Stream data processing allows you to act on data in real time. Real-time data analytics can help you have on-time and optimized responses while improving overall customer experience.
Apache Flink is a distributed computation framework that allows for stateful real-time data processing. It provides a single set of APIs for building batch and streaming jobs, making it easy for developers to work with bounded and unbounded data. Apache Flink provides different levels of abstraction to cover a variety of event processing use cases.
Amazon Kinesis Data Analytics is an AWS service that provides a serverless infrastructure for running Apache Flink applications. This makes it easy for developers to build highly available, fault tolerant, and scalable Apache Flink applications without needing to become an expert in building, configuring, and maintaining Apache Flink clusters on AWS.
Data streaming workloads often require data in the stream to be enriched via external sources (such as databases or other data streams). For example, assume you are receiving coordinates data from a GPS device and need to understand how these coordinates map with physical geographic locations; you need to enrich it with geolocation data. You can use several approaches to enrich your real-time data in Kinesis Data Analytics depending on your use case and Apache Flink abstraction level. Each method has different effects on the throughput, network traffic, and CPU (or memory) utilization. In this post, we cover these approaches and discuss their benefits and drawbacks.
Data enrichment patterns
Data enrichment is a process that appends additional context and enhances the collected data. The additional data often is collected from a variety of sources. The format and the frequency of the data updates could range from once in a month to many times in a second. The following table shows a few examples of different sources, formats, and update frequency.
| Data | Format | Update Frequency |
| IP address ranges by country | CSV | Once a month |
| Company organization chart | JSON | Twice a year |
| Machine names by ID | CSV | Once a day |
| Employee information | Table (Relational database) | A few times a day |
| Customer information | Table (Non-relational database) | A few times an hour |
| Customer orders | Table (Relational database) | Many times a second |
Based on the use case, your data enrichment application may have different requirements in terms of latency, throughput, or other factors. The remainder of the post dives deeper into different patterns of data enrichment in Kinesis Data Analytics, which are listed in the following table with their key characteristics. You can choose the best pattern based on the trade-off of these characteristics.
| Enrichment Pattern | Latency | Throughput | Accuracy if Reference Data Changes | Memory Utilization | Complexity |
| Pre-load reference data in Apache Flink Task Manager memory | Low | High | Low | High | Low |
| Partitioned pre-loading of reference data in Apache Flink state | Low | High | Low | Low | Low |
| Periodic Partitioned pre-loading of reference data in Apache Flink state | Low | High | Medium | Low | Medium |
| Per-record asynchronous lookup with unordered map | Medium | Medium | High | Low | Low |
| Per-record asynchronous lookup from an external cache system | Low or Medium (Depending on Cache storage and implementation) | Medium | High | Low | Medium |
| Enriching streams using the Table API | Low | High | High | Low – Medium (depending on the selected join operator) | Low |
Enrich streaming data by pre-loading the reference data
When the reference data is small in size and static in nature (for example, country data including country code and country name), it’s recommended to enrich your streaming data by pre-loading the reference data, which you can do in several ways.
To see the code implementation for pre-loading reference data in various ways, refer to the GitHub repo. Follow the instructions in the GitHub repository to run the code and understand the data model.
Pre-loading of reference data in Apache Flink Task Manager memory
The simplest and also fastest enrichment method is to load the enrichment data into each of the Apache Flink task managers’ on-heap memory. To implement this method, you create a new class by extending the RichFlatMapFunction abstract class. You define a global static variable in your class definition. The variable could be of any type, the only limitation is that it should extend java.io.Serializable—for example, java.util.HashMap. Within the open() method, you define a logic that loads the static data into your defined variable. The open() method is always called first, during the initialization of each task in Apache Flink’s task managers, which makes sure the whole reference data is loaded before the processing begins. You implement your processing logic by overriding the processElement() method. You implement your processing logic and access the reference data by its key from the defined global variable.
The following architecture diagram shows the full reference data load in each task slot of the task manager.
