Table of contents
Introduction
Learning is the acquisition and mastery of knowledge over a domain through experience. It is not only a human thing but appertains to machines too. The world of computing has transformed drastically from an ineffectual mechanical system into a Herculean automated technique with the advent of Artificial Intelligence. Data is the fuel that drives this technology; the recent availability of enormous amounts of data has made it the buzzword in technology. Artificial Intelligence, in its simplest form, is to simulate human intelligence into machines for better decision-making.
Artificial intelligence (AI) is a branch of computer science that deals with the simulation of human intelligence processes by machines. The term cognitive computing is also used to refer to AI as computer models are deployed to simulate the human thinking process. Any device which recognizes its current environment and optimizes its goal is said to be AI enabled. AI could be broadly categorized as weak or strong. The systems that are designed and trained to perform a particular task are known as weak AI, like the voice activated systems. They can answer a question or obey a program command, but cannot work without human intervention. Strong AI is a generalized human cognitive ability. It can solve tasks and find solutions without human intervention. Self driving cars are an example of strong AI which uses Computer Vision, Image Recognition and Deep Learning to pilot a vehicle. AI has made its entry into a variety of industries that benefit both businesses and consumers. Healthcare, education, finance, law and manufacturing are a few of them. Many technologies like Automation, Machine learning, Machine Vision, Natural Language Processing and Robotics incorporate AI.
The drastic increase in the routine work carried out by humans’ calls for the need to automation. Precision and accuracy are the next driving terms that demand the invention of intelligent system in contrasted to the manual systems. Decision making and pattern recognition are the compelling tasks that insist on automation as they require unbiased decisive results which could be acquired through intense learning on the historic data of the concerned domain. This could be achieved through Machine Learning, where it is required of the system that makes predictions to undergo massive training on the past data to make accurate predictions in the future. Some of the popular applications of ML in daily life include commute time estimations by providing faster routes, estimating the optimal routes and the price per trip. Its application can be seen in email intelligence performing spam filters, email classifications and making smart replies. In the area of banking and personal finance it is used to make credit decisions, prevention of fraudulent transactions. It plays a major role in healthcare and diagnosis, social networking and personal assistants like Siri and Cortana. The list is almost endless and keeps growing everyday as more and more fields are employing AI and ML for their daily activities.
True artificial intelligence is decades away, but we have a type of AI called Machine Learning today. AI also known as cognitive computing is forked into two cognate techniques, the Machine Learning and the Deep Learning. Machine learning has occupied a considerable space in the research of making brilliant and automated machines. They can recognize patterns in data without being programmed explicitly. Machine learning provides the tools and technologies to learn from the data and more importantly from the changes in the data. Machine learning algorithms have found its place in many applications; from the apps that decide the food you choose to the ones that decides on your next movie to watch including the chat bots that book your saloon appointments are a few of those stunning Machine Learning applications that rock the information technology industry. Its counterpart the Deep Learning technique has its functionality inspired from the human brain cells and is gaining more popularity. Deep learning is a subset of machine learning which learns in an incremental fashion moving from the low level categories to the high level categories. Deep Learning algorithms provide more accurate results when they are trained with very large amounts of data. Problems are solved using an end to end fashion which gives them the name as magic box / black box.. Their performances are optimized with the use of higher end machines. Deep Learning has its functionality inspired from the human brain cells and is gaining more popularity. Deep learning is actually a subset of machine learning which learns in an incremental fashion moving from the low level categories to the high level categories. Deep Learning is preferred in applications such as self driving cars, pixel restorations and natural language processing. These applications simply blow our minds but the reality is that the absolute powers of these technologies are yet to be divulged. This article provides an overview of these technologies encapsulating the theory behind them along with their applications.
What is Machine Learning?
Computers can do only what they are programmed to do. This was the story of the past until computers can perform operations and make decisions like human beings. Machine Learning, which is a subset of AI is the technique that enables computers to mimic human beings. The term Machine Learning was invented by Arthur Samuel in the year 1952, when he designed the first computer program that could learn as it executed. Arthur Samuel was a pioneer of in two most sought after fields, artificial intelligence and computer gaming. According to him Machine Learning is the “Field of study that gives computers the capability to learn without being explicitly programmed”.
In ordinary terms, Machine Learning is a subset of Artificial Intelligence that allows a software to learn by itself from the past experience and use that knowledge to improve their performance in the future works without being programmed explicitly. Consider an example to identify the different flowers based on different attributes like color, shape, smell, petal size etc., In traditional programming all the tasks are hardcoded with some rules to be followed in the identification process. In machine learning this task could be accomplished easily by making the machine learn without being programmed. Machines learn from the data provided to them. Data is the fuel which drives the learning process. Though the term Machine learning was introduced way back in 1959, the fuel that drives this technology is available only now. Machine learning requires huge data and computational power which was once a dream is now at our disposal.
Traditional programming Vs Machine Learning:
When computers are employed to perform some tasks instead of human beings, they require to be provided with some instructions called a computer program. Traditional programming has been in practice for more than a century. They started in the mid 1800s where a computer program uses the data and runs on a computer system to generate the output. For example, a traditionally programmed business analysis will take the business data and the rules (computer program) as input and will output the business insights by applying the rules to the data.
