισήχθη το 2016 για να αντιμετωπίσει την ανάγκη για ένα γρήγορο και ακριβές μοντέλο ανίχνευσης αντικειμένων.

Ο SSD έχει πολλά πλεονεκτήματα σε σχέση με παλαιότερες μεθόδους ανίχνευσης αντικειμένων όπως το Faster R-CNN:
- Αποδοτικότητα: Ο SSD είναι ένας ανιχνευτής ενός σταδίου, που σημαίνει ότι προβλέπει άμεσα οριοθέτηση πλαισίων και βαθμολογίες κλάσεων χωρίς να απαιτείται ξεχωριστό βήμα δημιουργίας πρότασης. Αυτό το κάνει πιο γρήγορο σε σύγκριση με ανιχνευτές δύο σταδίων όπως το Faster R-CNN.
- Εκπαίδευση από άκρο σε άκρο: Ο SSD μπορεί να εκπαιδευτεί από άκρο σε άκρο, βελτιστοποιώντας τόσο το βασικό δίκτυο όσο και την κεφαλή ανίχνευσης από κοινού, γεγονός που απλοποιεί τη διαδικασία εκπαίδευσης.
- Πολλαπλή κλίμακα Feature Fusion: Ο SSD λειτουργεί σε χάρτες χαρακτηριστικών σε πολλαπλές κλίμακες, επιτρέποντάς του να ανιχνεύει αντικείμενα διαφορετικών μεγεθών πιο αποτελεσματικά.
Ο SSD επιτυγχάνει μια καλή ισορροπία μεταξύ ταχύτητας και ακρίβειας, καθιστώντας τον κατάλληλο για εφαρμογές σε πραγματικό χρόνο όπου τόσο η απόδοση όσο και η αποδοτικότητα είναι κρίσιμες.
Κοιτάς μόνο μία φορά (YOLOv8)
Το 2015, το You Only Look Once (YOLO) εισήχθη ως αλγόριθμος ανίχνευσης αντικειμένων σε μια ερευνητική εργασία από τους Joseph Redmon, Santosh Divvala, Ross Girshick και Ali Farhadi. Ο YOLO είναι ένας αλγόριθμος απλής λήψης που ταξινομεί απευθείας ένα αντικείμενο σε ένα μόνο πέρασμα έχοντας μόνο ένα νευρωνικό δίκτυο να προβλέπει οριοθετημένα πλαίσια και πιθανότητες κλάσης χρησιμοποιώντας μια πλήρη εικόνα ως είσοδο.
Τώρα, ας κατανοήσουμε το YOLOv8 ως προηγμένες εξελίξεις στην ανίχνευση αντικειμένων σε πραγματικό χρόνο με βελτιωμένη ακρίβεια και ταχύτητα. Το YOLOv8 σάς επιτρέπει να αξιοποιήσετε προεκπαιδευμένα μοντέλα, τα οποία έχουν ήδη εκπαιδευτεί σε ένα τεράστιο σύνολο δεδομένων, όπως το COCO (Κοινά Αντικείμενα στο Πλαίσιο). Η κατάτμηση εικόνας παρέχει πληροφορίες σε επίπεδο pixel για κάθε αντικείμενο, επιτρέποντας πιο λεπτομερή ανάλυση και κατανόηση του περιεχομένου της εικόνας.
Ενώ η τμηματοποίηση εικόνας μπορεί να είναι υπολογιστικά ακριβή, το YOLOv8 ενσωματώνει αυτή τη μέθοδο στην αρχιτεκτονική του νευρωνικού δικτύου, επιτρέποντας την αποτελεσματική και ακριβή τμηματοποίηση αντικειμένων.
Αρχή εργασίας του YOLOv8
YOLOv8 λειτουργεί διαιρώντας πρώτα την εικόνα εισόδου σε κελιά πλέγματος. Χρησιμοποιώντας αυτά τα κελιά πλέγματος, το YOLOv8 προβλέπει τα οριοθετημένα πλαίσια (bbox) με πιθανότητες κλάσης.
Στη συνέχεια, το YOLOv8 χρησιμοποιεί τον αλγόριθμο NMS για να μειώσει την επικάλυψη. Για παράδειγμα, εάν υπάρχουν πολλά αυτοκίνητα στην εικόνα με αποτέλεσμα τα αλληλεπικαλυπτόμενα πλαίσια οριοθέτησης, ο αλγόριθμος NMS βοηθά στη μείωση αυτής της επικάλυψης.
Διαφορά μεταξύ των παραλλαγών του Yolo V8: Το YOLOv8 είναι διαθέσιμο σε τρεις παραλλαγές: YOLOv8, YOLOv8-L και YOLOv8-X. Η κύρια διαφορά μεταξύ των παραλλαγών είναι το μέγεθος του δικτύου κορμού. Το YOLOv8 έχει το μικρότερο δίκτυο κορμού, ενώ το YOLOv8-X το μεγαλύτερο δίκτυο κορμού.
Διαφορά μεταξύ πιο γρήγορου R-CNN, SSD και YOLO
| Άποψη | Ταχύτερο R-CNN | SSD | YOLO |
|---|---|---|---|
| Αρχιτεκτονική | Ανιχνευτής δύο σταδίων με RPN και Fast R-CNN | Ανιχνευτής ενός σταδίου | Ανιχνευτής ενός σταδίου |
| Περιφέρειες Προτάσεις | Ναι | Οχι | Οχι |
| Ταχύτητα ανίχνευσης | Πιο αργό σε σύγκριση με SSD και YOLO | Ταχύτερο σε σύγκριση με το Faster R-CNN, πιο αργό από το YOLO | Πολύ γρήγορα |
| Ακρίβεια | Γενικά υψηλότερη ακρίβεια | Ισορροπημένη ακρίβεια και ταχύτητα | Αξιοπρεπής ακρίβεια, ειδικά για εφαρμογές σε πραγματικό χρόνο |
| Ευελιξία | Ευέλικτο, μπορεί να χειριστεί διάφορα μεγέθη αντικειμένων και αναλογίες διαστάσεων | Μπορεί να χειριστεί πολλαπλές κλίμακες αντικειμένων | Μπορεί να αντιμετωπίσει τον ακριβή εντοπισμό μικρών αντικειμένων |
| Ενοποιημένη ανίχνευση | Οχι | Οχι | Ναι |
| Ανταλλαγή ταχύτητας έναντι ακρίβειας | Γενικά θυσιάζει την ταχύτητα για την ακρίβεια | Εξισορροπεί την ταχύτητα και την ακρίβεια | Δίνει προτεραιότητα στην ταχύτητα διατηρώντας την αξιοπρεπή ακρίβεια |
Τι είναι η τμηματοποίηση;
Όπως γνωρίζουμε, η κατάτμηση σημαίνει ότι χωρίζουμε τη μεγάλη εικόνα σε μικρότερες ομάδες με βάση ορισμένα χαρακτηριστικά. Ας κατανοήσουμε την τμηματοποίηση εικόνας, η οποία είναι η τεχνική όρασης υπολογιστή που χρησιμοποιείται για τη διαίρεση μιας εικόνας σε διαφορετικά πολλαπλά τμήματα ή περιοχές. Καθώς οι εικόνες αποτελούνται από εικονοστοιχεία και στην κατάτμηση εικόνας, τα εικονοστοιχεία ομαδοποιούνται σύμφωνα με την ομοιότητα στο χρώμα, την ένταση, την υφή ή άλλες οπτικές ιδιότητες.
Για παράδειγμα, εάν μια εικόνα περιέχει δέντρα, αυτοκίνητα ή άτομα, τότε η τμηματοποίηση της εικόνας θα χωρίσει την εικόνα σε διαφορετικές κατηγορίες που αντιπροσωπεύουν αντικείμενα ή μέρη της εικόνας με νόημα. Η κατάτμηση εικόνας χρησιμοποιείται ευρέως σε διάφορους τομείς όπως η ιατρική απεικόνιση, η ανάλυση δορυφορικών εικόνων, η αναγνώριση αντικειμένων στην όραση υπολογιστή και πολλά άλλα.