This method has the following benefits:
- Easy to implement
- Low latency
- Can support high throughput
However, it has the following disadvantages:
- If the reference data is large in size, the Apache Flink task manager may run out of memory.
- Reference data can become stale over a period of time.
- Multiple copies of the same reference data are loaded in each task slot of the task manager.
- Reference data should be small to fit in the memory allocated to a single task slot. In Kinesis Data Analytics, each Kinesis Processing Unit (KPU) has 4 GB of memory, out of which 3 GB can be used for heap memory. If
ParallelismPerKPUin Kinesis Data Analytics is set to 1, one task slot runs in each task manager, and the task slot can use the whole 3 GB of heap memory. IfParallelismPerKPUis set to a value greater than 1, the 3 GB of heap memory is distributed across multiple task slots in the task manager. If you’re deploying Apache Flink in Amazon EMR or in a self-managed mode, you can tunetaskmanager.memory.task.heap.sizeto increase the heap memory of a task manager.
Partitioned pre-loading of reference data in Apache Flink State
In this approach, the reference data is loaded and kept in the Apache Flink state store at the start of the Apache Flink application. To optimize the memory utilization, first the main data stream is divided by a specified field via the keyBy() operator across all task slots. Furthermore, only the portion of the reference data that corresponds to each task slot is loaded in the state store.
This is achieved in Apache Flink by creating the class PartitionPreLoadEnrichmentData, extending the RichFlatMapFunction abstract class. Within the open method, you override the ValueStateDescriptor method to create a state handle. In the referenced example, the descriptor is named locationRefData, the state key type is String, and the value type is Location. In this code, we use ValueState compared to MapState because we only hold the location reference data for a particular key. For example, when we query Amazon S3 to get the location reference data, we query for the specific role and get a particular location as a value.
In Apache Flink, ValueState is used to hold a specific value for a key, whereas MapState is used to hold a combination of key-value pairs.
This technique is useful when you have a large static dataset that is difficult to fit in memory as a whole for each partition.
The following architecture diagram shows the load of reference data for the specific key for each partition of the stream.
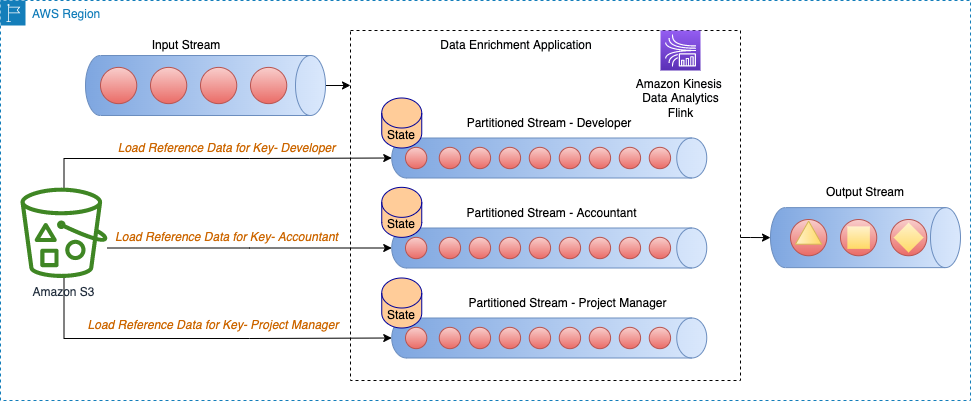
For example, our reference data in the sample GitHub code has roles which are mapped to each building. Because the stream is partitioned by roles, only the specific building information per role is required to be loaded for each partition as the reference data.
This method has the following benefits:
- Low latency.
- Can support high throughput.
- Reference data for specific partition is loaded in the keyed state.
- In Kinesis Data Analytics, the default state store configured is RocksDB. RocksDB can utilize a significant portion of 1 GB of managed memory and 50 GB of disk space provided by each KPU. This provides enough room for the reference data to grow.
