ONX(Öffnen Sie den Austausch neuronaler Netze) ist ein Open-Source-Standard zur Darstellung von Deep-Learning-Modellen, der von vielen Anbietern weitgehend unterstützt wird. ONNX bietet Tools zur Optimierung und Quantisierung von Modellen, um den Speicher- und Rechenaufwand für die Ausführung von Modellen für maschinelles Lernen (ML) zu reduzieren. Einer der größten Vorteile von ONNX besteht darin, dass es ein standardisiertes Format für die Darstellung und den Austausch von ML-Modellen zwischen verschiedenen Frameworks und Tools bietet. Dadurch können Entwickler ihre Modelle in einem Framework trainieren und in einem anderen bereitstellen, ohne dass eine umfangreiche Modellkonvertierung oder Neuschulung erforderlich ist. Aus diesen Gründen hat ONNX in der ML-Community erheblich an Bedeutung gewonnen.
In diesem Beitrag zeigen wir, wie ONNX-basierte Modelle für Multi-Model-Endpunkte (MMEs) bereitgestellt werden, die GPUs verwenden. Dies ist eine Fortsetzung des Beitrags Führen Sie mehrere Deep-Learning-Modelle auf der GPU mit Amazon SageMaker-Multimodell-Endpunkten aus, wo wir gezeigt haben, wie PyTorch- und TensorRT-Versionen von ResNet50-Modellen auf dem Triton-Inferenzserver von Nvidia bereitgestellt werden. In diesem Beitrag verwenden wir dasselbe ResNet50-Modell im ONNX-Format zusammen mit einem zusätzlichen Beispielmodell für die Verarbeitung natürlicher Sprache (NLP) im ONNX-Format, um zu zeigen, wie es auf Triton bereitgestellt werden kann. Darüber hinaus vergleichen wir das ResNet50-Modell und sehen die Leistungsvorteile, die ONNX im Vergleich zu PyTorch- und TensorRT-Versionen desselben Modells mit derselben Eingabe bietet.

ONNX-Laufzeit
ONNX-Laufzeit ist eine Laufzeit-Engine für ML-Inferenz, die darauf ausgelegt ist, die Leistung von Modellen auf mehreren Hardwareplattformen, einschließlich CPUs und GPUs, zu optimieren. Es ermöglicht die Verwendung von ML-Frameworks wie PyTorch und TensorFlow. Es erleichtert Leistungsoptimierung ermöglicht die kosteneffiziente Ausführung von Modellen auf der Zielhardware und unterstützt Funktionen wie Quantisierung und Hardwarebeschleunigung, was es zu einer idealen Wahl für die Bereitstellung effizienter, leistungsstarker ML-Anwendungen macht. Beispiele dafür, wie ONNX-Modelle mit TensorRT für Nvidia-GPUs optimiert werden können, finden Sie unter TensorRT-Optimierung (ORT-TRT) und ONNX Runtime mit TensorRT-Optimierung.
Das Amazon Sage Maker Triton-Behälter Der Durchfluss ist im folgenden Diagramm dargestellt.

Benutzer können eine HTTPS-Anfrage mit der Eingabenutzlast für Echtzeit-Inferenz hinter einem SageMaker-Endpunkt senden. Der Benutzer kann a angeben TargetModel Header, der den Namen des Modells enthält, das die betreffende Anforderung aufrufen soll. Intern implementiert der SageMaker Triton-Container einen HTTP-Server mit denselben Verträgen wie in erwähnt Wie Container Anfragen bedienen. Es unterstützt dynamisches Batching und unterstützt alle Backends, die Triton bereitstellt. Basierend auf der Konfiguration wird die ONNX-Laufzeit aufgerufen und die Anfrage auf der CPU oder GPU verarbeitet, wie in der vom Benutzer bereitgestellten Modellkonfiguration vordefiniert.
Lösungsüberblick
Um das ONNX-Backend zu verwenden, führen Sie die folgenden Schritte aus:
- Kompilieren Sie das Modell im ONNX-Format.
- Konfigurieren Sie das Modell.
- Erstellen Sie den SageMaker-Endpunkt.