Στο τμήμα τμηματοποίησης, δημιουργούμε αρχικά το πρώτο μοντέλο τμηματοποίησης YOLOv8 χρησιμοποιώντας το Robflow. Στη συνέχεια, εισάγουμε το μοντέλο τμηματοποίησης για να εκτελέσουμε την εργασία τμηματοποίησης. Τίθεται το ερώτημα: γιατί δημιουργούμε το μοντέλο τμηματοποίησης όταν η εργασία θα μπορούσε να ολοκληρωθεί μόνο με έναν αλγόριθμο ανίχνευσης;
Η τμηματοποίηση μας επιτρέπει να αποκτήσουμε την εικόνα ολόκληρου του σώματος μιας τάξης. Ενώ οι αλγόριθμοι ανίχνευσης επικεντρώνονται στην ανίχνευση της παρουσίας αντικειμένων, η τμηματοποίηση παρέχει μια πιο ακριβή κατανόηση οριοθετώντας τα ακριβή όρια των αντικειμένων. Αυτό οδηγεί σε πιο ακριβή εντοπισμό και κατανόηση των αντικειμένων που υπάρχουν στην εικόνα.
Ωστόσο, η τμηματοποίηση συνήθως περιλαμβάνει μεγαλύτερη πολυπλοκότητα χρόνου σε σύγκριση με τους αλγόριθμους ανίχνευσης, επειδή απαιτεί πρόσθετα βήματα, όπως ο διαχωρισμός των σχολιασμών και η δημιουργία του μοντέλου. Παρά αυτό το μειονέκτημα, η αυξημένη ακρίβεια που προσφέρει η τμηματοποίηση μπορεί να αντισταθμίσει το υπολογιστικό κόστος σε εργασίες όπου η ακριβής οριοθέτηση αντικειμένων είναι ζωτικής σημασίας.
Βήμα προς βήμα Ζωντανή ανίχνευση και τμηματοποίηση εικόνας με το YOLOv8
Σε αυτή την ιδέα διερευνούμε τα βήματα για τη δημιουργία ενός εικονικού περιβάλλοντος χρησιμοποιώντας το conda, την ενεργοποίηση του venv και την εγκατάσταση των πακέτων απαιτήσεων χρησιμοποιώντας το pip. δημιουργώντας πρώτα το κανονικό σενάριο python και μετά δημιουργούμε την εφαρμογή streamlit.
Βήμα 1: Δημιουργήστε ένα εικονικό περιβάλλον χρησιμοποιώντας το Conda
conda create -p ./venv python=3.8 -yΒήμα 2: Ενεργοποιήστε το εικονικό περιβάλλον
conda activate ./venv
Βήμα 3: Δημιουργήστε τις απαιτήσεις.txt
Ανοίξτε το τερματικό και επικολλήστε το παρακάτω σενάριο:
touch requirements.txtΒήμα 4: Χρησιμοποιήστε την εντολή Nano και επεξεργαστείτε τις απαιτήσεις.txt
Μετά τη δημιουργία των απαιτήσεων.txt γράψτε την ακόλουθη εντολή για την επεξεργασία των απαιτήσεων.txt
nano requirements.txtΑφού εκτελέσετε το παραπάνω σενάριο, μπορείτε να δείτε αυτό το UI.
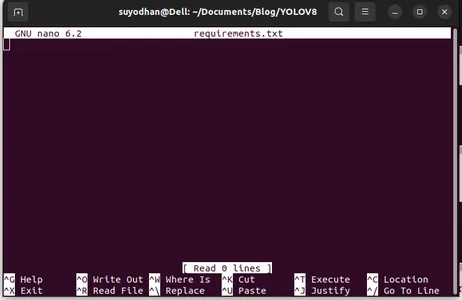
Γράψε τα απαιτούμενα πακέτα της.
ultralytics==8.0.32
supervision==0.2.1
streamlitΣτη συνέχεια πατήστε το "ctrl+o"(αυτή η εντολή αποθηκεύει το μέρος επεξεργασίας) στη συνέχεια πατήστε το "Εισαγω"
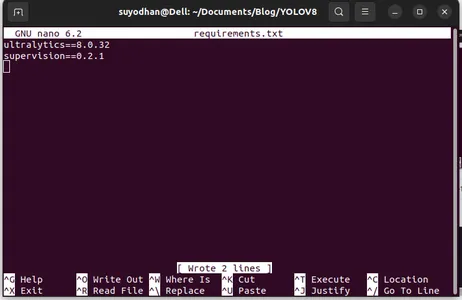
Αφού πατήσετε το «Ctrl+x». μπορείτε να βγείτε από το αρχείο. και πηγαίνοντας στο κεντρικό μονοπάτι.
Βήμα 5: Εγκατάσταση των απαιτήσεων.txt
pip install -r requirements.txtΒήμα 6: Δημιουργήστε το σενάριο Python
Στο τερματικό γράψτε το παρακάτω σενάριο ή μπορούμε να πούμε εντολή.
touch main.pyΑφού δημιουργήσετε το main.py ανοίξτε τον κώδικα vs, χρησιμοποιείτε την εντολή εγγραφή στο τερματικό,
code Βήμα 7: Γράψτε το σενάριο Python
import cv2
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
cv2.imshow("yolov8", frame)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
Αφού εκτελέσετε αυτήν την εντολή, μπορείτε να δείτε ότι η κάμερά σας είναι ανοιχτή και ανιχνεύει μέρος του εαυτού σας. όπως το φύλο και το φόντο.
Βήμα 7: Δημιουργήστε streamlit εφαρμογή
import cv2
import streamlit as st
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Set page title and header
st.title("Live Object Detection with YOLOv8")
# Button to start the camera
start_camera = st.button("Start Camera")
if start_camera:
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
st.image(frame, channels="BGR", use_column_width=True)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
if __name__ == "__main__":
main()
Σε αυτό το σενάριο, δημιουργούμε την εφαρμογή streamlit και δημιουργούμε το κουμπί έτσι ώστε μετά το πάτημα του κουμπιού η κάμερα της συσκευής σας να είναι ανοιχτή και να ανιχνεύσει το τμήμα στο πλαίσιο.
Εκτελέστε αυτό το σενάριο χρησιμοποιώντας αυτήν την εντολή.
streamlit run app.py
# first create the app.py then paste the above code and run this script.Αφού εκτελέσετε την παραπάνω εντολή, ας υποθέσουμε ότι λάβατε το σφάλμα προσέγγισης όπως,
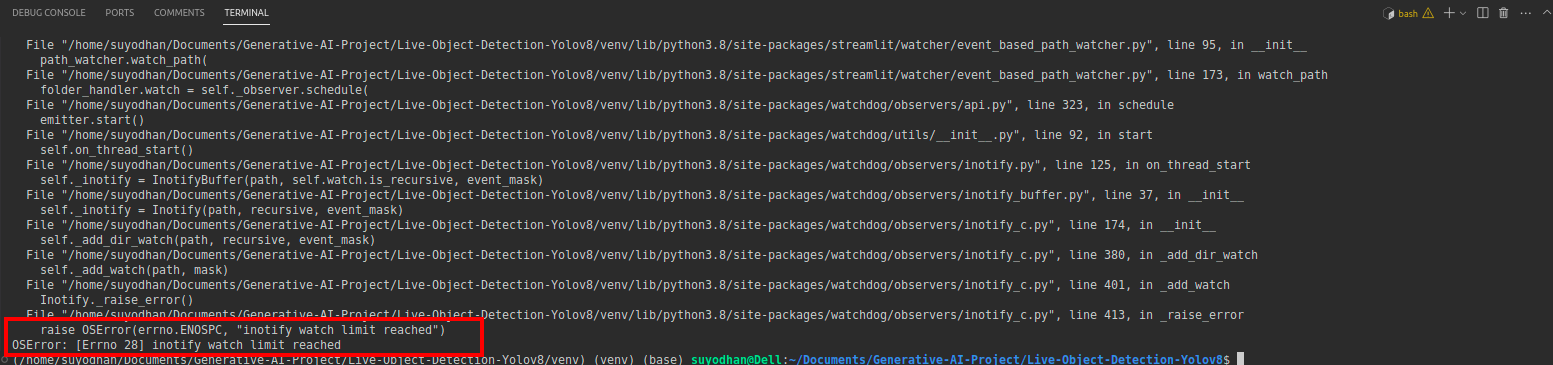
μετά πατήστε αυτήν την εντολή,
sudo sysctl fs.inotify.max_user_watches=524288Αφού πατήσετε την εντολή με την οποία θέλετε να γράψετε τον κωδικό πρόσβασής σας επειδή χρησιμοποιούμε την εντολή sudo το sudo is god :)
Εκτελέστε ξανά το σενάριο. και μπορείτε να δείτε την εφαρμογή streamlit.