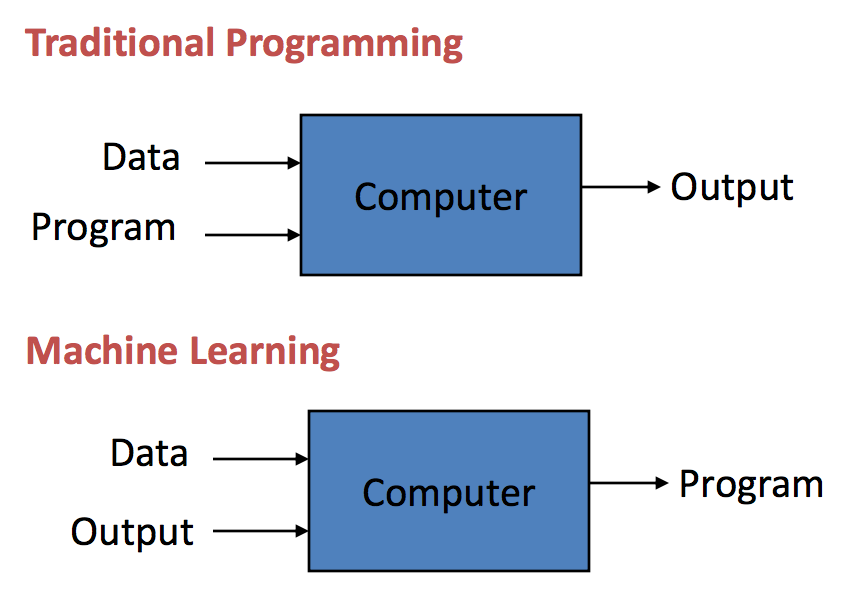
On the contrary, in Machine learning the data and the outputs also called labels are provided as the input to an algorithm which comes up with a model, as an output.
For example, if the customer demographics and transactions are fed as input data and use the past customer churn rates as the output data (labels), an algorithm will be able to construct a model that can predict whether a customer will churn or not. That model is called as a predictive model. Such machine learning models could be used to predict any situation being provided with the necessary historic data. Machine learning techniques are very valuable ones because they allow the computers to learn new rules in a high dimensional complex space, which are harder to comprehend by the humans.
Need for Machine Learning:
Machine learning has been around for a while now, but the ability to apply mathematical calculations automatically and quickly to huge data is now gaining momentum. Machine Learning can be used to automate many tasks, specifically the ones that can be performed only by humans with their inbred intelligence. This intelligence can be replicated to machines through machine learning.
Machine learning has found its place in applications like the self-driving cars, online recommendation engines like friend recommendations on Facebook and offer suggestions from Amazon, and in detecting cyber frauds. Machine learning is needed for problem like image and speech recognition, language translation and sales forecasting, where we cannot write down the fixed rules to be followed for the problem.
Operations such as decision making, forecasting, making prediction, providing alerts on deviations, uncovering hidden trends or relationships require diverse, lots of unstructured and real time data from various artifacts that could be best handled only by machine learning paradigm.
History of Machine Learning
This section discusses about the development of machine learning over the years. Today we are witnessing some astounding applications like self driving cars, natural language processing and facial recognition systems making use of ML techniques for their processing. All this began in the year 1943, when Warren McCulloch a neurophysiologist along with a mathematician named Walter Pitts authored a paper which threw a light on neurons and its working. They created a model with electrical circuits and thus neural network was born.
The famous “Turing Test” was created in 1950 by Alan Turing which would ascertain whether the computers had real intelligence. It has to make a human believe that it is not a computer but a human instead, to get through the test. Arthur Samuel developed the first computer program that could learn as it played the game of checkers in the year 1952. The first neural network called the perceptron was designed by Frank Rosenblatt in the year 1957.
The big shift happened in the 1990s where machine learning moved from being knowledge driven to a data driven technique due to the availability of the huge volumes of data. IBM’s Deep Blue, developed in 1997 was the first machine to defeat the world champion in the game of chess. Businesses have recognized that the potential for complex calculations could be increased through machine learning. Some of the latest projects include: Google Brain that was developed in 2012, was a deep neural network that focused on pattern recognition in images and videos. It was later employed to detect objects in You Tube videos. In 2014, Face book created Deep Face which can recognize people just like how humans do. In 2014, Deep Mind, created a computer program called Alpha Go a board game that defeated a professional Go player. Due to its complexity the game is said to be a very challenging, yet a classical game for artificial intelligence. Scientists Stephen Hawking and Stuart Russel have felt that if AI gains the power to redesign itself with an intensifying rate, then an unbeatable “intelligence explosion” may lead to human extinction. Musk characterizes AI as humanity’s “biggest existential threat.” Open AI is an organization created by Elon Musk in 2015 to develop safe and friendly AI that could benefit humanity. Recently, some of the breakthrough areas in AI are Computer Vision, Natural Language Processing and Reinforcement Learning.
Features of Machine Learning
In recent years technology domain has witnessed an immensely popular topic called Machine Learning. Almost every business is attempting to embrace this technology. Companies have transformed the way in which they carryout business and the future seems brighter and promising due to the impact of machine learning. Some of the key features of machine learning may include:
Automation: The capacity to automate repetitive tasks and hence increase the business productivity is the biggest key factor of machine learning. ML powered paperwork and email automation are being used by many organizations. In the financial sector ML makes the accounting work faster, accurate and draws useful insights quickly and easily. Email classification is a classic example of automation, where spam emails are automatically classified by Gmail into the spam folder.
Improved customer engagement: Providing a customized experience for customers and providing excellent service are very important for any business to promote their brand loyalty and to retain long – standing customer relationships. These could be achieved through ML. Creating recommendation engines that are tailored perfectly to the customer’s needs and creating chat bots which could simulate human conversations smoothly by understanding the nuances of conversations and answer questions appropriately. An AVA of Air Asia airline is an example of one such chat bots. It is a virtual assistant that is powered by AI and responds to customer queries instantly. It can mimic 11 human languages and makes use of natural language understanding technique.
Automated data visualization: We are aware that vast data is being generated by businesses, machines and individuals. Businesses generate data from transactions, e-commerce, medical records, financial systems etc. Machines also generate huge amounts of data from satellites, sensors, cameras, computer log files, IoT systems, cameras etc. Individuals generate huge data from social networks, emails, blogs, Internet etc. The relationships between the data could be identified easily through visualizations. Identifying patterns and trends in data could be easily done easily through a visual summary of information rather than going through thousands of rows on a spreadsheet. Businesses can acquire valuable new insights through data visualizations in-order to increase productivity in their domain through user-friendly automated data visualization platforms provided by machine learning applications. Auto Viz is one such platform that provides automated data visualization tolls to enhance productivity in businesses.