Voraussetzungen:
Stellen Sie sicher, dass Sie ausreichend Zugriff auf ein AWS-Konto haben AWS Identity and Access Management and IAM-Berechtigungen zum Erstellen eines Notizbuchs, Zugriff auf ein Amazon Simple Storage-Service (Amazon S3)-Bucket und stellen Sie Modelle auf SageMaker-Endpunkten bereit. Sehen Erstellen Sie eine Ausführungsrolle um mehr zu erfahren.
Kompilieren Sie das Modell im ONNX-Format
Die Transformers-Bibliothek bietet eine praktische Methode zum Kompilieren des PyTorch-Modells in das ONNX-Format. Der folgende Code führt die Transformationen für das NLP-Modell durch:
Der Export von Modellen (entweder PyTorch oder TensorFlow) ist einfach über das Konvertierungstool möglich, das im Hugging Face-Transformer-Repository enthalten ist.
Folgendes passiert unter der Haube:
- Ordnen Sie das Modell von Transformatoren (PyTorch oder TensorFlow) zu.
- Leiten Sie Dummy-Eingaben über das Modell weiter. Auf diese Weise kann ONNX die Anzahl der ausgeführten Vorgänge aufzeichnen.
- Die Transformatoren kümmern sich beim Exportieren des Modells automatisch um dynamische Achsen.
- Speichern Sie das Diagramm zusammen mit den Netzwerkparametern.
Ein ähnlicher Mechanismus wird für den Computer-Vision-Anwendungsfall aus dem Torchvision-Modellzoo verfolgt:
Konfigurieren Sie das Modell
In diesem Abschnitt konfigurieren wir das Computer Vision- und NLP-Modell. Wir zeigen, wie Sie mithilfe von Triton Inference Server-Modellkonfigurationen ein großes ResNet50- und RoBERTA-Modell erstellen, das für die Bereitstellung auf einem SageMaker MME vorab trainiert wurde. Das ResNet50-Notebook ist verfügbar unter GitHub. Das RoBERTA-Notizbuch ist auch auf erhältlich GitHub. Für ResNet50 verwenden wir den Docker-Ansatz, um eine Umgebung zu erstellen, die bereits über alle Abhängigkeiten verfügt, die zum Erstellen unseres ONNX-Modells und zum Generieren der für diese Übung erforderlichen Modellartefakte erforderlich sind. Dieser Ansatz macht es viel einfacher, Abhängigkeiten zu teilen und genau die Umgebung zu schaffen, die zur Erfüllung dieser Aufgabe erforderlich ist.
Der erste Schritt besteht darin, das ONNX-Modellpaket gemäß der in angegebenen Verzeichnisstruktur zu erstellen ONNX-Modelle. Unser Ziel ist es, das minimale Modell-Repository für ein ONNX-Modell zu verwenden, das in einer einzelnen Datei wie folgt enthalten ist:
Als nächstes erstellen wir die Modellkonfiguration Datei, die die Eingaben, Ausgaben und Backend-Konfigurationen für den Triton Server beschreibt, um die entsprechenden Kernel für ONNX abzurufen und aufzurufen. Diese Datei heißt config.pbtxt und wird im folgenden Code für den RoBERTA-Anwendungsfall gezeigt. Notiere dass der BATCH Die Dimension wird weggelassen config.pbtxt. Beim Senden der Daten an das Modell beziehen wir jedoch die Batch-Dimension mit ein. Der folgende Code zeigt außerdem, wie Sie diese Funktion mit Modellkonfigurationsdateien hinzufügen können, um die dynamische Stapelverarbeitung mit einer bevorzugten Stapelgröße von 5 für die eigentliche Inferenz festzulegen. Mit den aktuellen Einstellungen wird die Modellinstanz sofort aufgerufen, wenn die bevorzugte Batch-Größe von 5 erreicht ist oder die Verzögerungszeit von 100 Mikrosekunden abgelaufen ist, seit die erste Anforderung den dynamischen Batcher erreicht hat.
Im Folgenden finden Sie eine ähnliche Konfigurationsdatei für den Anwendungsfall Computer Vision:
Erstellen Sie den SageMaker-Endpunkt
Wir verwenden die Boto3-APIs, um den SageMaker-Endpunkt zu erstellen. In diesem Beitrag zeigen wir die Schritte für das RoBERTA-Notebook. Dies sind jedoch allgemeine Schritte und gelten auch für das ResNet50-Modell.