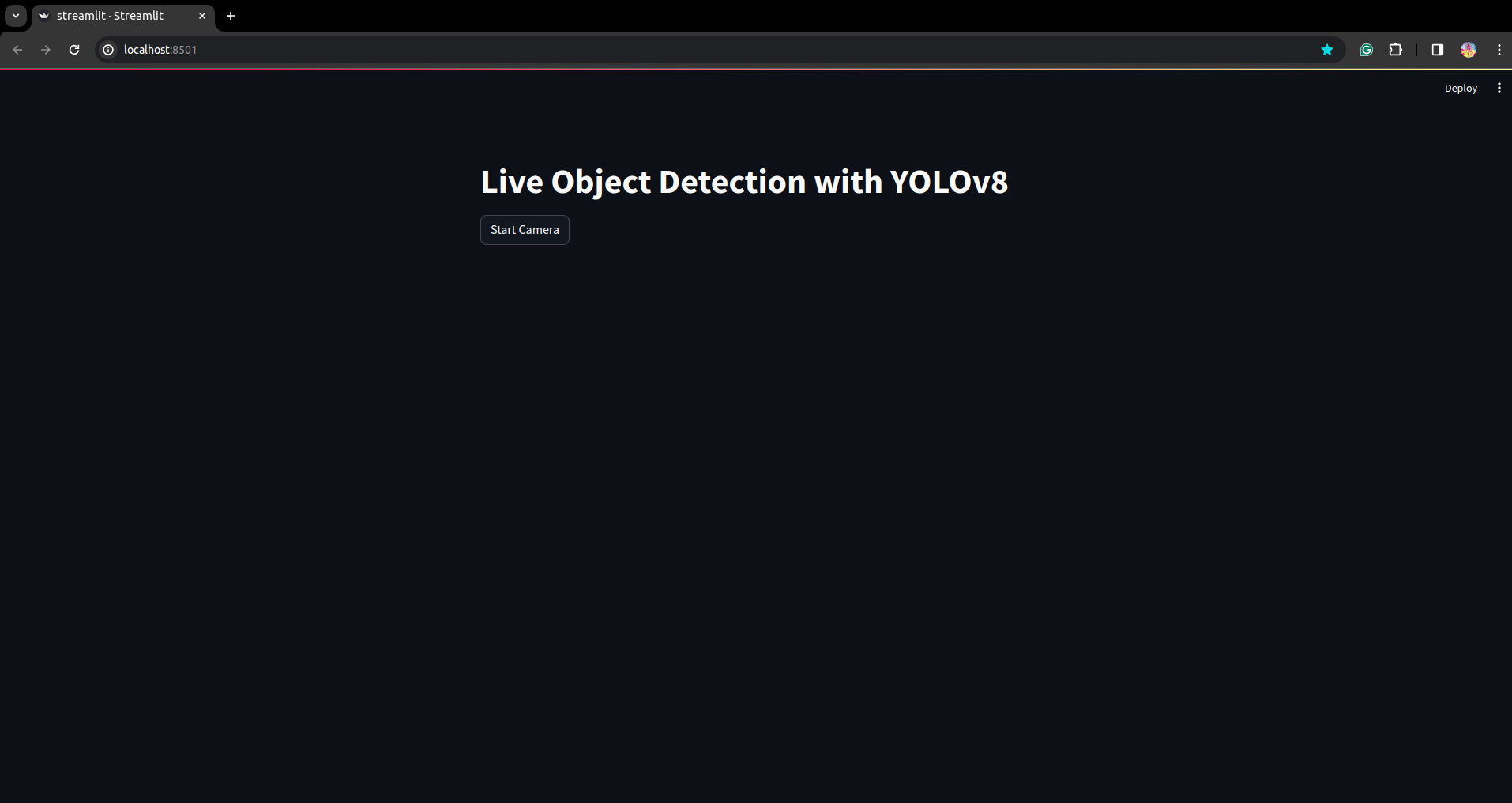
Εδώ μπορούμε να δημιουργήσουμε μια επιτυχημένη εφαρμογή ζωντανής ανίχνευσης στο επόμενο μέρος που θα δούμε το τμήμα τμηματοποίησης.
Βήματα για σχολιασμό
Βήμα 1: Ρύθμιση Roboflow
Μετά την υπογραφή του «Δημιουργία έργου». εδώ μπορείτε να δημιουργήσετε την ομάδα έργου και σχολιασμού.

Βήμα 2: Λήψη συνόλου δεδομένων
Εδώ εξετάζουμε το απλό παράδειγμα, αλλά θέλετε να το χρησιμοποιήσετε στη δήλωση προβλήματος σας, γι' αυτό χρησιμοποιώ εδώ το σύνολο δεδομένων πάπιας.
Πήγαινε αυτό σύνδεσμος και κατεβάστε το σύνολο δεδομένων πάπιας.

Εξαγάγετε το φάκελο εκεί και μπορείτε να δείτε τους τρεις φακέλους: τρένο, δοκιμή και βαλ.
Βήμα 3: Μεταφόρτωση του συνόλου δεδομένων στο roboflow
Αφού δημιουργήσετε το έργο στο roboflow, μπορείτε να δείτε αυτό το περιβάλλον χρήστη εδώ, μπορείτε να ανεβάσετε το σύνολο δεδομένων σας, επομένως αν ανεβάσετε μόνο εικόνες τμημάτων τρένου επιλέξτε το "Επιλέξτε φάκελο" επιλογή.