However, it has the following disadvantages:
- Reference data can become stale over a period of time
Periodic partitioned pre-loading of reference data in Apache Flink State
This approach is a fine-tune of the previous technique, where each partitioned reference data is reloaded on a periodic basis to refresh the reference data. This is useful if your reference data changes occasionally.
The following architecture diagram shows the periodic load of reference data for the specific key for each partition of the stream.

In this approach, the class PeriodicPerPartitionLoadEnrichmentData is created, extending the KeyedProcessFunction class. Similar to the previous pattern, in the context of the GitHub example, ValueState is recommended here because each partition only loads a single value for the key. In the same way as mentioned earlier, in the open method, you define the ValueStateDescriptor to handle the value state and define a runtime context to access the state.
Within the processElement method, load the value state and attach the reference data (in the referenced GitHub example, buildingNo to the customer data). Also register a timer service to be invoked when the processing time passes the given time. In the sample code, the timer service is scheduled to be invoked periodically (for example, every 60 seconds). In the onTimer method, update the state by making a call to reload the reference data for the specific role.
This method has the following benefits:
- Low latency.
- Can support high throughput.
- Reference data for specific partitions is loaded in the keyed state.
- Reference data is refreshed periodically.
- In Kinesis Data Analytics, the default state store configured is RocksDB. Also, 50 GB of disk space provided by each KPU. This provides enough room for the reference data to grow.
However, it has the following disadvantages:
- If the reference data changes frequently, the application still has stale data depending on how frequently the state is reloaded
- The application can face load spikes during reload of reference data
Enrich streaming data using per-record lookup
Although pre-loading of reference data provides low latency and high throughput, it may not be suitable for certain types of workloads, such as the following:
- Reference data updates with high frequency
- Apache Flink needs to make an external call to compute the business logic
- Accuracy of the output is important and the application shouldn’t use stale data
Normally, for these types of use cases, developers trade-off high throughput and low latency for data accuracy. In this section, you learn about a few of common implementations for per-record data enrichment and their benefits and disadvantages.
Per-record asynchronous lookup with unordered map
In a synchronous per-record lookup implementation, the Apache Flink application has to wait until it receives the response after sending every request. This causes the processor to stay idle for a significant period of processing time. Instead, the application can send a request for other elements in the stream while it waits for the response for the first element. This way, the wait time is amortized across multiple requests and therefore it increases the process throughput. Apache Flink provides asynchronous I/O for external data access. While using this pattern, you have to decide between unorderedWait (where it emits the result to the next operator as soon as the response is received, disregarding the order of the element on the stream) and orderedWait (where it waits until all inflight I/O operations complete, then sends the results to the next operator in the same order as original elements were placed on the stream). Usually, when downstream consumers disregard the order of the elements in the stream, unorderedWait provides better throughput and less idle time. Visit Enrich your data stream asynchronously using Kinesis Data Analytics for Apache Flink to learn more about this pattern.
The following architecture diagram shows how an Apache Flink application on Kinesis Data Analytics does asynchronous calls to an external database engine (for example Amazon DynamoDB) for every event in the main stream.
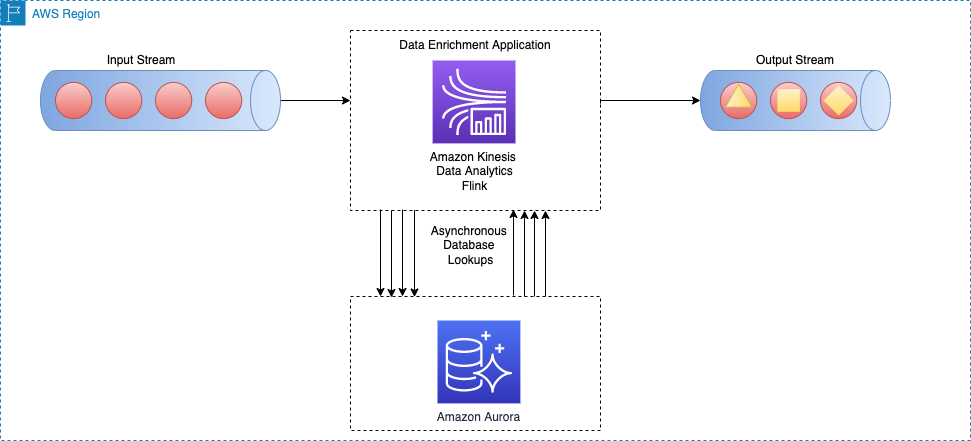
This method has the following benefits:
- Still reasonably simple and easy to implement
- Reads the most up-to-date reference data
However, it has the following disadvantages:
- It generates a heavy read load for the external system (for example, a database engine or an external API) that hosts the reference data
- Overall, it might not be suitable for systems that require high throughput with low latency
Per-record asynchronous lookup from an external cache system
A way to enhance the previous pattern is to use a cache system to enhance the read time for every lookup I/O call. You can use Amazon ElastiCache for caching, which accelerates application and database performance, or as a primary data store for use cases that don’t require durability like session stores, gaming leaderboards, streaming, and analytics. ElastiCache is compatible with Redis and Memcached.