Accurate data analysis: The purpose of data analysis is to find answers to specific questions that try to identify business analytics and business intelligence. Traditional data analysis involves a lot of trial and error methods, which become absolutely impossible when working with large amounts of both structured and unstructured data. Data analysis is a very important task which requires huge amounts of time. Machine learning comes in handy by offering many algorithms and data driven models that can perfectly handle real time data.
Business intelligence: Business intelligence refers to streamlined operations of collecting; processing and analyzing of data in an organization .Business intelligence applications when powered by AI can scrutinize new data and recognize the patterns and trends that are relevant to the organization. When machine learning features are combined with big data analytics it could help businesses to find solutions to the problems that will help the businesses to grow and make more profit. ML has become one of the most powerful technologies to increase business operations from e-commerce to financial sector to healthcare.
Languages for Machine Learning
There are many programming languages out there for machine learning. The choice of the language and the level of programming desired depend on how machine learning is used in an application. The fundamentals of programming, logic, data structures, algorithms and memory management are needed to implement machine learning techniques for any business applications. With this knowledge one can straight away implement machine learning models with the help of the various built-in libraries offered by many programming languages. There are also many graphical and scripting languages like Orange, Big ML, Weka and others allows to implement ML algorithms without being hardcoded; all that you require is just a fundamental knowledge about programming.
There is no single programming language that could be called as the ‘best’ for machine learning. Each of them is good where they are applied. Some may prefer to use Python for NLP applications, while others may prefer R or Python for sentiment analysis application and some use Java for ML applications relating to security and threat detection. Five different languages that are best suited for ML programming is listed below.

Python:
Nearly 8. 2 million developers are using Python for coding around the world. The annual ranking by the IEEE Spectrum, Python was chosen as the most popular programming language. It also seen that the Stack overflow trends in programming languages show that Python is rising for the past five years. It has an extensive collection of packages and libraries for Machine Learning. Any user with the basic knowledge of Python programming can use these libraries right away without much difficulty.
To work with text data, packages like NLTK, SciKit and Numpy comes handy. OpenCV and Sci-Kit image can be used to process images. One can use Librosa while working with audio data. In implementing deep learning applications, TensorFlow, Keras and PyTorch come in as a life saver. Sci-Kit-learn can be used for implementing primitive machine learning algorithms and Sci-Py for performing scientific calculations. Packages like Matplotlib, Sci-Kit and Seaborn are best suited for best data visualizations.
R:
R is an excellent programming language for machine learning applications using statistical data. R is packed with a variety of tools to train and evaluate machine learning models to make accurate future predictions. R is an open source programming language and very cost effective. It is highly flexible and cross-platform compatible. It has a broad spectrum of techniques for data sampling, data analysis, model evaluation and data visualization operations. The comprehensive list of packages include MICE which is used for handling missing values, CARET to perform classification an regression problems, PARTY and rpart to create partitions in data, random FOREST for crating decision trees, tidyr and dplyr are used for data manipulation, ggplot for creating data visualizations, Rmarkdown and Shiny to perceive insights through the creation of reports.
Java and JavaScript:
Java is picking up more attention in machine learning from the engineers who come from java background. Most of the open source tools like Hadoop and Spark that are used for big data processing are written in Java. It has a variety of third party libraries like JavaML to implement machine learning algorithms. Arbiter Java is used for hyper parameter tuning in ML. The others are Deeplearning4J and Neuroph which are used in deep learning applications. Scalability of Java is a great lift to ML algorithms which enables the creation of complex and huge applications. Java virtual machines are an added advantage to create code on multiple platforms.
Julia:
Julia is a general purpose programming language that is capable of performing complex numerical analysis and computational science. It is specifically designed to perform mathematical and scientific operations in machine learning algorithms. Julia code is executed at high speed and does not require any optimization techniques to address problems relating to performance. Has a variety of tools like TensorFlow, MLBase.jl, Flux.jl, SciKitlearn.jl. It supports all types of hardware including TPU’s and GPU’s. Tech giants like Apple and Oracle are emplying Julia for their machine learning applications.
Lisp:
LIST (List Processing) is the second oldest programming language which is being used still. It was developed for AI-centric applications. LISP is used in inductive logic programming and machine learning. ELIZA, the first AI chat bot was developed using LISP. Many machine learning applications like chatbots eCommerce are developed using LISP. It provides quick prototyping capabilities, does automatic garbage collection, offers dynamic object creation and provides lot of flexibility in operations.
Types of Machine Learning
At a high-level machine learning is defined as the study of teaching a computer program or an algorithm to automatically improve on a specific task. From the research point, it can be viewed through the eye of theoretical and mathematical modeling, about the working of the entire process. It is interesting to learn and understand about the different types of machine learning in a world that is drenched in artificial intelligence and machine learning. From the perspective of a computer user, this can be seen as the understanding of the types of machine learning and how they may reveal themselves in various applications. And from the practitioner’s perspective it is necessary to know the types of machine learning for creating these applications for any given task.
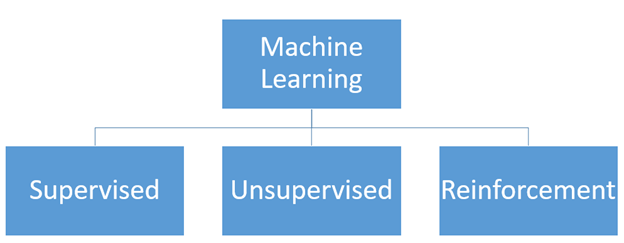
Supervised Learning:
Supervised learning is the class of problems that uses a model to learn the mapping between the input variables and the target variable. Applications consisting of the training data describing the various input variables and the target variable are known as supervised learning tasks.