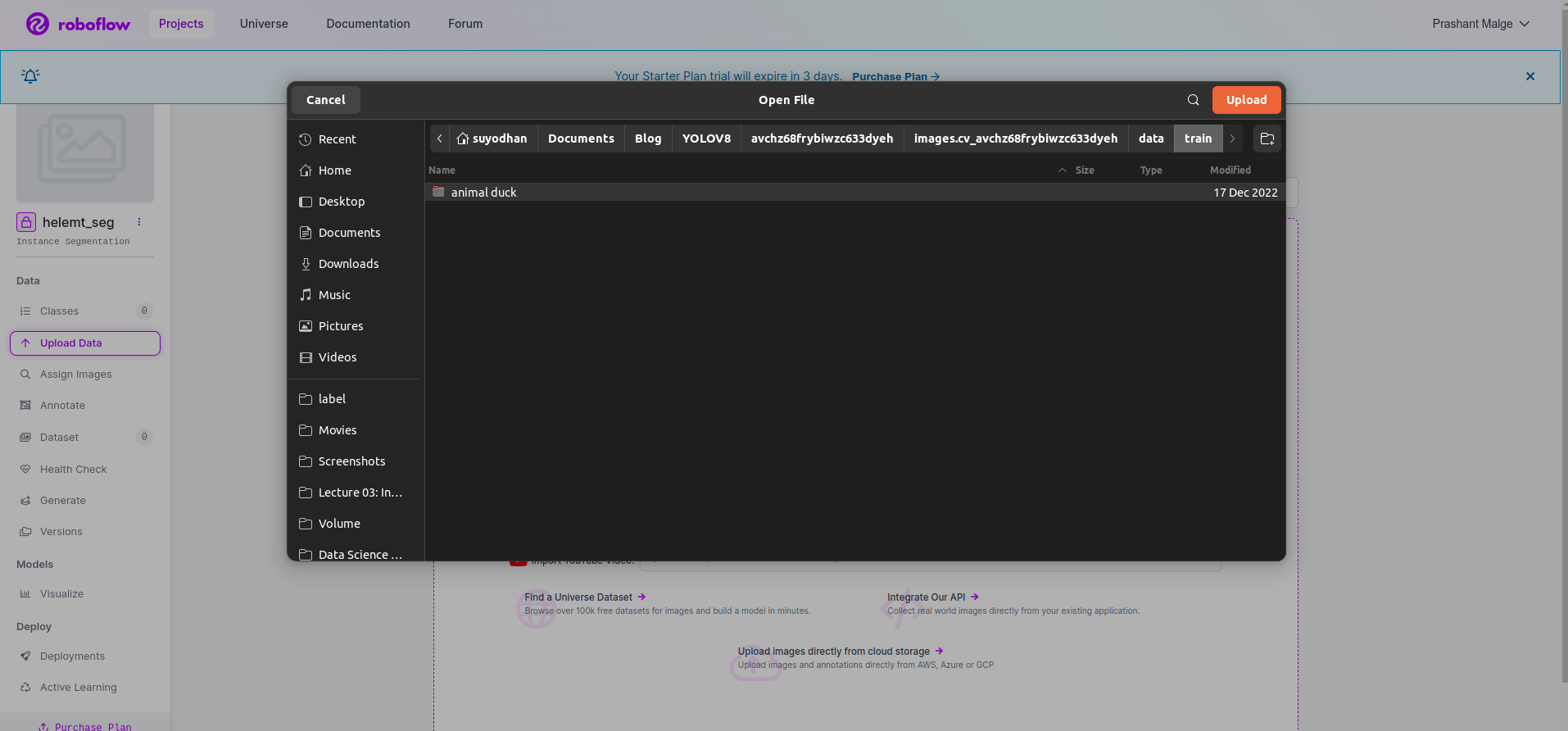
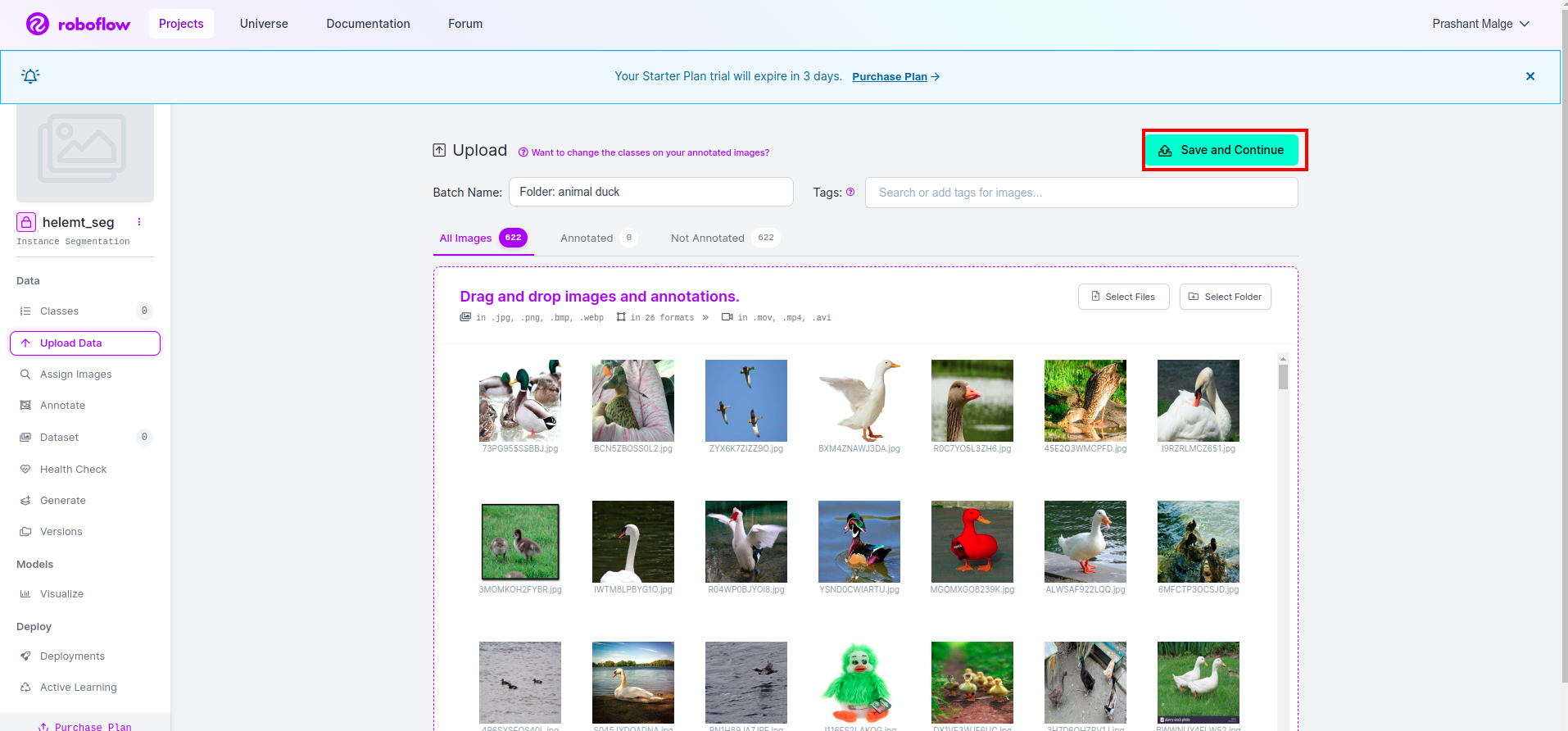
Στη συνέχεια, κάντε κλικ στο "αποθήκευση και συνέχεια" επιλογή όπως σημειώνω σε ένα κόκκινο ορθογώνιο πλαίσιο
Βήμα 4: Προσθέστε το όνομα της τάξης
Στη συνέχεια, πηγαίνετε στο τμήμα της τάξης στην αριστερή πλευρά, επιλέξτε το κόκκινο πλαίσιο. και γράψτε το όνομα της τάξης ως πάπια, αφού κάνετε κλικ στο πράσινο πλαίσιο.