Erstellen Sie ein SageMaker-Modell
Wir erstellen jetzt eine SageMaker-Modell. Wir benutzen das Amazon Elastic Container-Registrierung (Amazon ECR)-Bild und das Modellartefakt aus dem vorherigen Schritt, um das SageMaker-Modell zu erstellen.
Erstellen Sie den Behälter
Um den Container zu erstellen, ziehen wir den passendes Bild von Amazon ECR für Triton Server. Mit SageMaker können wir verschiedene Umgebungsvariablen anpassen und einfügen. Zu den wichtigsten Funktionen gehört die Möglichkeit, Folgendes festzulegen BATCH_SIZE; Wir können dies pro Modell im festlegen config.pbtxt Datei, oder wir können hier einen Standardwert definieren. Für Modelle, die von einer größeren gemeinsamen Speichergröße profitieren können, können wir diese Werte unten festlegen SHM Variablen. Um die Protokollierung zu aktivieren, legen Sie das Protokoll fest verbose Ebene zu true. Wir verwenden den folgenden Code, um das Modell zur Verwendung in unserem Endpunkt zu erstellen:
Erstellen Sie einen SageMaker-Endpunkt
Sie können zum Testen beliebige Instanzen mit mehreren GPUs verwenden. In diesem Beitrag verwenden wir eine g4dn.4xlarge-Instanz. Wir legen das nicht fest VolumeSizeInGB Parameter, da diese Instanz über lokalen Instanzspeicher verfügt. Der VolumeSizeInGB Der Parameter gilt für GPU-Instanzen, die Folgendes unterstützen Amazon Elastic Block-Shop (Amazon EBS) Volumenanhang. Wir können das Modell-Download-Timeout und die Integritätsprüfung des Container-Starts auf den Standardwerten belassen. Weitere Einzelheiten finden Sie unter CreateEndpointConfig.
Zuletzt erstellen wir einen SageMaker-Endpunkt:
Rufen Sie den Modellendpunkt auf
Dies ist ein generatives Modell, also übergeben wir das input_ids und attention_mask als Teil der Nutzlast an das Modell gesendet. Der folgende Code zeigt, wie die Tensoren erstellt werden:
Wir erstellen nun die entsprechende Nutzlast, indem wir sicherstellen, dass der Datentyp mit dem übereinstimmt, was wir im konfiguriert haben config.pbtxt. Dadurch erhalten wir auch die Tensoren inklusive der Batch-Dimension, was Triton erwartet. Wir verwenden das JSON-Format, um das Modell aufzurufen. Triton bietet außerdem eine native binäre Aufrufmethode für das Modell.
Beachten Sie das TargetModel Parameter im vorangehenden Code. Wir senden den Namen des aufzurufenden Modells als Anforderungsheader, da es sich um einen Endpunkt mit mehreren Modellen handelt. Daher können wir zur Laufzeit mehrere Modelle auf einem bereits bereitgestellten Inferenzendpunkt aufrufen, indem wir diesen Parameter ändern. Dies zeigt die Leistungsfähigkeit von Endpunkten mit mehreren Modellen!
Um die Antwort auszugeben, können wir den folgenden Code verwenden:
ONNX zur Leistungsoptimierung
Das ONNX-Backend verwendet die C++-Arena-Speicherzuweisung. Die Arena-Zuweisung ist eine reine C++-Funktion, die Ihnen hilft, Ihre Speichernutzung zu optimieren und die Leistung zu verbessern. Die Speicherzuweisung und -freigabe macht einen erheblichen Teil der CPU-Zeit aus, die im Protokollpuffercode aufgewendet wird. Standardmäßig führt die Erstellung neuer Objekte Heap-Zuweisungen für jedes Objekt, jedes seiner Unterobjekte und mehrere Feldtypen, z. B. Zeichenfolgen, durch. Diese Zuordnungen erfolgen in großen Mengen beim Parsen einer Nachricht und beim Erstellen neuer Nachrichten im Speicher, und zugehörige Freigaben erfolgen, wenn Nachrichten und ihre Unterobjektbäume freigegeben werden.