Let the set of input variable be (x) and the target variable be (y). A supervised learning algorithm tries to learn a hypothetical function which is a mapping given by the expression y=f(x), which is a function of x.
The learning process here is monitored or supervised. Since we already know the output the algorithm is corrected each time it makes a prediction, to optimize the results. Models are fit on training data which consists of both the input and the output variable and then it is used to make predictions on test data. Only the inputs are provided during the test phase and the outputs produced by the model are compared with the kept back target variables and is used to estimate the performance of the model.
There are basically two types of supervised problems: Classification – which involves prediction of a class label and Regression – that involves the prediction of a numerical value.
The MINST handwritten digits data set can be seen as an example of classification task. The inputs are the images of handwritten digits, and the output is a class label which identifies the digits in the range 0 to 9 into different classes.
The Boston house price data set could be seen as an example of Regression problem where the inputs are the features of the house, and the output is the price of a house in dollars, which is a numerical value.
Unsupervised Learning:
In an unsupervised learning problem the model tries to learn by itself and recognize patterns and extract the relationships among the data. As in case of a supervised learning there is no supervisor or a teacher to drive the model. Unsupervised learning operates only on the input variables. There are no target variables to guide the learning process. The goal here is to interpret the underlying patterns in the data in order to obtain more proficiency over the underlying data.
There are two main categories in unsupervised learning; they are clustering – where the task is to find out the different groups in the data. And the next is Density Estimation – which tries to consolidate the distribution of data. These operations are performed to understand the patterns in the data. Visualization and Projection may also be considered as unsupervised as they try to provide more insight into the data. Visualization involves creating plots and graphs on the data and Projection is involved with the dimensionality reduction of the data.
Reinforcement Learning:
Reinforcement learning is type a of problem where there is an agent and the agent is operating in an environment based on the feedback or reward given to the agent by the environment in which it is operating. The rewards could be either positive or negative. The agent then proceeds in the environment based on the rewards gained.
The reinforcement agent determines the steps to perform a particular task. There is no fixed training dataset here and the machine learns on its own.
Playing a game is a classic example of a reinforcement problem, where the agent’s goal is to acquire a high score. It makes the successive moves in the game based on the feedback given by the environment which may be in terms of rewards or a penalization. Reinforcement learning has shown tremendous results in Google’s AplhaGo of Google which defeated the world’s number one Go player.
Machine Learning Algorithms
There are a variety of machine learning algorithms available and it is very difficult and time consuming to select the most appropriate one for the problem at hand. These algorithms can be grouped in to two categories. Firstly, they can be grouped based on their learning pattern and secondly by their similarity in their function.
Based on their learning style they can be divided into three types:
- Supervised Learning Algorithms: The training data is provided along with the label which guides the training process. The model is trained until the desired level of accuracy is attained with the training data. Examples of such problems are classification and regression. Examples of algorithms used include Logistic Regression, Nearest Neighbor, Naive Bayes, Decision Trees, Linear Regression, Support Vector Machines (SVM), Neural Networks.
- Unsupervised Learning Algorithms: Input data is not labeled and does not come with a label. The model is prepared by identifying the patterns present in the input data. Examples of such problems include clustering, dimensionality reduction and association rule learning. List of algorithms used for these type of problems include Apriori algorithm and K-Means and Association Rules
- Semi-Supervised Learning Algorithms: The cost to label the data is quite expensive as it requires the knowledge of skilled human experts. The input data is combination of both labeled and unlabelled data. The model makes the predictions by learning the underlying patterns on their own. It is a mix of both classification and clustering problems.
Based on the similarity of function the algorithms can be grouped into the following:
- Regression Algorithms: Regression is a process that is concerned with identifying the relationship between the target output variables and the input features to make predictions about the new data. Top six Regression algorithms are: Simple Linear Regression, Lasso Regression, Logistic regression, Multivariate Regression algorithm, Multiple Regression Algorithm.
- Instance based Algorithms: These belong to the family of learning that measures new instances of the problem with those in the training data to find out a best match and makes a prediction accordingly. The top instance based algorithms are: k-Nearest Neighbor, Learning Vector Quantization, Self-Organizing Map, Locally Weighted Learning, and Support Vector Machines.
- Regularization: Regularization refers to the technique of regularizing the learning process from a particular set of features. It normalizes and moderates. The weights attached to the features are normalized which prevents in certain features dominating the prediction process. This technique helps to prevent the problem of overfitting in machine learning. The various regularization algorithms are Ridge Regression, Least Absolute Shrinkage and Selection Operator (LASSO) and Least-Angle Regression (LARS).
- Decision Tree Algorithms: These methods construct tree based model constructed on the decisions made by examining the values of the attributes. Decision trees are used for both classification and regression problems. Some of the well known decision tree algorithms are: Classification and Regression Tree, C4.5 and C5.0, Conditional Decision Trees, Chi-squared Automatic Interaction Detection and Decision Stump.
- Bayesian Algorithms: These algorithms apply the Bayes theorem for the classification and regression problems. They include Naive Bayes, Gaussian Naive Bayes, Multinomial Naive Bayes, Bayesian Belief Network, Bayesian Network and Averaged One-Dependence Estimators.
- Clustering Algorithms: Clustering algorithms involves the grouping of data points into clusters. All the data points that are in the same group share similar properties and, data points in different groups have highly dissimilar properties. Clustering is an unsupervised learning approach and is mostly used for statistical data analysis in many fields. Algorithms like k-Means, k-Medians, Expectation Maximisation, Hierarchical Clustering, Density-Based Spatial Clustering of Applications with Noise fall under this category.
- Association Rule Learning Algorithms: Association rule learning is a rule-based learning method for identifying the relationships between variables in a very large dataset. Association Rule learning is employed predominantly in market basket analysis. The most popular algorithms are: Apriori algorithm and Eclat algorithm.
