A massive amount of business documents are processed daily across industries. Many of these documents are paper-based, scanned into your system as images, or in an unstructured format like PDF. Each company may apply unique rules associated with its business background while processing these documents. How to extract information accurately and process them flexibly is a challenge many companies face.
Amazon Intelligent Document Processing (IDP) allows you to take advantage of industry-leading machine learning (ML) technology without previous ML experience. This post introduces a solution included in the Amazon IDP workshop showcasing how to process documents to serve flexible business rules using Amazon AI services. You can use the following step-by-step Jupyter notebook to complete the lab.
Amazon Textract helps you easily extract text from various documents, and Amazon Augmented AI (Amazon A2I) allows you to implement a human review of ML predictions. The default Amazon A2I template allows you to build a human review pipeline based on rules, such as when the extraction confidence score is lower than a pre-defined threshold or required keys are missing. But in a production environment, you need the document processing pipeline to support flexible business rules, such as validating the string format, verifying the data type and range, and validating fields across documents. This post shows how you can use Amazon Textract and Amazon A2I to customize a generic document processing pipeline supporting flexible business rules.
Solution overview
For our sample solution, we use the Tax Form 990, a US IRS (Internal Revenue Service) form that provides the public with financial information about a non-profit organization. For this example, we only cover the extraction logic for some of the fields on the first page of the form. You can find more sample documents on the IRS website.
The following diagram illustrates the IDP pipeline that supports customized business rules with human review.
The architecture is composed of three logical stages:
- Extraction – Extract data from the 990 Tax Form (we use page 1 as an example).
- Retrieve a sample image stored in an Amazon Simple Storage Service (Amazon S3) bucket.
- Call the Amazon Textract analyze_document API using the Queries feature to extract text from the page.
- Validation – Apply flexible business rules with a human-in-the-loop review.
- Validate the extracted data against business rules, such as validating the length of an ID field.
- Send the document to Amazon A2I for a human to review if any business rules fail.
- Reviewers use the Amazon A2I UI (a customizable website) to verify the extraction result.
- BI visualization – We use Amazon QuickSight to build a business intelligence (BI) dashboard showing the process insights.
Customize business rules
You can define a generic business rule in the following JSON format. In the sample code, we define three rules:
- The first rule is for the employer ID field. The rule fails if the Amazon Textract confidence score is lower than 99%. For this post, we set the confidence score threshold high, which will break by design. You could adjust the threshold to a more reasonable value to reduce unnecessary human effort in a real-world environment, such as 90%.
- The second rule is for the DLN field (the unique identifier of the tax form), which is required for the downstream processing logic. This rule fails if the DLN field is missing or has an empty value.
- The third rule is also for the DLN field but with a different condition type: LengthCheck. The rule breaks if the DLN length is not 16 characters.
The following code shows our business rules in JSON format:
You can expand the solution by adding more business rules following the same structure.
Extract text using an Amazon Textract query
In the sample solution, we call the Amazon Textract analyze_document API query feature to extract fields by asking specific questions. You don’t need to know the structure of the data in the document (table, form, implied field, nested data) or worry about variations across document versions and formats. Queries use a combination of visual, spatial, and language cues to extract the information you seek with high accuracy.
To extract value for the DLN field, you can send a request with questions in natural languages, such as “What is the DLN?” Amazon Textract returns the text, confidence, and other metadata if it finds corresponding information on the image or document. The following is an example of an Amazon Textract query request:
Define the data model
The sample solution constructs the data in a structured format to serve the generic business rule evaluation. To keep extracted values, you can define a data model for each document page. The following image shows how the text on page 1 maps to the JSON fields.
Each field represents a document’s text, check box, or table/form cell on the page. The JSON object looks like the following code:
You can find the detailed JSON structure definition in the GitHub repo.
Evaluate the data against business rules
The sample solution comes with a Condition class—a generic rules engine that takes the extracted data (as defined in the data model) and the rules (as defined in the customized business rules). It returns two lists with failed and satisfied conditions. We can use the result to decide if we should send the document to Amazon A2I for human review.
