This blog post was co-authored with Federico Piccinini.
The data landscape has been changing in recent years: there is a proliferation of entities producing and consuming large quantities of data within companies, and for most of them defining a proper data strategy has become of fundamental importance. A modern data strategy gives you a comprehensive plan to manage, access, analyze, and act on data.
As a result, more companies are considering the adoption of a data mesh architecture, a recently introduced paradigm where data is organized by domain, clear ownership of data and technology stack is enhanced, and a more agile setup is achieved. Because of this, some of your applications may need to be designed for a data-by-domain separation in order to benefit from a data mesh architecture.
In this post, we show you how to design a data mesh architecture for a scenario that requires real-time recommendations. The recommendation system is implemented through Amazon Personalize, a fully managed machine learning (ML) service, and works by consuming data by domain. For recommendations use cases, it’s important to have access to information about users, items, and interactions, often associated with different data sources within a company.
Because ML applications may have multiple types of input data, we propose a solution that works both for data at rest as well as real-time streaming. Real-time recommendations require streaming data in order to adapt to the user’s current intent.
Throughout the post, we introduce the data mesh paradigm and then extend it to a real-time use case by adding event streaming capabilities. We use the use case of a music streaming company that offers its customers the opportunity to listen to on-demand songs. The company has also started to offer, through the same platform, on-demand podcasts, and wants to take advantage of a modern data architecture to support data access for fast ML experimentation and inference.
Data mesh: A paradigm shift
Domain-driven design (DDD) represents a software design approach where complex solutions are divided into domains according to the underlying business logic. An architectural style that is often mentioned in the context of DDD is microservice architecture, a concept where software systems are structured into loosely coupled entities, namely microservices, each one owned by a small team and structured around business requirements. These paradigms, together with the advancement of cloud technologies, allowed companies to release software updates faster and continuously adapt their technology stack to evolving business requirements.
However, unlike software architectures, most data architectures were still designed around technologies rather than business domains. This changed in 2019, when Zhamak Dehghani introduced the data mesh. Data mesh is a paradigm shift towards data being treated as a product and processed as part of a domain. Data mesh applies the principles of DDD to data architectures: data is organized into data domains and the data is considered the product that the team owns and offers for consumption. This is a shift from a centralized ownership model to a decentralized one that allows companies to access data at scale. This shift also allows each team assigned to a data domain to build the data products by choosing the right technology for their job, analogous to software engineers working on a microservice.
Data mesh advocates for decentralized ownership and delivery of data management systems, while emphasizing the need for distributed governance and self-service tooling. The data mesh approach enables better autonomy of data domain owners and brings domains together to enable data sharing and federation across business units, without compromising on data security. This type of architecture supports the idea of distributed data, where all data is accessible for those with the right authority to access it. One key differentiator between a data lake and a data mesh is that in a data mesh, data doesn’t have to be consolidated into a single data lake and can remain within different databases.
For more information about the details and advantages of adopting the data mesh as a domain-driven data architecture, refer to Design a data mesh architecture using AWS Lake Formation and AWS Glue.
The components of a data mesh
Now that we have a good understanding of the data mesh paradigm, let’s look at the implementation and its components.
First, we start with data producers. These are the entities that are responsible for maintaining, owning, and exposing the specific data of their domain. Because of the domain separation, each producer can choose its own technology stack independently.
Similarly, we also have data consumers. These components, as their name indicates, use one or more data sources exposed by the producers. As before, adopting a data mesh architecture implies that each consumer is independent one another, meaning they could implement different technology stacks as well as solve different use cases.
The data-at-rest plane is then completed by the Centralized Data Catalog, a component that works as the link between producers and consumers. This middle layer is responsible for indexing the available data producers into a centralized data catalog as well as controlling access to the different data sources.
The data catalog is used by the producers to expose the data products (steps 1a and 1b) to the organization’s data scientists and data engineers working on the consumer domains. The following figure illustrates how data products should be easily discoverable: the central data catalog allows the data consumers to find their data source of interest (steps 2a and 2b) after they have been registered with the centralized catalog by their corresponding producer domain (steps 1a and 1b).