Die Arena-basierte Zuteilung wurde entwickelt, um diese Leistungskosten zu reduzieren. Bei der Arena-Zuweisung werden neue Objekte aus einem großen Teil des vorab zugewiesenen Speichers zugewiesen, der als „Arena Allocation“ bezeichnet wird Arena. Objekte können alle auf einmal freigegeben werden, indem die gesamte Arena verworfen wird, idealerweise ohne die Ausführung von Destruktoren für enthaltene Objekte (obwohl eine Arena bei Bedarf immer noch eine Destruktorliste verwalten kann). Dadurch wird die Objektzuweisung beschleunigt, indem sie auf ein einfaches Zeigerinkrement reduziert wird, und die Aufhebung der Zuweisung ist nahezu kostenlos. Die Arena-Zuweisung sorgt auch für eine höhere Cache-Effizienz: Wenn Nachrichten analysiert werden, ist es wahrscheinlicher, dass sie im kontinuierlichen Speicher zugewiesen werden, wodurch es beim Durchlaufen von Nachrichten wahrscheinlicher wird, dass sie auf Hot-Cache-Zeilen treffen. Der Nachteil der Arena-basierten Zuweisung besteht darin, dass der C++-Heapspeicher überbelegt wird und auch nach der Freigabe der Objekte weiterhin zugewiesen bleibt. Dies kann dazu führen, dass nicht genügend Arbeitsspeicher oder eine hohe CPU-Speicherauslastung vorhanden ist. Um das Beste aus beiden Welten zu erreichen, verwenden wir die folgenden Konfigurationen von Triton und ONNX:
- arena_extend_strategy – Dieser Parameter bezieht sich auf die Strategie, die zum Erweitern des Speicherbereichs im Hinblick auf die Größe des Modells verwendet wird. Wir empfehlen, den Wert auf 1 (=) zu setzen
kSameAsRequested), was kein Standardwert ist. Die Begründung lautet wie folgt: Der Nachteil der standardmäßigen Arena-Extend-Strategie (kNextPowerOfTwo) besteht darin, dass möglicherweise mehr Speicher als nötig zugewiesen wird, was eine Verschwendung sein könnte. Wie der Name schon sagt,kNextPowerOfTwo(Standardeinstellung) erweitert die Arena um eine Potenz von 2, wohingegenkSameAsRequestedverlängert sich jedes Mal um eine Größe, die der Größe der Zuteilungsanforderung entspricht.kSameAsRequestedeignet sich für erweiterte Konfigurationen, bei denen Sie die erwartete Speichernutzung im Voraus kennen. Da wir bei unseren Tests wissen, dass die Größe der Modelle ein konstanter Wert ist, können wir eine sichere Auswahl treffenkSameAsRequested. - gpu_mem_limit – Wir setzen den Wert auf das CUDA-Speicherlimit. Um den gesamten möglichen Speicher zu nutzen, übergeben Sie das Maximum
size_t. Es ist standardmäßigSIZE_MAXwenn nichts angegeben ist. Wir empfehlen, die Standardeinstellung beizubehalten. - enable_cpu_mem_arena – Dies aktiviert den Speicherbereich auf der CPU. Die Arena kann Speicher für die zukünftige Nutzung vorab zuweisen. Setzen Sie diese Option auf
falsewenn du es nicht willst. Die Standardeinstellung istTrue. Wenn Sie die Arena deaktivieren, dauert die Heap-Speicherzuweisung einige Zeit, sodass sich die Inferenzlatenz erhöht. In unseren Tests haben wir es als Standardeinstellung belassen. - enable_mem_pattern – Dieser Parameter bezieht sich auf die interne Speicherzuweisungsstrategie basierend auf Eingabeformen. Wenn die Formen konstant sind, können wir diesen Parameter aktivieren, um ein Speichermuster für die Zukunft zu generieren und etwas Zuweisungszeit zu sparen, wodurch es schneller geht. Verwenden Sie 1, um das Speichermuster zu aktivieren, und 0, um es zu deaktivieren. Es wird empfohlen, diesen Wert auf 1 zu setzen, wenn erwartet wird, dass die Eingabefunktionen gleich sind. Der Standardwert ist 1.
- do_copy_in_default_stream – Im Kontext des CUDA-Ausführungsanbieters in ONNX ist ein Compute-Stream eine Folge von CUDA-Vorgängen, die asynchron auf der GPU ausgeführt werden. Die ONNX-Laufzeit plant Vorgänge in verschiedenen Streams basierend auf ihren Abhängigkeiten, was dazu beiträgt, die Leerlaufzeit der GPU zu minimieren und eine bessere Leistung zu erzielen. Wir empfehlen, die Standardeinstellung 1 zu verwenden, um denselben Stream zum Kopieren und Berechnen zu verwenden. Sie können jedoch 0 verwenden, um separate Streams zum Kopieren und Berechnen zu verwenden, was dazu führen kann, dass das Gerät die beiden Aktivitäten per Pipeline verarbeitet. Bei unserem Test des ResNet50-Modells haben wir sowohl 0 als auch 1 verwendet, konnten jedoch keinen nennenswerten Unterschied zwischen den beiden in Bezug auf Leistung und Speicherverbrauch des GPU-Geräts feststellen.