The Condition class source code is in the sample GitHub repo. It supports basic validation logic, such as validating a string’s length, value range, and confidence score threshold. You can modify the code to support more condition types and complex validation logic.
Create a customized Amazon A2I web UI
Amazon A2I allows you to customize the reviewer’s web UI by defining a worker task template. The template is a static webpage in HTML and JavaScript. You can pass data to the customized reviewer page using the Liquid syntax.
In the sample solution, the custom Amazon A2I UI template displays the page on the left and the failure conditions on the right. Reviewers can use it to correct the extraction value and add their comments.
The following screenshot shows our customized Amazon A2I UI. It shows the original image document on the left and the following failed conditions on the right:
- The DLN numbers should be 16 characters long. The actual DLN has 15 characters.
- The confidence score of employer_id is lower than 99%. The actual confidence score is around 98%.
The reviewers can manually verify these results and add comments in the CHANGE REASON text boxes.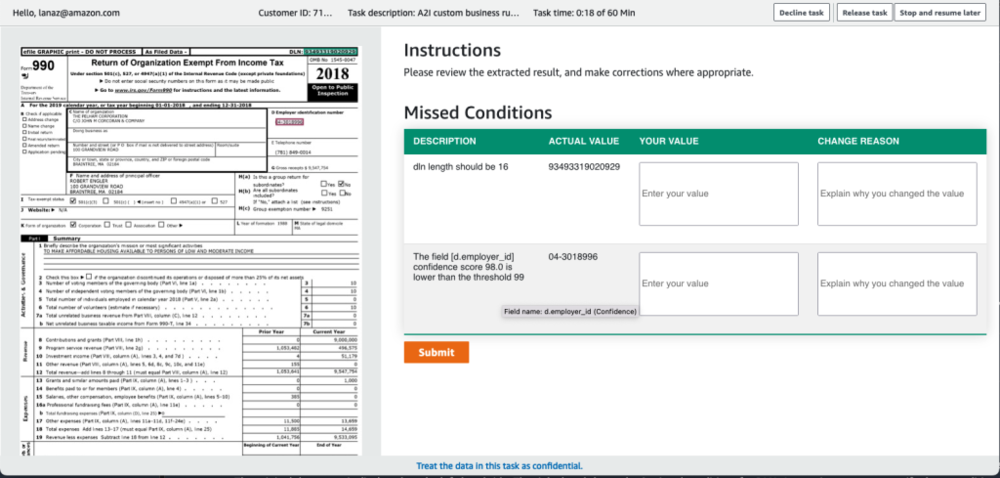
For more information about integrating Amazon A2I into any custom ML workflow, refer to over 60 pre-built worker templates on the GitHub repo and Use Amazon Augmented AI with Custom Task Types.
Process the Amazon A2I output
After the reviewer using the Amazon A2I customized UI verifies the result and chooses Submit, Amazon A2I stores a JSON file in the S3 bucket folder. The JSON file includes the following information on the root level:
- The Amazon A2I flow definition ARN and human loop name
- Human answers (the reviewer’s input collected by the customized Amazon A2I UI)
- Input content (the original data sent to Amazon A2I when starting the human loop task)
The following is a sample JSON generated by Amazon A2I:
You can implement extract, transform, and load (ETL) logic to parse information from the Amazon A2I output JSON and store it in a file or database. The sample solution comes with a CSV file with processed data. You can use it to build a BI dashboard by following the instructions in the next section.
Create a dashboard in Amazon QuickSight
The sample solution includes a reporting stage with a visualization dashboard served by Amazon QuickSight. The BI dashboard shows key metrics such as the number of documents processed automatically or manually, the most popular fields that required human review, and other insights. This dashboard can help you get an oversight of the document processing pipeline and analyze the common reasons causing human review. You can optimize the workflow by further reducing human input.