Working with real-time events
One could argue that this architecture can only support data at rest as it is; indeed, there is no straightforward solution to move data in real time from a producer domain to a consumer. The paradigm presented so far addresses the scenario of data at rest, where producers are pulling data on demand rather than being notified when data is changed.
Because several applications need to quickly respond to the changes happening in the environment, real-time data is an important consideration in data architectures. For example, an ecommerce platform or a video streaming service can extract value from the real-time user interactions with content. In these cases, it’s critical to track events as they happen, feed them in the ML model, and adapt the predictions accordingly.
In this section, we want to introduce some of the streaming platforms that can work to implement this pattern, with a focus on Apache Kafka because it’s frequently used and many companies are moving their Kafka workloads to the cloud.
Apache Kafka is an open-source distributed event streaming platform that captures data in real time from sources such as microservices or databases, stores the events in streams organized into topics, and reacts to these events in real time as well as retrospectively. Event streaming architectures built on Apache Kafka follow the publish/subscribe paradigm: the producers publish events to topics via a write operation, and the consumers, which subscribe to such topics, receive the events as they happen. An alternative to Apache Kafka in this scenario could be Amazon Kinesis Data Streams, a streaming service that allows developers to collect, store, and process real-time data in the cloud.
If we consider for example an ecommerce platform, we could have a Payment microservice running the payment functionalities of the system publishing events to Purchases topic, tracking every transaction happening on the platform. Then, we could have another component subscribing to the Purchases topic to receive the events and take action accordingly, for example by updating a dashboard for business intelligence. For more information on Apache Kafka, we recommend reading Introduction to Apache Kafka.
Event-streaming architecture
The data-in-motion plane is introduced to implement the publish/subscribe pattern in the context of a data mesh. Such a plane is composed of the set of producer and consumer domains connected via a central event streaming component that makes real-time events accessible. To benefit from the data-by-domain architecture, we consider each producer to have its own corresponding centralized stream, as shown in the following figure.
You can also think of the event stream as the channel for sending real-time events to the consumers, therefore each producer has its dedicated channel to send updates.
Each consumer can subscribe to multiple topics based on specific data needs. When new events are available, the corresponding producer publishes them in the associated stream (steps 1a and 1b) and the subscribers can read the events (step 2a and 2b), process them, and take action accordingly.
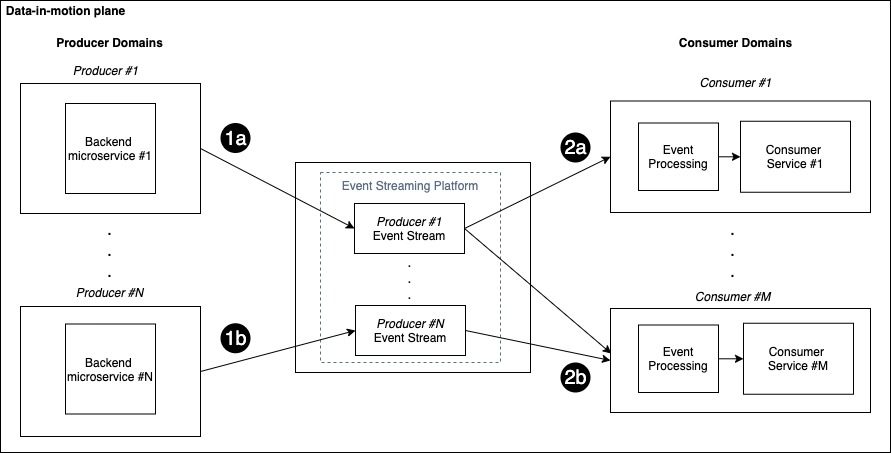
The preceding figure shows a scenario with N producer domains and M consumer domains: each consumer subscribes only to the streams of interest for that domain. In this example, Consumer #1 is subscribed to the events coming from Producer #1, while Consumer #M is subscribed to the events coming from both Producer #1 and Producer #N.
You could adopt this pattern to solve several use cases and data domains. For instance, a user playing a song on a music streaming platform can generate a new event sent from the Interactions service producer to the Personalization consumer, where the recommendation system generates personalized recommendations. Similarly, a Payment producer can send a transaction request, and a Fraud Detector consumer determines whether the transaction is fraudulent or not.