For this pattern to work, you must implement a caching pattern for populating data in the cache storage. You can choose between a proactive or reactive approach depending your application objectives and latency requirements. For more information, refer to Caching patterns.
The following architecture diagram shows how an Apache Flink application calls to read the reference data from an external cache storage (for example, Amazon ElastiCache for Redis). Data changes must be replicated from the main database (for example, Amazon Aurora) to the cache storage by implementing one of the caching patterns.
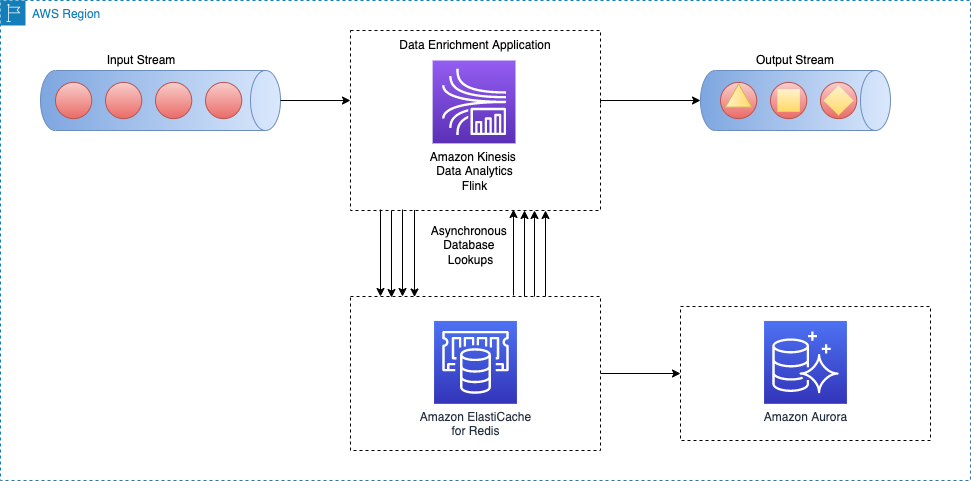
Implementation for this data enrichment pattern is similar to the per-record asynchronous lookup pattern; the only difference is that the Apache Flink application makes a connection to the cache storage, instead of connecting to the primary database.
This method has the following benefits:
- Better throughput because caching can accelerate application and database performance
- Protects the primary data source from the read traffic created by the stream processing application
- Can provide lower read latency for every lookup call
- Overall, might not be suitable for medium to high throughput systems that want to improve data freshness
However, it has the following disadvantages:
- Additional complexity of implementing a cache pattern for populating and syncing the data between the primary database and the cache storage
- There is a chance for the Apache Flink stream processing application to read stale reference data depending on what caching pattern is implemented
- Depending on the chosen cache pattern (proactive or reactive), the response time for each enrichment I/O may differ, therefore the overall processing time of the stream could be unpredictable
Alternatively, you can avoid these complexities by using the Apache Flink JDBC connector for Flink SQL APIs. We discuss enrichment stream data via Flink SQL APIs in more detail later in this post.