- Artificial Neural Network Algorithms: Artificial neural network algorithms relies find its base from the biological neurons in the human brain. They belong to the class of complex pattern matching and prediction process in classification and regression problems. Some of the popular artificial neural network algorithms are: Perceptron, Multilayer Perceptrons, Stochastic Gradient Descent, Back-Propagation, , Hopfield Network, and Radial Basis Function Network.
- Deep Learning Algorithms: These are modernized versions of artificial neural network, that can handle very large and complex databases of labeled data. Deep learning algorithms are tailored to handle text, image, audio and video data. Deep learning uses self-taught learning constructs with many hidden layers, to handle big data and provides more powerful computational resources. The most popular deep learning algorithms are: Some of the popular deep learning ms include Convolutional Neural Network, Recurrent Neural Networks, Deep Boltzmann Machine, Auto-Encoders Deep Belief Networks and Long Short-Term Memory Networks.
- Dimensionality Reduction Algorithms: Dimensionality Reduction algorithms exploit the intrinsic structure of data in an unsupervised manner to express data using reduced information set. They convert a high dimensional data into a lower dimension which could be used in supervised learning methods like classification and regression. Some of the well known dimensionality reduction algorithms include Principal Component Analysis, Principal Component Regressio, Linear Discriminant Analysis, Quadratic Discriminant Analysis, Mixture Discriminant Analysis, Flexible Discriminant Analysis and Sammon Mapping.
- Ensemble Algorithms: Ensemble methods are models made up of various weaker models that are trained separately and the individual predictions of the models are combined using some method to get the final overall prediction. The quality of the output depends on the method chosen to combine the individual results. Some of the popular methods are: Random Forest, Boosting, Bootstrapped Aggregation, AdaBoost, Stacked Generalization, Gradient Boosting Machines, Gradient Boosted Regression Trees and Weighted Average.
Machine Learning Life Cycle
Machine learning gives the ability to computers to learn automatically without having the need to program them explicitly. The machine learning process comprises of several stages to design, develop and deploy high quality models. Machine Learning Life Cycle comprises of the following steps
- Data collection
- Data Preparation
- Data Wrangling
- Data Analysis
- Model Training
- Model Testing
- Deployment of the Model
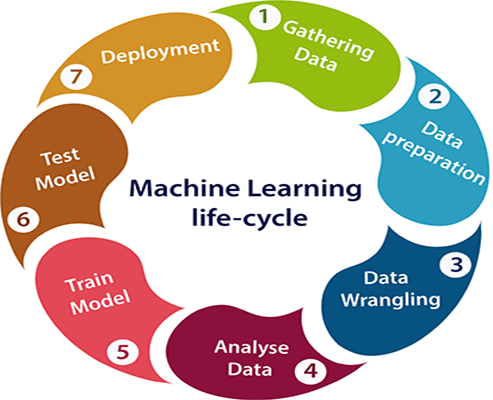
- Data Collection: This is the very first step in creating a machine learning model. The main purpose of this step is to identify and gather all the data that are relevant to the problem. Data could be collected from various sources like files, database, internet, IoT devices, and the list is ever growing. The efficiency of the output will depend directly on the quality of data gathered. So utmost care should be taken in gathering large volume of quality data.
- Data Preparation: The collected data are organized and put in one place or further processing. Data exploration is a part of this step, where the characteristics, nature, format and the quality of the data are being accessed. This includes creating pie charts, bar charts, histogram, skewness etc. data exploration provides useful insight on the data and is helpful in solving of 75% of the problem.
- Data Wrangling: In Data Wrangling the raw data is cleaned and converted into a useful format. The common technique applied to make the most out of the collected data are:
- Missing value check and missing value imputation
- Removing unwanted data and Null values
- Optimizing the data based on the domain of interest
- Detecting and removing outliers
- Reducing the dimension of the data
- Balancing the data, Under-Sampling and Over-Sampling.
- Removal of duplicate records
- Data Analysis: This step is concerned with the feature selection and model selection process. The predictive power of the independent variables in relation to the dependent variable is estimated. Only those variables that are beneficial to the model is selected. Next the appropriate machine learning technique like classification, regression, clustering, association, etc is selected and the model is built using the data.
- Model Training: Training is a very important step in machine learning, as the model tries to understand the various patterns, features and the rules from the underlying data. Data is split into training data and testing data. The model is trained on the training data until its performance reaches an acceptable level.
- Model Testing: After training the model it is put under testing to evaluate its performance on the unseen test data. The accuracy of prediction and the performance of the model can be measured using various measures like confusion matrix, precision and recall, Sensitivity and specificity, Area under the curve, F1 score, R square, gini values etc.
- Deployment: This is the final step in the machine learning life cycle, and we deploy the model constructed in the real world system. Before deployment the model is pickled that is it has to be converted into a platform independent executable form. The pickled model can be deployed using Rest API or Micro-Services.
Deep Learning
Deep learning is a subset of machine learning that follows the functionality of the neurons in the human brain. The deep learning network is made up of multiple neurons interconnected with each other in layers. The neural network has many deep layers that enable the learning process. The deep learning neural network is made up of an input layer, an output layer and multiple hidden layers that make up the complete network. The processing happens through the connections that contain the input data, the pre-assigned weights and the activation function which decides the path for the flow of control through the network. The network operates on huge volume of data and propagates them thorough each layer by learning complex features at each level. If the outcome of the model is not as expected then the weights are adjusted and the process repeats again until the desire outcome is achieved.

Deep neural network can learn the features automatically without being programmed explicitly. Each layer depicts a deeper level of information. The deep learning model follows a hierarchy of knowledge represented in each of the layers. A neural network with five layers will learn more than a neural network with three layers. The learning in a neural network occurs in two steps. In the first step, a nonlinear transformation is applied to the input and a statistical model is created. During the second step, the created model is improved with the help of a mathematical model called as derivative. These two steps are repeated by the neural network thousands of times until it reaches the desired level of accuracy. The repetition of these two steps is known as iteration.