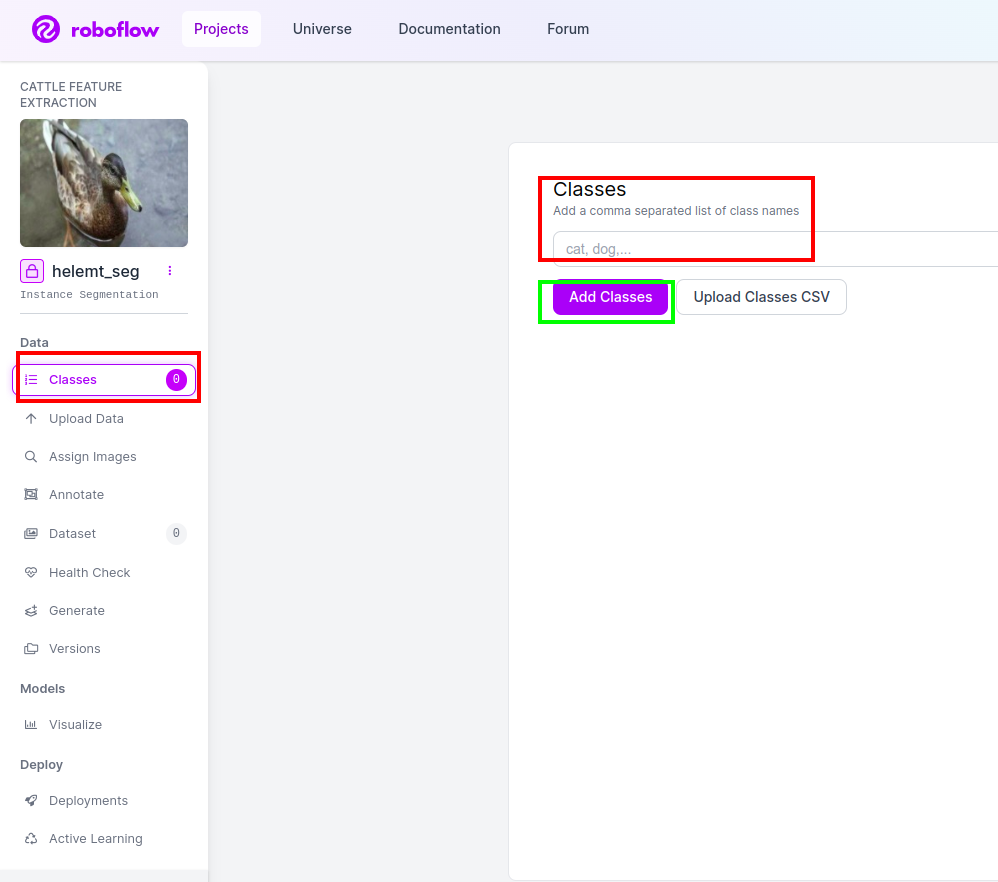
Τώρα η εγκατάσταση μας έχει ολοκληρωθεί και το επόμενο μέρος όπως το μέρος του σχολιασμού είναι επίσης απλό.
Βήμα 5: Ξεκινήστε το μέρος σχολιασμού
Πηγαίνετε στο επιλογή σχολιασμού Σημάδεψα στο κόκκινο πλαίσιο και μετά κάντε κλικ στο ξεκίνημα του τμήματος σχολιασμού όπως σημείωσα στο πράσινο πλαίσιο.
Κάντε κλικ στην πρώτη εικόνα που μπορείτε να δείτε αυτή τη διεπαφή χρήστη. Αφού το δείτε, κάντε κλικ στην επιλογή χειροκίνητου σχολιασμού.
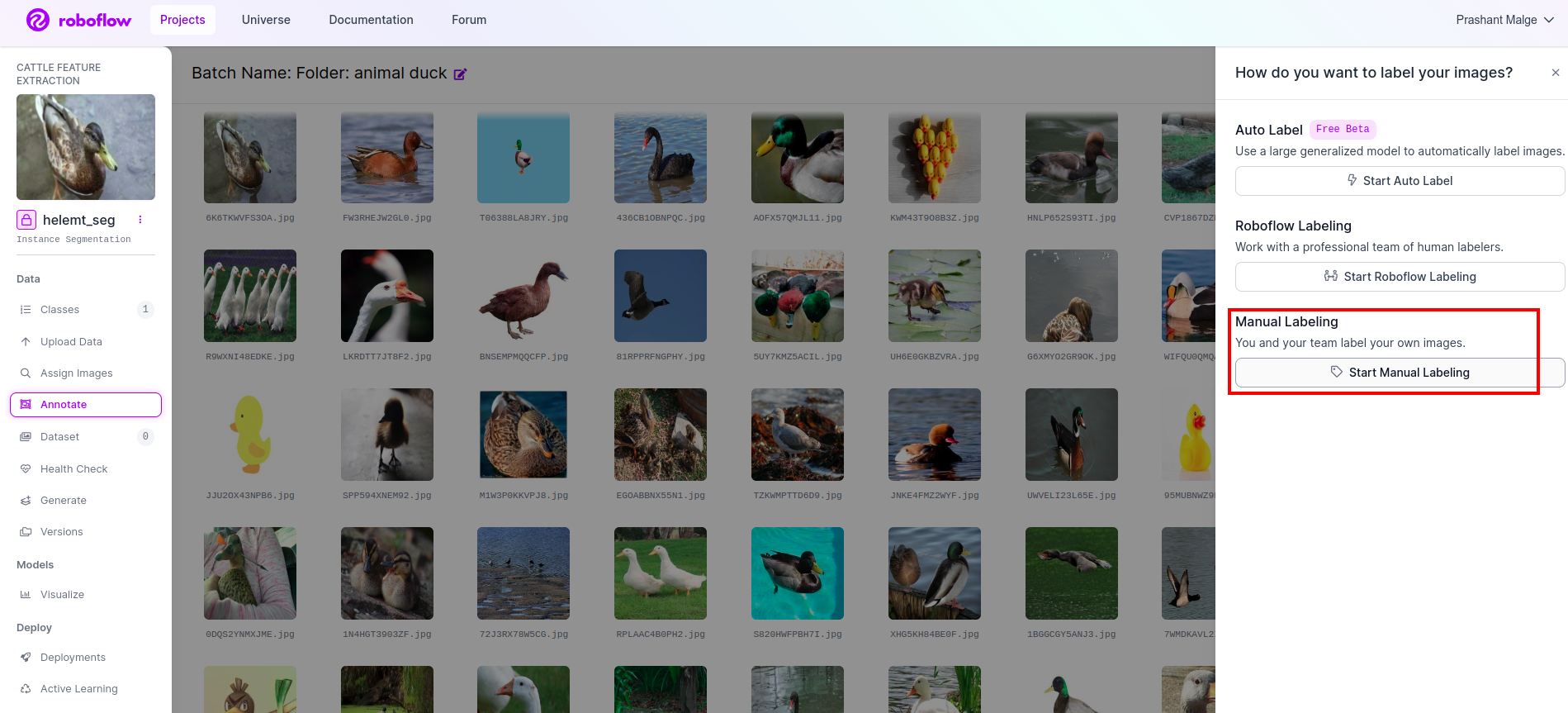
Στη συνέχεια, προσθέστε το αναγνωριστικό email σας ή το όνομα του συμπαίκτη σας, ώστε να μπορείτε να αναθέσετε την εργασία.
Κάντε κλικ στην πρώτη εικόνα που μπορείτε να δείτε αυτή τη διεπαφή χρήστη. εδώ κάντε κλικ στο κόκκινο πλαίσιο για να επιλέξετε το πολυωνυμικό μοντέλο.