- Diagrammoptimierung – Das ONNX-Backend für Triton unterstützt mehrere Parameter, die bei der Feinabstimmung der Modellgröße sowie der Laufzeitleistung des bereitgestellten Modells helfen. Wenn das Modell in die ONNX-Darstellung konvertiert wird (das erste Feld im folgenden Diagramm in der IR-Stufe), bietet die ONNX-Laufzeit Diagrammoptimierungen auf drei Ebenen: grundlegende, erweiterte und Layoutoptimierungen. Sie können alle Ebenen der Diagrammoptimierung aktivieren, indem Sie die folgenden Parameter in der Modellkonfigurationsdatei hinzufügen:
- cudnn_conv_algo_search – Da wir in unseren Tests CUDA-basierte Nvidia-GPUs verwenden, können wir für unseren Computer-Vision-Anwendungsfall mit dem ResNet50-Modell die auf dem CUDA-Ausführungsanbieter basierende Optimierung auf der vierten Ebene im folgenden Diagramm mit verwenden
cudnn_conv_algo_searchParameter. Die Standardoption ist erschöpfend (0), aber als wir diese Konfiguration in geändert haben1 – HEURISTIChaben wir gesehen, dass sich die Modelllatenz im eingeschwungenen Zustand auf 160 Millisekunden reduziert hat. Der Grund dafür ist, dass die ONNX-Laufzeit das geringere Gewicht aufruft cudnnGetConvolutionForwardAlgorithm_v7 Vorwärtspass und reduziert daher die Latenz bei ausreichender Leistung. - Run-Modus – Der nächste Schritt ist die Auswahl des Richtigen Ausführungsmodus auf Ebene 5 im folgenden Diagramm. Dieser Parameter steuert, ob Sie Operatoren in Ihrem Diagramm sequentiell oder parallel ausführen möchten. Wenn das Modell viele Zweige hat, wird diese Option normalerweise auf eingestellt
ExecutionMode.ORT_PARALLEL(1) sorgt für eine bessere Leistung. In dem Szenario, in dem Ihr Modell viele Verzweigungen in seinem Diagramm aufweist, trägt die Einstellung des Ausführungsmodus auf „Parallel“ zu einer besseren Leistung bei. Der Standardmodus ist sequentiell, sodass Sie ihn entsprechend Ihren Anforderungen aktivieren können.
Ein tieferes Verständnis der Möglichkeiten zur Leistungsoptimierung in ONNX finden Sie in der folgenden Abbildung.

Benchmark-Zahlen und Leistungsoptimierung
Indem Sie die Diagrammoptimierungen aktivieren, cudnn_conv_algo_searchIn unserem Test des ResNet50-Modells haben wir festgestellt, dass sich die Kaltstartzeit des ONNX-Modelldiagramms aufgrund der Parameter und Parameter des Parallellaufmodus von 4.4 Sekunden auf 1.61 Sekunden verringert hat. Ein Beispiel für eine vollständige Modellkonfigurationsdatei finden Sie im folgenden Abschnitt zur ONNX-Konfiguration Notizbuch.
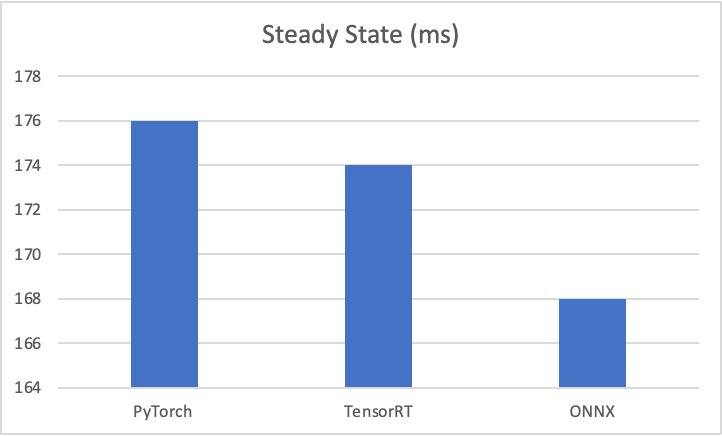
Die Test-Benchmark-Ergebnisse lauten wie folgt:
- PyTorch – 176 Millisekunden, Kaltstart 6 Sekunden
- TensorRT – 174 Millisekunden, Kaltstart 4.5 Sekunden
- ONNX – 168 Millisekunden, Kaltstart 4.4 Sekunden
Die folgenden Diagramme veranschaulichen diese Kennzahlen.