For producers and consumers to communicate correctly, the event payload schema needs to be consistent. Applications depend on schemas so no changes made to events break the implicit contract between producers and consumers. For complex use cases, you can use a schema registry to enforce compatibility in event streaming. For more information about the options for working with the AWS Glue Schema Registry, refer to Validate streaming data over Amazon MSK using schemas in cross-account AWS Glue Schema Registry.
Recommendation use case
Previously, we introduced the overall idea behind the data mesh architecture without focusing on a specific use case. In this section, we present a real-world scenario where the mesh paradigm is implemented using AWS.
Let’s consider the music streaming company XYZ, which offers its customers the opportunity to listen to on-demand songs. XYZ has recently started to offer, through the same platform, on-demand podcasts as well.
The ML team is interested in adding podcasts to the catalog of personalized recommendations that are presented to users. To do so, the ML team working on the recommendation system, which in the data mesh paradigm can be seen as a consumer, needs access to multiple data domains (producers): Users, Songs, Podcasts, and Interactions.
In this post, we use Amazon Personalize as a fully managed ML service for personalized recommendations. It allows developers to train, tune, and deploy custom ML models to deliver highly customized experiences. Amazon Personalize provisions the infrastructure and manages the entire ML pipeline, including processing the data; identifying features; and training, optimizing, and hosting the models. You can learn more about Amazon Personalize in the Developer Guide.
We now dive deeper into the implementation of the solution, both for the data-at-rest and data-in-motion scenario. ML needs large amounts of data at rest to create a dataset and train the models. Additionally, the personalization scenario requires access to real-time data to adapt to the users’ current intent, so we need access to real-time events and interactions. A data mesh solution for this scenario will require both:
- Data at rest – Historical data from user, items, and interactions. Some of this could be stored in separate systems and data sources.
- Data in motion – This data is for the real-time events, for instance songs listened to or new items made available in the catalog.
Architecture for data at rest
In this section, we focus on the data at rest part of the solution.
The following diagram shows how we can implement the data mesh architecture in the context of personalized recommendations, and include the podcasts in the recommendation system deployed with Amazon Personalize. Each producer domain owns the data and exposes them via the data catalogs. The consumers use the data catalogs to find the data they need for their application.

First, we can identify the three main components of the mesh architecture introduced before: data producers, the centralized data catalog, and data consumers.
In this specific example, we can see how different producer domains implement different storage solutions:
- The Users domain uses Amazon Aurora as its own line of business (LOB) database, a relational database (step 1a)
- Songs and Podcasts use Amazon DynamoDB, a NoSQL database (steps 1b and 1c)
- Interactions ingests the events directly into Amazon S3 (step 1d)
The producer domains are decoupling their LOB databases from the data catalogs by using Amazon Simple Storage Service (Amazon S3). With the data mesh paradigm, each producer considers the data as a product, therefore it can preprocess the data before exposing them, and store the results in a format that is suitable for the consumers. This decoupling is implemented using AWS Glue to define an extract, transform, and load (ETL) pipeline, whose results are eventually stored in S3 buckets (steps 2a, 2b, 2c).
Finally, each producer shares its respective AWS Glue Data Catalog with the Centralized Data Catalog (steps 3a, 3b, 3c, 3d).
Data consumers can now access the different data domains through the central catalog. As shown in the preceding figure, we have two consumers: the Analytics domain, which accesses certain catalogs and showcases metrics on an Amazon QuickSight dashboard (step 4), and the Personalized Recommendations domain (step 5).
The latter, which is the one of interest for this post, consists of an AWS Glue ETL job that accesses, through the central catalog, data from the different producers. The ETL job performs traditional data engineering tasks, for example merging song and podcast data. We can now generate our Amazon Personalize solution, where our items dataset includes information about both songs and podcasts, expanding the initial recommendation catalog.
Our recommendation engine is then made available for inference requests through an API deployed using Amazon API Gateway (step 6).