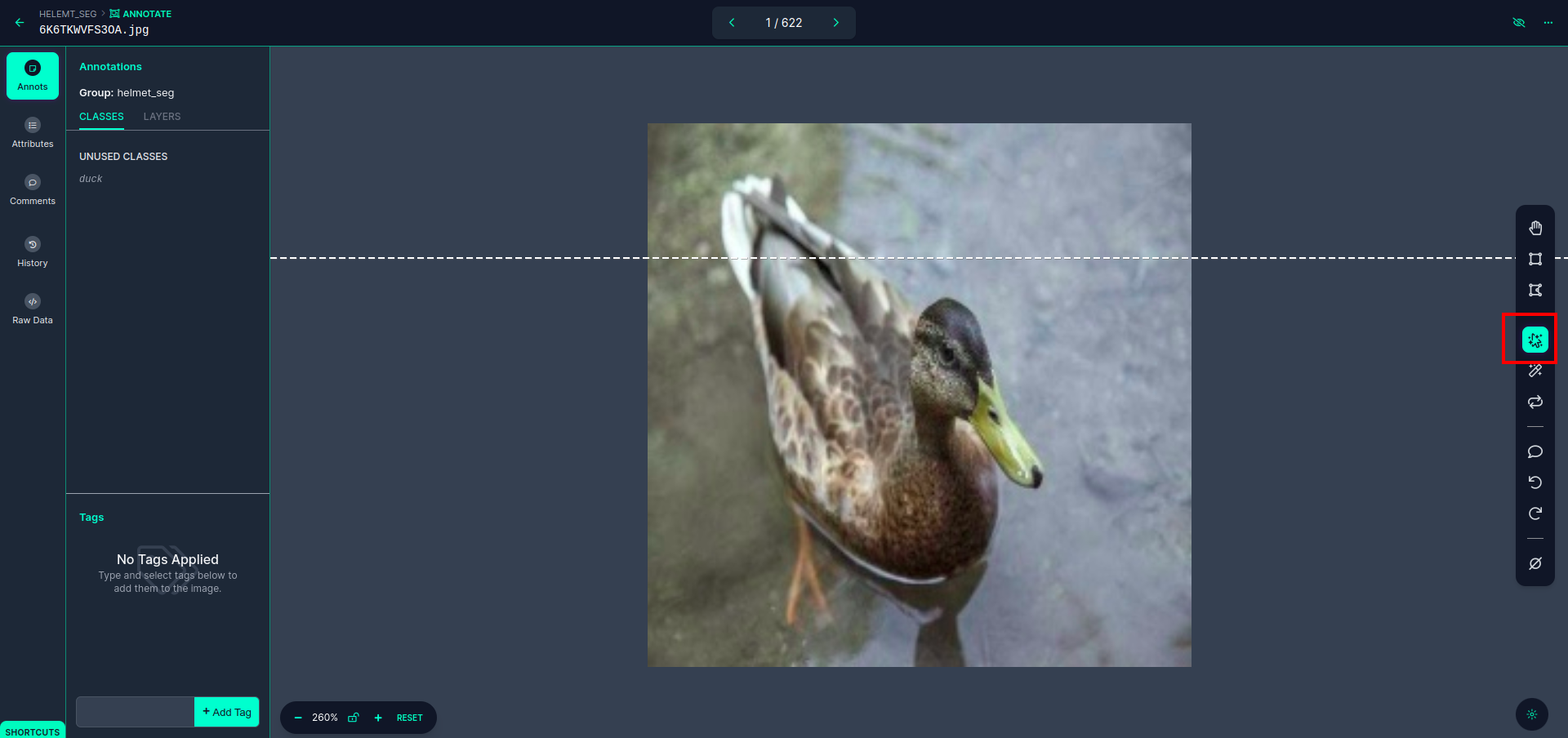
Αφού κάνετε κλικ στο κόκκινο πλαίσιο, επιλέξτε το προεπιλεγμένο μοντέλο και κάντε κλικ στο αντικείμενο πάπιας. Αυτό θα τμηματοποιήσει αυτόματα την εικόνα. Στη συνέχεια, κάντε κλικ στο επόμενο μέρος και αποθηκεύστε το. Στη συνέχεια, θα δείτε την αριστερή πλευρά σημειωμένη σε ένα κόκκινο πλαίσιο, όπου μπορείτε να δείτε το όνομα της τάξης.
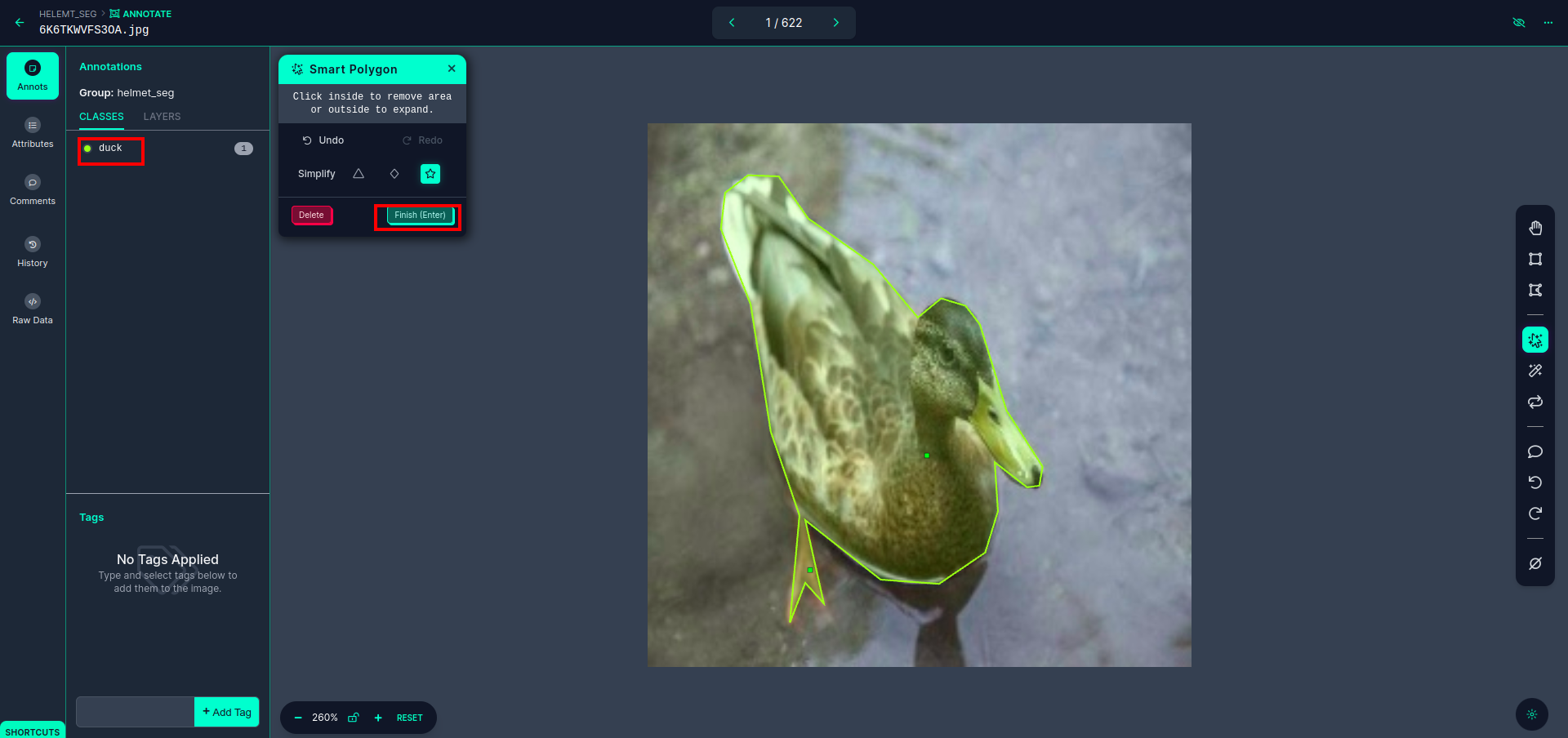
Κάντε κλικ στο αποθήκευση&εισαγωγή επιλογή. σχολιάστε όλες τις εικόνες.
Προσθέστε τις εικόνες για τη μορφή YOLOv8. Στη δεξιά πλευρά, θα δείτε την επιλογή προσθήκης εικόνων στην ενότητα σχολιασμού. Εδώ δημιουργούνται δύο μέρη: ένα για σχολιασμένες εικόνες και ένα για μη σχολιασμένες εικόνες.
- Πρώτα, κάντε κλικ στην αριστερή πλευρά "σχολιάζω" επιλογή τότε προσθέτω Οι εικόνες στο σύνολο δεδομένων.
- Στη συνέχεια, κάντε κλικ στο επόμενο "Προσθήκη εικόνων".