Darüber hinaus sollten Sie bei unseren Tests von Computer-Vision-Anwendungsfällen das Senden der Anforderungsnutzlast im Binärformat mithilfe des von Triton bereitgestellten HTTP-Clients in Betracht ziehen, da dies die Modellaufruflatenz erheblich verbessert.
Weitere Parameter, die SageMaker für ONNX auf Triton bereitstellt, sind wie folgt:
- Dynamische Stapelverarbeitung – Dynamisches Batching ist eine Funktion von Triton, die es ermöglicht, Inferenzanfragen vom Server zu kombinieren, sodass ein Batch dynamisch erstellt wird. Das Erstellen eines Stapels von Anforderungen führt normalerweise zu einem höheren Durchsatz. Der dynamische Batcher sollte für zustandslose Modelle verwendet werden. Die dynamisch erstellten Stapel werden an alle für das Modell konfigurierten Modellinstanzen verteilt.
- Maximale Chargengröße - Die
max_batch_sizeDie Eigenschaft gibt die maximale Batchgröße an, die das Modell für unterstützt Arten der Dosierung das kann Triton ausnutzen. Wenn die Batch-Dimension des Modells die erste Dimension ist und alle Eingaben und Ausgaben des Modells diese Batch-Dimension haben, kann Triton diese verwenden dynamischer Batcher or Sequenz-Batcher um automatisch die Stapelverarbeitung mit dem Modell zu verwenden. In diesem Fall,max_batch_sizesollte auf einen Wert größer oder gleich 1 eingestellt werden, der die maximale Batchgröße angibt, die Triton mit dem Modell verwenden sollte. - Standardmäßige maximale Batchgröße – Für wird der Wert „Default-Max-Batch-Size“ verwendet
max_batch_sizeim Autovervollständigen wenn kein anderer Wert gefunden wird. DeronnxruntimeDas Backend wird das festlegenmax_batch_sizedes Modells auf diesen Standardwert, wenn die automatische Vervollständigung festgestellt hat, dass das Modell in der Lage ist, Anfragen in Stapeln zu verarbeiten undmax_batch_sizeist in der Modellkonfiguration 0 odermax_batch_sizewird in der Modellkonfiguration weggelassen. Wennmax_batch_sizeist mehr als 1 und nein Scheduler bereitgestellt wird, wird der dynamische Batch-Scheduler verwendet. Die standardmäßige maximale Batchgröße beträgt 4.
Aufräumen
Stellen Sie sicher, dass Sie das Modell, die Modellkonfiguration und den Modellendpunkt löschen, nachdem Sie das Notebook ausgeführt haben. Die Schritte dazu finden Sie am Ende des Beispielnotizbuchs im GitHub Repo.
Zusammenfassung
In diesem Beitrag haben wir uns eingehend mit dem ONNX-Backend befasst, das Triton Inference Server auf SageMaker unterstützt. Dieses Backend sorgt für die GPU-Beschleunigung Ihrer ONNX-Modelle. Um die beste Leistung für die Inferenz zu erzielen, müssen viele Optionen in Betracht gezogen werden, z. B. Batchgrößen, Dateneingabeformate und andere Faktoren, die an Ihre Anforderungen angepasst werden können. Mit SageMaker können Sie diese Funktion mithilfe von Endpunkten mit einem oder mehreren Modellen nutzen. MMEs ermöglichen ein besseres Gleichgewicht zwischen Leistung und Kosteneinsparungen. Informationen zu den ersten Schritten mit der MME-Unterstützung für GPU finden Sie unter Hosten Sie mehrere Modelle in einem Container hinter einem Endpunkt.