The architecture is designed to work across multiple accounts: an AWS account is a natural boundary for the resources deployed into it and a single unit of billing. This approach allows us to separate the resources owned by the different domains and maintain operational agility: each team owns and controls its account. To learn more about the approaches for sharing data catalogs across different accounts while working with a data mesh, check out Design a data mesh architecture using AWS Lake Formation and AWS Glue.
We’re now able to provide users with song or podcast recommendations based on their comprehensive listening preferences across the two categories. In the next section, we explore how to improve the architecture to be reactive to continuously evolving data, such as new songs added to the catalog or new interactions made available.
Architecture for data in motion
Earlier, we introduced the theoretical framework for event streaming in the context of the data mesh, defined as the data-in-motion plane. We can now drill down into the architecture for our specific use case.
We’re using a scenario with four producers (Users, Songs, Podcasts, and Interactions), the central streaming component, and two consumer domains (Personalized Recommendations and Analytics). The data-in-motion plane is implemented by using a platform for event streaming, namely Apache Kafka, and each producer has a dedicated stream to publish its events.
In the scenario of real-time recommendations for music, the Personalized Recommendations consumer is notified about changes to Users, Songs, Podcasts, and Interactions. Similar to the at-rest example, we also consider a second consumer domain, called Analytics, used to create real-time dashboards about the trends in the interactions. Here, the analytics consumer requires only interaction events, therefore it subscribes only to the Interactions stream.
This architecture is designed to offer a loosely coupled interaction mechanism for producers and consumers: the producers don’t need to know about the consumers that are part of the system. The producers focus on emitting the events, the events are sent to the data-in-motion plane, and the delivery is guaranteed by the streaming platform.
Let’s drill down into the strategy for building this architecture in the cloud. For readability purposes, we study this part of the solution in isolation, without adding to the diagram of the data-at-rest scenario.
From a technological perspective, we use AWS Lambda to run the back-end business logic of the application: the microservice runs the logic in a Lambda function and publishes events to the event streams. We use Lambda because it fits our use case well, both for scalability and operational efficiency, because it offers minimal operational overhead. However, the architecture pattern is also valid for other types of backend deployments, for example, containers running on Amazon Elastic Kubernetes Service (Amazon EKS) or Amazon Elastic Container Service (Amazon ECS).
The data-in-motion plane is implemented using Amazon Managed Streaming for Apache Kafka (Amazon MSK), a fully managed solution for running Apache Kafka in the cloud. It provisions the servers, configures the Apache Kafka clusters, replaces servers when they fail, orchestrates server patches and upgrades, and runs clusters for high availability. Kafka organizes and stores events into topics. Topics are always multi-producer and multi-consumer: this means that one or many producers can publish to the same topic, and one or many consumers can subscribe to read from the topic. We use the concept of topics to model this architecture paradigm, and we assign one topic for each producer domain.
Finally, we adapt our previously introduced consumer domain, Personalized Recommendations, to take into account real-time events. This time, we use Lambda to read the events from the topics and invoke the commands to call the Amazon Personalize API through the Amazon Personalize SDK. Within the same consumer domain, we use a Lambda function per topic, which is triggered as soon as a new event is published in the monitored topic. This event-driven pattern allows us to run code only when a new event is published and we need to update the information in Amazon Personalize. Each Lambda function in the Personalized Recommendations domain uses the Amazon Personalize SDK to invoke the corresponding actions on Amazon Personalize and update the datasets.
Let’s consider a new interaction happening in the system using the following figure. This serverless implementation of the event streaming pattern extends the data mesh to respond to real-time events.

The Interactions microservice, which is running the backend logic of the application, publishes a new event (step 1), which is persisted in the Interactions topic (step 2). The publishing of a new event triggers the Lambda functions subscribed to the topic, in this case InteractionsUpdate and InteractionsIngestor (step 3). The InteractionsUpdate function invokes the PutEvents operation on the Amazon Personalize API through the Amazon Personalize SDK to add the real-time event to the recommendation system (step 4). InteractionsIngestor triggers the operations to refresh the dashboards according to the strategy adopted by the Analytics domain. Finally, other services and components can consume the recommendations through the API exposed by the Personalized Recommendation domain to make the predictions consumable (step 5).