The sample dashboard includes basic metrics. You can expand the solution using Amazon QuickSight to show more insights into the data.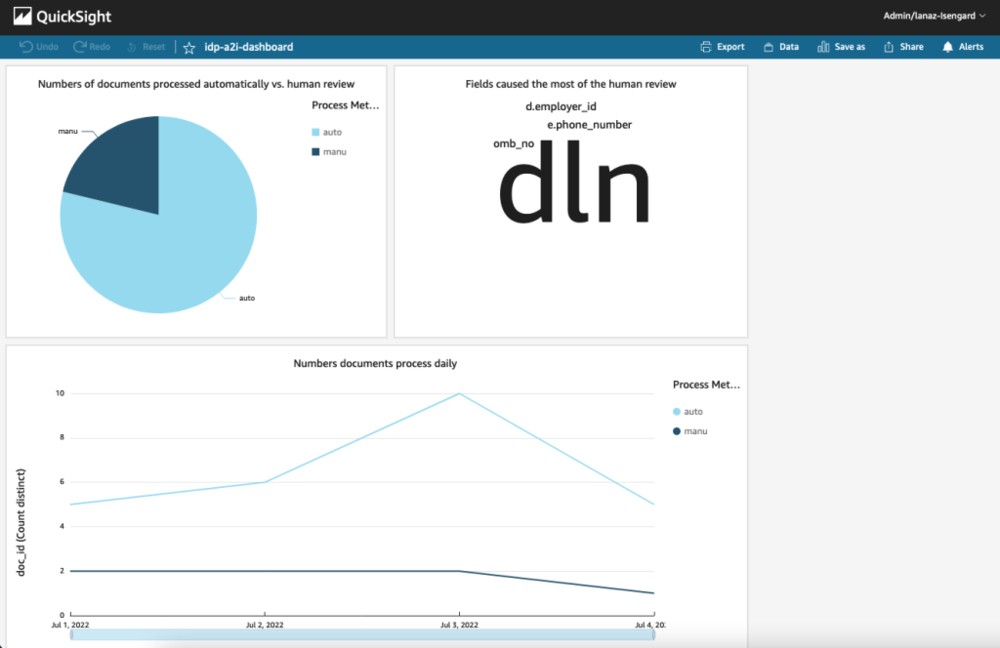
Expand the solution to support more documents and business rules
To expand the solution to support more document pages with corresponding business rules, you need to make the following changes:
- Create a data model for the new page in JSON structure representing all the values you want to extract out of the pages. Refer to the Define the data model section for a detailed format.
- Use Amazon Textract to extract text out of the document and populate values to the data model.
- Add business rules corresponding to the page in JSON format. Refer to the Customize business rules section for the detailed format.
The custom Amazon A2I UI in the solution is generic, which doesn’t require a change to support new business rules.
Conclusion
Intelligent document processing is in high demand, and companies need a customized pipeline to support their unique business logic. Amazon A2I also offers a built-in template integrated with Amazon Textract to implement your human review use cases. It also allows you to customize the reviewer page to serve flexible requirements.
This post guided you through a reference solution using Amazon Textract and Amazon A2I to build an IDP pipeline that supports flexible business rules. You can try it out using the Jupyter notebook in the GitHub IDP workshop repo.
About the authors
 Lana Zhang is a Sr. Solutions Architect at the AWS WWSO AI Services team with expertise in AI and ML for intelligent document processing and content moderation. She is passionate about promoting AWS AI services and helping customers transform their business solutions.
Lana Zhang is a Sr. Solutions Architect at the AWS WWSO AI Services team with expertise in AI and ML for intelligent document processing and content moderation. She is passionate about promoting AWS AI services and helping customers transform their business solutions.

Sonali Sahu is leading Intelligent Document Processing AI/ML Solutions Architect team at Amazon Web Services. She is a passionate technophile and enjoys working with customers to solve complex problems using innovation. Her core area of focus are Artificial Intelligence & Machine Learning for Intelligent Document Processing.