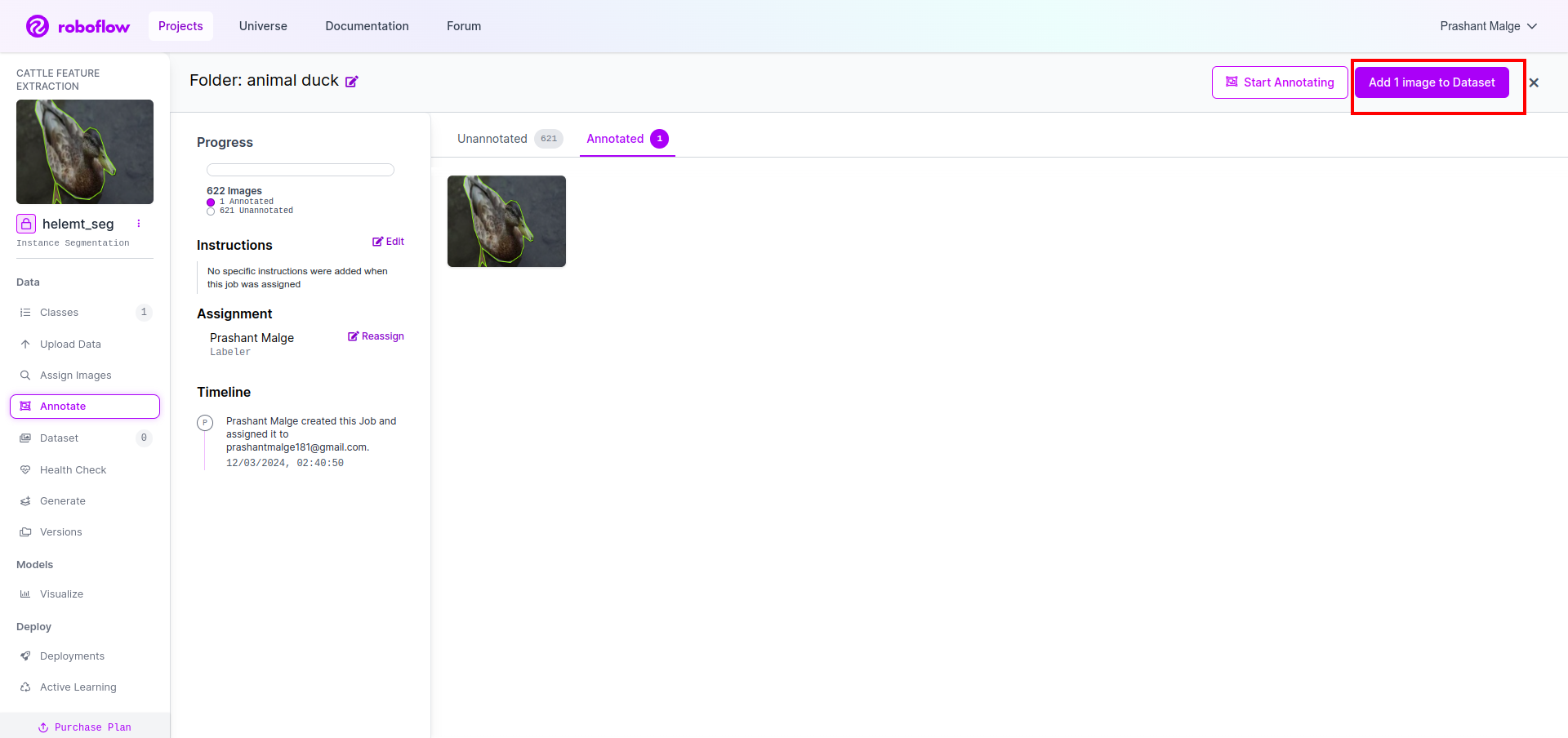
Τώρα τελευταία, δημιουργούμε το σύνολο δεδομένων, οπότε κάντε κλικ στην επιλογή "Δημιουργία" στην αριστερή πλευρά, επιλέξτε την επιλογή και πατήστε την επιλογή conitune.
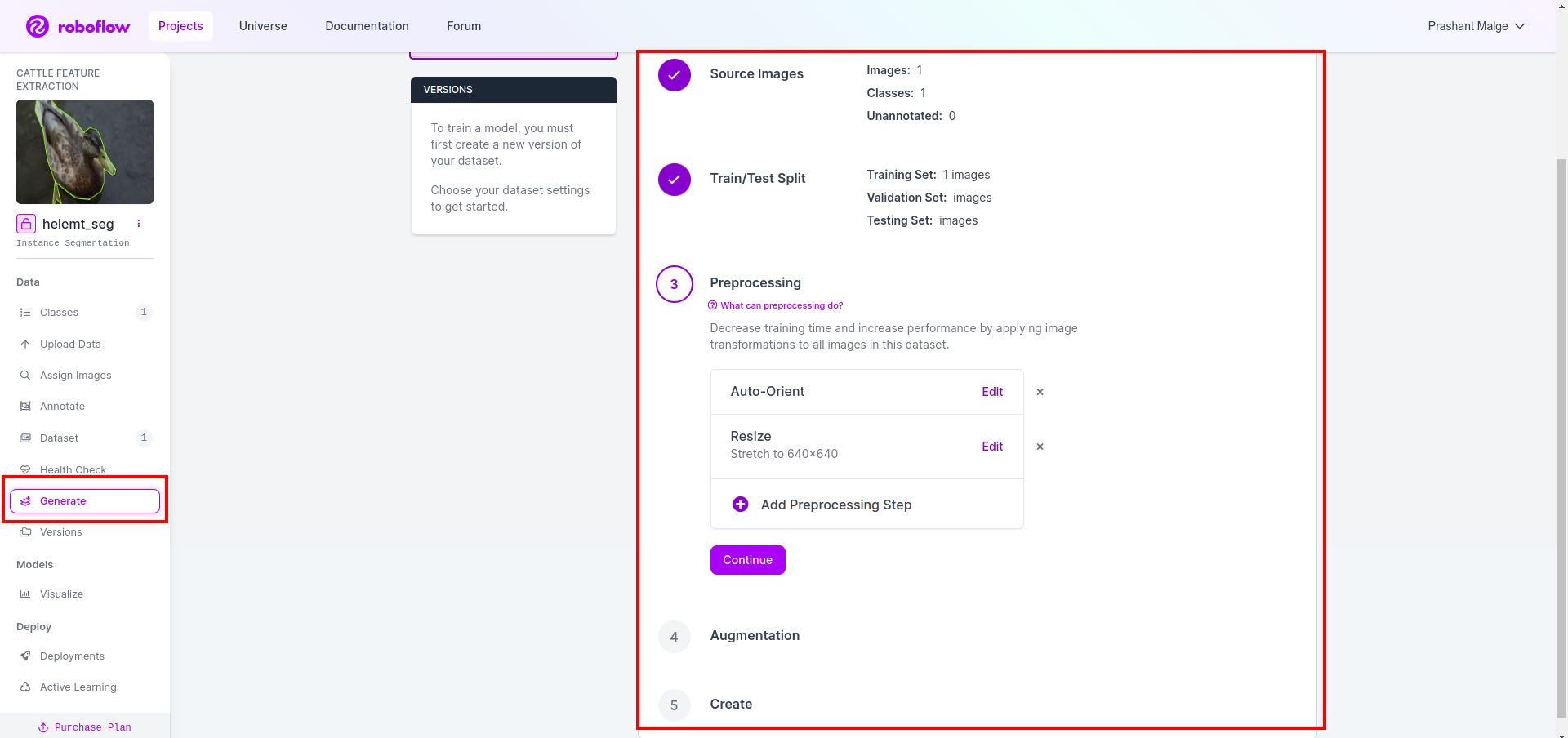
Στη συνέχεια, λαμβάνετε τη διεπαφή χρήστη της επιλογής διαχωρισμού του συνόλου δεδομένων εδώ, μπορείτε να ελέγξετε τους φακέλους αμαξοστοιχίας, δοκιμής και val, οι εικόνες τους χωρίζονται αυτόματα. και κάντε κλικ στο παραπάνω κόκκινο πλαίσιο Επιλογή εξαγωγής συνόλου δεδομένων και κατεβάστε το αρχείο zip. η δομή του φακέλου του αρχείου zip είναι σαν…
root_file.zip
│
├── test
│ ├── Images
│ └── labels
│
├── train
│ ├── Images
│ └── labels
│
├── val
│ ├── Images
│ └── labels
│
├── data.yaml
└── Readme.roboflow.txt
Βήμα 6: Γράψτε το σενάριο για την εκπαίδευση του μοντέλου τμηματοποίησης εικόνας
Σε αυτό το μέρος, πρώτα δημιουργείτε το αρχείο Google Collab χρησιμοποιώντας το Drive και, στη συνέχεια, ανεβάζετε το σύνολο δεδομένων σας. και μετακινήστε το Google Drive χρησιμοποιώντας το Google Collab.