The neural network that has only one hidden layer is known as a shallow network and the neural network that has more than one hidden layers is known as deep neural network.
Types of neural networks:
There are different types of neural networks available for different types of processes. The most commonly used types are discussed here.
- Perceptron: The perceptron is a single-layered neural network that contains only an input layer and an output layer. There are no hidden layers. The activation function used here is the sigmoid function.
- Feed forward: The feed forward neural network is the simplest form of neural network where the information flows only in one direction. There are no cycles in the path of the neural network. Every node in a layer is connected to all the nodes in the next layer. So all the nodes are fully connected and there are no back loops.
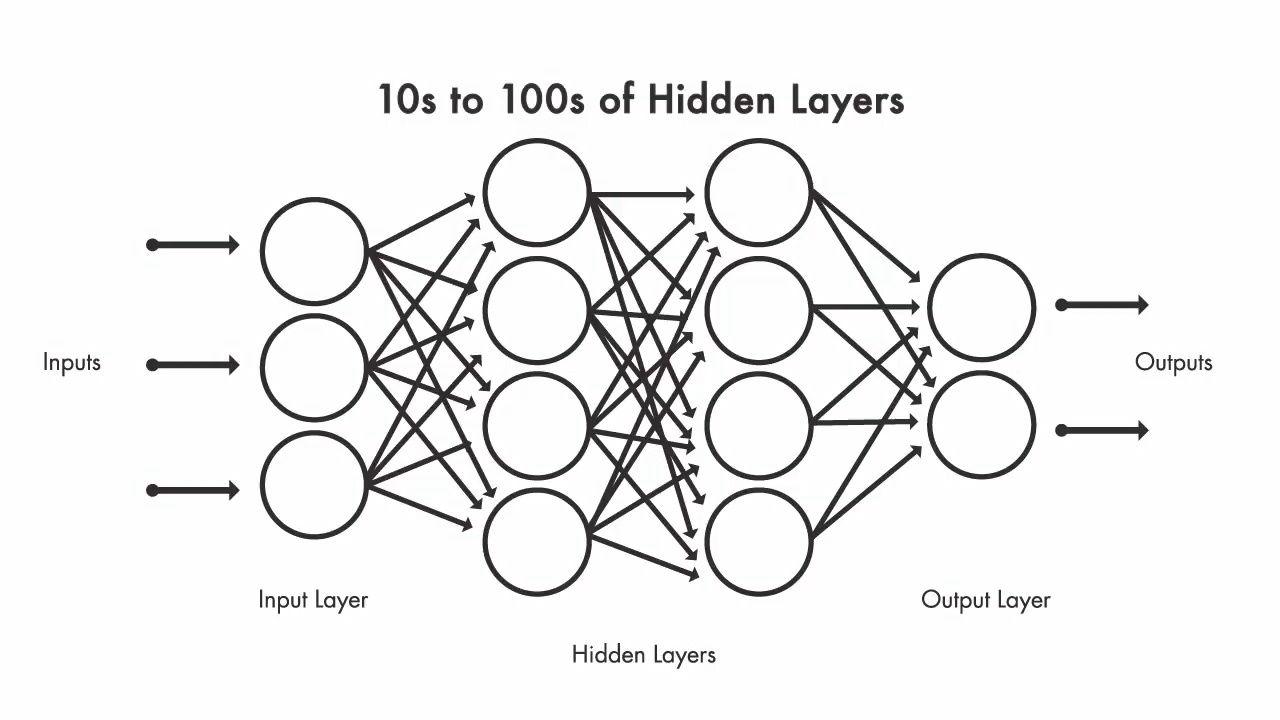
- Recurrent Neural Networks: Recurrent Neural Networks saves the output of the network in its memory and feeds it back to the network to help in the prediction of the output. The network is made up of two different layers. The first is a feed forward neural network and the second is a recurrent neural network where the previous network values and states are remembered in a memory. If a wrong prediction is made then the learning rate is used to gradually move towards making the correct prediction through back propagation.
- Convolutional Neural Network: Convolutional Neural Networks are used where it is necessary to extract useful information from unstructured data. Propagation of signa is uni-directional in a CNN. The first layer is convolutional layer which is followed by a pooling, followed by multiple convolutional and pooling layers. The output of these layers is fed into a fully connected layer and a softmax that performs the classification process. The neurons in a CNN have learnable weights and biases. Convolution uses the nonlinear RELU activation function. CNNs are used in signal and image processing applications.
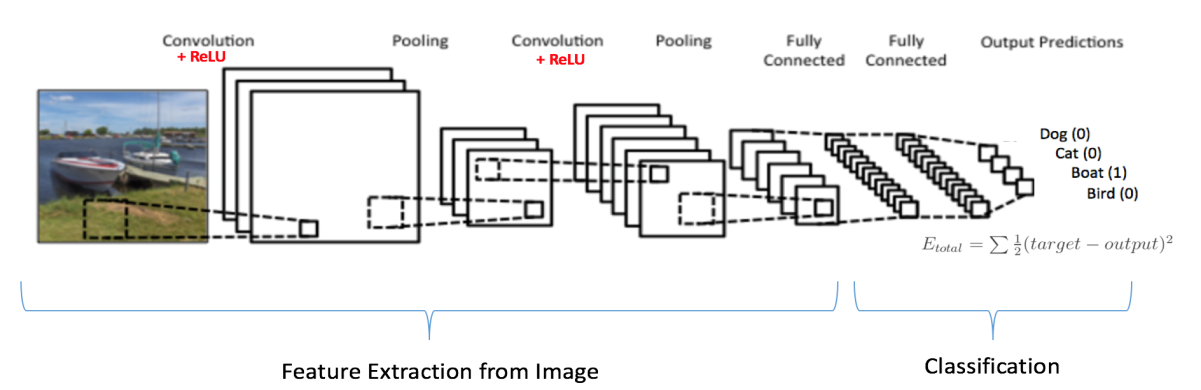
- Reinforcement Learning: In reinforcement learning the agent that operates in a complex and uncertain environment learns by a trial and error method. The agent is rewarded or punished virtually as a result of its actions, and helps in refining the output produced. The goal is to maximize the total number of rewards received by the agent. The model learns on its own to maximize the rewards. Google’s DeepMind and Self drivig cars are examples of applications where reinforcement learning is leveraged.