For the Analytics domain, which we added to showcase the scalability of this architecture, we use a Lambda function to ingest the real-time events into Amazon Kinesis Data Firehose. Then we can visualize the interactions using Amazon OpenSearch Service in conjunction with Amazon QuickSight. For more details, refer to Visualize live analytics from Amazon QuickSight connected to Amazon OpenSearch Service.
Because the data producers, Kafka resources, and data consumers are all in different accounts, we need to establish cross-account connectivity to keep the traffic within the AWS infrastructure and avoid the public internet, both for security reasons as well as cost-optimization. The objective of this post is to show the architecture and the approach to implement this pattern. If you want to dive deeper into how to establish cross-account connectivity between producers and consumers and Amazon MSK, refer to Secure connectivity patterns to access Amazon MSK and How Goldman Sachs builds cross-account connectivity to their Amazon MSK clusters with AWS Private Link.
Data mesh with event streaming: Putting it all together
Earlier, we recalled the data mesh paradigm and designed a solution to emphasize the importance of adopting a data as a product strategy. Each producer domain exposes the data via the catalog, and they are made centrally discoverable through the Centralized Data Catalog. Each consumer domain has a catalog interface for connecting to the central catalog and finding the data required to build the solution the domain focuses on.
Next, we studied the scenario for data in motion, introduced Apache Kafka and Amazon MSK to implement the event streaming platform, and connected the producers and consumers with the streaming service via Lambda. This event-driven implementation allows us to decouple the producers from the consumers, and make the solution scalable as the domains may change and evolve during time, without significant changes required in the architecture.
We can now put it all together, as shown in the following figure. The complete data mesh with event streaming architecture uses two different data planes: one is dedicated for sharing data at rest (blue); the other one is for data in motion (red).

Each domain has two interfaces required to communicate with both planes: the data catalogs and the Lambda functions. The data at rest is shared and discovered by taking advantage of the data catalogs, whereas the data in motion are emitted by the service running the backend logic in the producer domains. They’re consumed using the Lambda functions subscribed to the topics, which are deployed in the consumer domains.
Conclusion
In this post, we introduced the high-level architecture paradigm that allows you to extend the concept of a data mesh to real-time events.
We first covered the fundamental concepts associated with this architectural style, and then showcased how to apply this solution to solve real-world business challenges, such as real-time personalized recommendations and analytics, in a multi-account setting on AWS.
Furthermore, the framework presented in this post can be generalized to different domains, for example other AWS AI services such as Amazon Forecast or Amazon Comprehend, or your custom ML solutions built for your specific scenario and deployed through Amazon SageMaker. With the most experience, the most reliable, scalable and secure cloud, and the most comprehensive set of services and solutions, AWS is the best place to unlock value from your data.
More resources:
About the authors
 Vittorio Denti is a Solutions Architect at AWS based in London. After completing his M.Sc. in Computer Science and Engineering at Politecnico di Milano (Milan) and the KTH Royal Institute of Technology (Stockholm), he joined AWS. Vittorio has a background in Distributed Systems and Machine Learning, and a strong interest in cloud technologies. He’s especially passionate for software engineering, building ML models, and putting ML into production.
Vittorio Denti is a Solutions Architect at AWS based in London. After completing his M.Sc. in Computer Science and Engineering at Politecnico di Milano (Milan) and the KTH Royal Institute of Technology (Stockholm), he joined AWS. Vittorio has a background in Distributed Systems and Machine Learning, and a strong interest in cloud technologies. He’s especially passionate for software engineering, building ML models, and putting ML into production.
 Anna Grüebler is a Specialist Solutions Architect at AWS focusing on in Artificial Intelligence. She has more than 10 years experience helping customers develop and deploy machine learning applications. Her passion is taking new technologies and putting them in the hands of everyone, and solving difficult problems leveraging the advantages of using AI in the cloud.
Anna Grüebler is a Specialist Solutions Architect at AWS focusing on in Artificial Intelligence. She has more than 10 years experience helping customers develop and deploy machine learning applications. Her passion is taking new technologies and putting them in the hands of everyone, and solving difficult problems leveraging the advantages of using AI in the cloud.