1. Χρησιμοποιήστε αυτήν την εντολή για Τοποθετήστε το Google Drive
from google.colab import drive
drive.mount('/content/gdrive')2. Ορισμός καταλόγου δεδομένων Χρησιμοποιήστε τη μεταβλητή Constant.
DATA_DIR = '/content/drive/MyDrive/YoloV8/Data/'3. Εγκατάσταση του απαιτούμενου πακέτου, Εγκαταστήστε το ultralytics
!pip install ultralytics4. Εισαγωγή των βιβλιοθηκών
import os
from ultralytics import YOLO5. Φόρτωση προεκπαιδευμένο YOLOv8 μοντέλο (εδώ έχουμε διαφορετικό μοντέλο, ελέγξτε επίσης την επίσημη τεκμηρίωση εκεί μπορείτε να δείτε το διαφορετικό μοντέλο)
model = YOLO('yolov8n-seg.pt')
# load a pretrained model (recommended for training)
6. Εκπαιδεύστε το μοντέλο
model.train(data='/content/drive/MyDrive/YoloV8/Data/data.yaml', epochs=2, imgsz=640)
# Update the path & and join this line together Όχι ελέγξτε τη μονάδα δίσκου σας Ο φάκελος ονόματος μοντέλου δημιουργείται και εκεί το μοντέλο αποθηκεύεται για την πρόβλεψη που θέλουμε αυτό το μοντέλο.
7. Προβλέψτε το μοντέλο
#Update the path
model_path = '/content/drive/MyDrive/YoloV8/Model/train2/weights/last.pt'
#Update the path
image_path = '/content/drive/MyDrive/YoloV8/Data/val/1be566eccffe9561.png'
img = cv2.imread(image_path)
H, W, _ = img.shape
model = YOLO(model_path)
results = model(img)
for result in results:
for j, mask in enumerate(result.masks.data):
mask = mask.numpy() * 255
mask = cv2.resize(mask, (W, H))
cv2.imwrite('./output.png', mask)Εδώ μπορείτε να δείτε ότι η εικόνα τμηματοποίησης έχει αποθηκευτεί.

Τώρα επιτέλους μπορούμε να δημιουργήσουμε μοντέλα ζωντανής ανίχνευσης και τμηματοποίησης εικόνας.
Συμπέρασμα
Σε αυτό το ιστολόγιο, εξερευνούμε ζωντανή ανίχνευση αντικειμένων και τμηματοποίηση εικόνων με το YOLOv8. Για ζωντανή ανίχνευση, εισάγουμε ένα προεκπαιδευμένο μοντέλο YOLOv8 και χρησιμοποιούμε τη βιβλιοθήκη όρασης υπολογιστή, OpenCV, για να ανοίξουμε την κάμερα και να ανιχνεύσουμε αντικείμενα. Επιπλέον, δημιουργούμε μια εφαρμογή Streamlit για μια ελκυστική διεπαφή χρήστη.
Στη συνέχεια, εμβαθύνουμε στην τμηματοποίηση εικόνων με το YOLOv8. Εισάγουμε ένα προεκπαιδευμένο μοντέλο και εκτελούμε εκμάθηση μεταφοράς σε ένα προσαρμοσμένο σύνολο δεδομένων. Πριν από αυτό, εξερευνήσαμε το Roboflow για σχολιασμό δεδομένων, παρέχοντας μια εύχρηστη εναλλακτική λύση σε εργαλεία όπως LabelImg.
Τέλος, προβλέπουμε μια εικόνα που περιέχει μια πάπια. Αν και το αντικείμενο στην εικόνα φαίνεται να είναι ένα πουλί, καθορίζουμε το όνομα της κλάσης ως "πάπια” για λόγους επίδειξης.
Βασικές τακτικές
- Μαθαίνοντας για μοντέλα ανίχνευσης αντικειμένων όπως το Faster R-CNN, το SSD και το πιο πρόσφατο YOLOv8.
- Κατανόηση του εργαλείου σχολιασμού Roboflow και του ρόλου του στη δημιουργία συνόλων δεδομένων για μοντέλα τμηματοποίησης YOLOv8.
- Εξερευνώντας την ανίχνευση ζωντανών αντικειμένων χρησιμοποιώντας το OpenCV (cv2) και την εποπτεία, βελτιώνοντας τις πρακτικές δεξιότητες.
- Εκπαίδευση και ανάπτυξη ενός μοντέλου τμηματοποίησης χρησιμοποιώντας το YOLOv8, αποκτώντας πρακτική εμπειρία.
Συχνές Ερωτήσεις
Α. Η ανίχνευση αντικειμένων περιλαμβάνει τον εντοπισμό και τον εντοπισμό πολλαπλών αντικειμένων μέσα σε μια εικόνα, συνήθως σχεδιάζοντας οριοθετημένα πλαίσια γύρω τους. Η κατάτμηση εικόνας, από την άλλη πλευρά, διαιρεί μια εικόνα σε τμήματα ή περιοχές με βάση την ομοιότητα των εικονοστοιχείων, παρέχοντας μια πιο λεπτομερή κατανόηση των ορίων των αντικειμένων.
Το A. YOLOv8 βελτιώνει τις προηγούμενες εκδόσεις ενσωματώνοντας προόδους στην αρχιτεκτονική δικτύου, τις τεχνικές εκπαίδευσης και τη βελτιστοποίηση. Μπορεί να προσφέρει καλύτερη ακρίβεια, ταχύτητα και αποτελεσματικότητα σε σύγκριση με το YOLOv3.
A. Το YOLOv8 μπορεί να χρησιμοποιηθεί για ανίχνευση αντικειμένων σε πραγματικό χρόνο σε ενσωματωμένες συσκευές, ανάλογα με τις δυνατότητες υλικού και τη βελτιστοποίηση του μοντέλου. Ωστόσο, ενδέχεται να απαιτούνται βελτιστοποιήσεις όπως το κλάδεμα μοντέλων ή η κβαντοποίηση για την επίτευξη απόδοσης σε πραγματικό χρόνο σε συσκευές με περιορισμένους πόρους.
Το A. Roboflow προσφέρει διαισθητικά εργαλεία σχολιασμού, δυνατότητες διαχείρισης δεδομένων και υποστήριξη για διάφορες μορφές σχολιασμού. Βελτιώνει τη διαδικασία σχολιασμού, επιτρέπει τη συνεργασία και παρέχει έλεγχο έκδοσης, διευκολύνοντας τη δημιουργία και τη διαχείριση συνόλων δεδομένων για έργα υπολογιστικής όρασης.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://www.analyticsvidhya.com/blog/2024/03/live-object-detection-and-image-segmentation-with-yolov8/