Difference Between Machine Learning And Deep Learning
Deep learning is a subset of machine learning. The machine learning models become better progressively as they learn their functions with some guidance. If the predictions are not correct then an expert has to make the adjustments to the model. In deep learning the model itself is capable of identifying whether the predictions are correct or not.
- Functioning: Deep learning takes the data as the input and tries to make intelligent decisions automatically using the staked layers of artificial neural network. Machine learning takes the input data, parses it and gets trained on the data. It tries to make decisions on the data based on what it has learnt during the training phase.
- Feature extraction: Deep learning extracts the relevant features from the input data. It automatically extracts the features in a hierarchical manner. The features are learnt in a layer wise manner. It learns the low-level features initially and as it moves down the network it tries to learn the more specific features. Whereas machine learning models requires features that are hand-picked from the dataset. These features are provided as the input to the model to do the prediction.
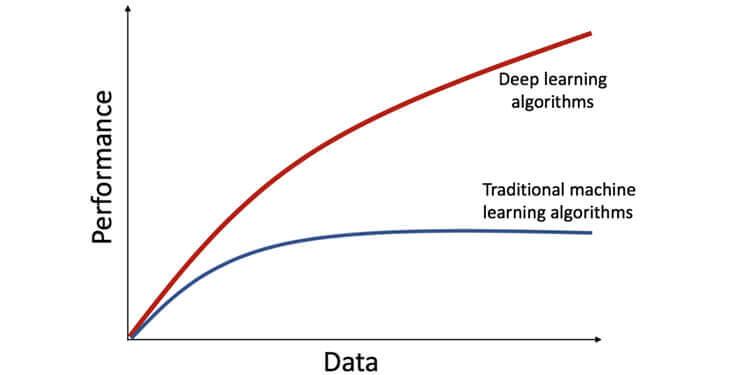
- Data dependency: Deep learning models require huge volumes of data as they do the feature extraction process on their own. But a machine learning model works perfectly well with smaller datasets. The depth of the network in a deep learning model increases with the data and hence the complexity of the deep learning model also increases. The following diagram shows that the performance of the deep learning model increases with increased data, but the machine learning models flattens the curve after a certain period.
- Computational Power: Deep learning networks are highly dependent on huge data which requires the support of GPUs rather than the normal CPUs. GPUs can maximize the processing of deep learning models as they can process multiple computations at the same time. The high memory bandwidth in GPUs makes them suitable for deep learning models. On the other hand machine learning models can be implemented on CPUs.
- Execution time: Normally deep learning algorithms take a long time to train due to the large number of parameters involved. The ResNet architecture which is an example of deep learning algorithm takes almost two weeks to train from the scratch. But machine learning algorithms takes less time to train (few minutes to a few hours). This is completely reversed with respect to the testing time. Deep learning algorithms take lesser time to run.
- Interpretability: It is easier to interpret machine learning algorithms and understand what is being done at each step and why it is being done. But deep learning algorithms are known as black boxes as one really does not know what is happening on the inside of the deep learning architecture. Which neurons are activated and how much they contribute to the output. So interpretation of machine learning models is much easier than the deep learning models.
Applications of Machine Learning
- Traffic Assistants: All of us use traffic assistants when we travel. Google Maps comes in handy to give us the routes to our destination and also shows us the routes with less traffic. Everyone who uses the maps are providing their location, route taken and their speed of driving to Google maps. These details about the traffic are collected by Google Maps and it tries to predict the traffic in your route and tries to adjust your route accordingly.
- Social media: The most common application of machine learning could be seen in automatic friend tagging and friend suggestions. Facebook uses Deep Face to do Image recognition and Face detection in digital images.
- Product Recommendation: When you browse through Amazon for a particular product but do not purchase them, then the next day when you open up YouTube or Facebook then you get to see ads relating to it. Your search history is being tracked by Google and it recommends products based on your search history. This is an application of machine learning technique.
- Personal Assistants: Personal assistants help in finding useful information. The input to a personal assistant could be either through voice or text. There is no one who could say that they don’t know about Siri and Alexa. Personal assistants can help in answering phone calls, scheduling meeting, taking notes, sending emails, etc.
- Sentiment Analysis: It is a real time machine learning application that can understand the opinion of people. Its application can be viewed in review based websites and in decision making applications.
- Language Translation: Translating languages is no more a difficult task as there is a hand full of language translators available now. Google’s GNMT is an efficient neural machine translation tool that can access thousands of dictionaries and languages to provide an accurate translation of sentences or words using the Natural Language Processing technology.
- Online Fraud Detection: ML algorithms can learn from historical fraud patterns and recognize fraud transaction in the future.ML algorithms have proved to be more efficient than humans in the speed of information processing. Fraud detection system powered by ML can find frauds that humans fail to detect.
- Healthcare services: AI is becoming the future of healthcare industry. AI plays a key role in clinical decision making thereby enabling early detection of diseases and to customize treatments for patients. PathAI which uses machine learning is used by pathologists to diagnose diseases accurately. Quantitative Insights is AI enabled software that improves the speed and accuracy in the diagnosis of breast cancer. It provides better results for patients through improved diagnosis by radiologists.
Applications of Deep Learning
- Self-driving cars: Autonomous driving cars are enabled by deep learning technology. Research is also being done at the Ai Labs to integrate features like food delivery into driverless cars. Data is collected from sensors, cameras and geo mapping helps to create more sophisticated models that can travel seamlessly through traffic.