Wir laden Sie ein, Triton Inference Server-Container in SageMaker auszuprobieren und Ihr Feedback und Ihre Fragen in den Kommentaren zu teilen.
Über die Autoren
 Abhi Shivaditya ist Senior Solutions Architect bei AWS und arbeitet mit strategischen globalen Unternehmensorganisationen zusammen, um die Einführung von AWS-Services in Bereichen wie künstliche Intelligenz, verteiltes Computing, Netzwerk und Speicher zu erleichtern. Seine Expertise liegt im Deep Learning in den Bereichen Natural Language Processing (NLP) und Computer Vision. Abhi unterstützt Kunden bei der effizienten Bereitstellung leistungsstarker Modelle für maschinelles Lernen innerhalb des AWS-Ökosystems.
Abhi Shivaditya ist Senior Solutions Architect bei AWS und arbeitet mit strategischen globalen Unternehmensorganisationen zusammen, um die Einführung von AWS-Services in Bereichen wie künstliche Intelligenz, verteiltes Computing, Netzwerk und Speicher zu erleichtern. Seine Expertise liegt im Deep Learning in den Bereichen Natural Language Processing (NLP) und Computer Vision. Abhi unterstützt Kunden bei der effizienten Bereitstellung leistungsstarker Modelle für maschinelles Lernen innerhalb des AWS-Ökosystems.
 James Park ist Lösungsarchitekt bei Amazon Web Services. Er arbeitet mit Amazon.com zusammen, um Technologielösungen auf AWS zu entwerfen, zu erstellen und bereitzustellen, und hat ein besonderes Interesse an KI und maschinellem Lernen. In seiner Freizeit erkundet er gerne neue Kulturen, neue Erfahrungen und bleibt über die neuesten Technologietrends auf dem Laufenden. Sie finden ihn auf LinkedIn.
James Park ist Lösungsarchitekt bei Amazon Web Services. Er arbeitet mit Amazon.com zusammen, um Technologielösungen auf AWS zu entwerfen, zu erstellen und bereitzustellen, und hat ein besonderes Interesse an KI und maschinellem Lernen. In seiner Freizeit erkundet er gerne neue Kulturen, neue Erfahrungen und bleibt über die neuesten Technologietrends auf dem Laufenden. Sie finden ihn auf LinkedIn.
 Rupinder Grewal ist ein Sr Ai/ML Specialist Solutions Architect bei AWS. Derzeit konzentriert er sich auf die Bereitstellung von Modellen und MLOps auf SageMaker. Vor dieser Funktion hat er als Machine Learning Engineer gearbeitet und Modelle erstellt und gehostet. Außerhalb der Arbeit spielt er gerne Tennis und radelt auf Bergpfaden.
Rupinder Grewal ist ein Sr Ai/ML Specialist Solutions Architect bei AWS. Derzeit konzentriert er sich auf die Bereitstellung von Modellen und MLOps auf SageMaker. Vor dieser Funktion hat er als Machine Learning Engineer gearbeitet und Modelle erstellt und gehostet. Außerhalb der Arbeit spielt er gerne Tennis und radelt auf Bergpfaden.
 Dhawal Patel ist Principal Machine Learning Architect bei AWS. Er hat mit Organisationen von großen Unternehmen bis hin zu mittelständischen Startups an Problemen im Zusammenhang mit verteiltem Computing und künstlicher Intelligenz gearbeitet. Er konzentriert sich auf Deep Learning, einschließlich NLP- und Computer Vision-Domänen. Er hilft Kunden, hochleistungsfähige Modellinferenz auf SageMaker zu erreichen.
Dhawal Patel ist Principal Machine Learning Architect bei AWS. Er hat mit Organisationen von großen Unternehmen bis hin zu mittelständischen Startups an Problemen im Zusammenhang mit verteiltem Computing und künstlicher Intelligenz gearbeitet. Er konzentriert sich auf Deep Learning, einschließlich NLP- und Computer Vision-Domänen. Er hilft Kunden, hochleistungsfähige Modellinferenz auf SageMaker zu erreichen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- EVM-Finanzen. Einheitliche Schnittstelle für dezentrale Finanzen. Hier zugreifen.
- Quantum Media Group. IR/PR verstärkt. Hier zugreifen.
- PlatoAiStream. Web3-Datenintelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/host-ml-models-on-amazon-sagemaker-using-triton-onnx-models/