Enrich stream data via another stream
In this pattern, the data in the main stream is enriched with the reference data in another data stream. This pattern is good for use cases in which the reference data is updated frequently and it’s possible to perform change data capture (CDC) and publish the events to a data streaming service such as Apache Kafka or Amazon Kinesis Data Streams. This pattern is useful in the following use cases, for example:
- Customer purchase orders are published to a Kinesis data stream, and then join with customer billing information in a DynamoDB stream
- Data events captured from IoT devices should enrich with reference data in a table in Amazon Relational Database Service (Amazon RDS)
- Network log events should enrich with the machine name on the source (and the destination) IP addresses
The following architecture diagram shows how an Apache Flink application on Kinesis Data Analytics joins data in the main stream with the CDC data in a DynamoDB stream.

To enrich streaming data from another stream, we use a common stream to stream join patterns, which we explain in the following sections.
Enrich streams using the Table API
Apache Flink Table APIs provide higher abstraction for working with data events. With Table APIs, you can define your data stream as a table and attach the data schema to it.
In this pattern, you define tables for each data stream and then join those tables to achieve the data enrichment goals. Apache Flink Table APIs support different types of join conditions, like inner join and outer join. However, you want to avoid those if you’re dealing with unbounded streams because those are resource intensive. To limit the resource utilization and run joins effectively, you should use either interval or temporal joins. An interval join requires one equi-join predicate and a join condition that bounds the time on both sides. To better understand how to implement an interval join, refer to Get started with Apache Flink SQL APIs in Kinesis Data Analytics Studio.
Compared to interval joins, temporal table joins don’t work with a time period within which different versions of a record are kept. Records from the main stream are always joined with the corresponding version of the reference data at the time specified by the watermark. Therefore, fewer versions of the reference data remain in the state.
Note that the reference data may or may not have a time element associated with it. If it doesn’t, you may need to add a processing time element for the join with the time-based stream.
In the following example code snippet, the update_time column is added to the currency_rates reference table from the change data capture metadata such as Debezium. Furthermore, it’s used to define a watermark strategy for the table.
About the Authors
 Ali Alemi is a Streaming Specialist Solutions Architect at AWS. Ali advises AWS customers with architectural best practices and helps them design real-time analytics data systems that are reliable, secure, efficient, and cost-effective. He works backward from customers’ use cases and designs data solutions to solve their business problems. Prior to joining AWS, Ali supported several public sector customers and AWS consulting partners in their application modernization journey and migration to the cloud.
Ali Alemi is a Streaming Specialist Solutions Architect at AWS. Ali advises AWS customers with architectural best practices and helps them design real-time analytics data systems that are reliable, secure, efficient, and cost-effective. He works backward from customers’ use cases and designs data solutions to solve their business problems. Prior to joining AWS, Ali supported several public sector customers and AWS consulting partners in their application modernization journey and migration to the cloud.
 Subham Rakshit is a Streaming Specialist Solutions Architect for Analytics at AWS based in the UK. He works with customers to design and build search and streaming data platforms that help them achieve their business objective. Outside of work, he enjoys spending time solving jigsaw puzzles with his daughter.
Subham Rakshit is a Streaming Specialist Solutions Architect for Analytics at AWS based in the UK. He works with customers to design and build search and streaming data platforms that help them achieve their business objective. Outside of work, he enjoys spending time solving jigsaw puzzles with his daughter.
 Dr. Sam Mokhtari is a Senior Solutions Architect in AWS. His main area of depth is data and analytics, and he has published more than 30 influential articles in this field. He is also a respected data and analytics advisor who led several large-scale implementation projects across different industries, including energy, health, telecom, and transport.
Dr. Sam Mokhtari is a Senior Solutions Architect in AWS. His main area of depth is data and analytics, and he has published more than 30 influential articles in this field. He is also a respected data and analytics advisor who led several large-scale implementation projects across different industries, including energy, health, telecom, and transport.