- Fraud news detection: Detecting fraud news is very important in today’s world. Internet has become the source of all kinds of news both genuine and fake. Trying to identify fake news is a very difficult task. With the help of deep learning we can detect fake news and remove it from the news feeds.
- Natural Language Processing: Trying to understand the syntaxes, semantics, tones or nuances of a language is a very hard and complex task for humans. Machines could be trained to identify the nuances of a language and to frame responses accordingly with the help of Natural Language Processing technique. Deep learning is gaining popularity in applications like classifying text, twitter analysis, language modeling, sentiment analysis etc, which employs natural language processing.
- Virtual Assistants: Virtual assistants are using deep learning techniques to have an extensive knowledge about the subjects right from people’s dining out preferences to their favorite songs. Virtual assistants try to understand the languages spoken and try to carry out the tasks. Google has been working on this technology for many years called Google duplex which uses natural language understanding, deep learning and text-to–speech to help people book appointments anywhere in the middle of the week. And once the assistant is done with the job it will give you a confirmation notification that your appointment has been taken care of. The calls don’t go as expected but the assistant understands the context to nuance and handles the conversation gracefully.
- Visual Recognition: Going through old photographs could be nostalgic, but searching for a particular photo could become a tedious process as it involves sorting, and segregation which is time consuming. Deep learning can now be applied o images to sort them based on locations in the photographs, combination of peoples, according to some events or dates. Searching the photographs is no more a tedious and complex. Vision AI draws insights from images in the cloud with AutoML Vision or pretrained Vision API models to identify text, understand emotions in images.
- Coloring of Black and White images: Coloring a black and white image is like a child’s play with the help of Computer Vision algorithms that use deep learning techniques to bring about the life in the pictures by coloring them with the correct tones of color. The Colorful Image Colorization micro-services is an algorithm using computer vision technique and deep learning algorithms that are trained on the Imagenet database to color black and white images.
- Adding Sounds to Silent Movies: AI can now create realistic sound tracks for silent videos. CNNs and recurrent neural networks are employed to perform feature extraction and the prediction process. Research have shown that these algorithms that have learned to predict sound can produce better sound effects for old movies and help robots understand the objects in their surroundings.
- Image to Language Translation: This is another interesting application of deep learning. The Google translate app can automatically translate images into real time language of choice. The deep learning network reads the image and translates the text into the needed language.
- Pixel Restoration: The researchers in Google Brain have trained a Deep Learning network that takes a very low resolution image of a person faces and predicts the person’s face through it. This method is known as Pixel Recursive Super Resolution. This method enhances the resolution of photos by identifying the prominent features that is just enough for identifying the personality of the person.
Conclusion
This chapter has discovered the applications of machine learning and deep learning to give a clearer idea about the current and future capabilities of Artificial Intelligence. It is predicted that many applications of Artificial Intelligence will affect our lives in the near future. Predictive analytics and artificial intelligence are going to play a fundamental role in the future in content creation and also in the software development. Actually, the fact is they are already making an impact. Within the next few years, AI development tools, libraries, and languages will become the universally accepted standard components of every software development toolkit that you can name. The technology of artificial intelligence will become the future in all the domains including health, business, environment, public safety and security.
References
[1] Aditya Sharma(2018), “Differences Between Machine Learning & Deep Learning”
[2] Kislay Keshari(2020), “Top 10 Applications of Machine Learning : Machine Learning Applications in Daily Life”
[3] Brett Grossfeld(2020), “Deep learning vs machine learning: a simple way to understand the difference”
[4] By Nikita Duggal(2020), “Real-World Machine Learning Applications That Will Blow Your Mind”
[5] P. P. Shinde and S. Shah, “A Review of Machine Learning and Deep Learning Applications,” 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 2018, pp. 1-6
[6] https://www.javatpoint.com/machine-learning-life-cycle
[7] https://medium.com/app-affairs/9-applications-of-machine-learning-from-day-to-day-life-112a47a429d0
[8] Dan Shewan(2019), “10 Companies Using Machine Learning in Cool Ways”
[9] Marina Chatterjee(2019), “Top 20 Applications of Deep Learning in 2020 Across Industries
[10] A Tour of Machine Learning Algorithms by Jason Brownlee in Machine Learning Algorithms
[11] Jaderberg, Max, et al. “Spatial Transformer Networks.” In Advances in neural information processing systems (2015): 2017-2025.
[12] Van Veen, F. & Leijnen, S. (2019). The Neural Network Zoo. Retrieved from https://www.asimovinstitute.org/neural-network-zoo
[13] Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, ImageNet Classification with Deep Convolutional Neural Networks, [pdf], 2012
[14] Yadav, Neha, Anupam, Kumar, Manoj, An Introduction to Neural Networks for Differential Equations (ISBN: 978-94-017-9815-0)
[15] Hugo Mayo, Hashan Punchihewa, Julie Emile, Jackson Morrison History of Machine Learning, 2018
[16] Pedro Domingos , 2012, Tapping into the “folk knowledge” needed to advance machine learning applications. by A Few Useful, doi:10.1145/2347736.2347755
[17] Alex Smola and S.V.N. Vishwanathan, Introduction to Machine Learning, Cambridge University Press 2008
[18] Antonio Guili and Sujit Pal, Deep Learning with Keras: Implementing deep learning models and neural networks with the power of Python, Release year: 2017; Packt Publishing Ltd.
[19] AurÈlien GÈron ,Hands-On Machine Learning with Scikit-Learn and Tensor Flow: Concepts, Tools, and Techniques to Build Intelligent Systems, Release year: 2017. O’Reilly
[20] Best language for Machine Learning: Which Programming Language to Learn, August 31, 2020, Springboard India.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- Platoblockchain. Web3 Metaverse Intelligence. Knowledge Amplified. Access Here.
- Source: https://www.mygreatlearning.com/blog/machine-learning-and-deep-learning/

