مرحبًا ، أيها التقنيون ، أنا متأكد من أن هذه المقالة ستساعدك على فهم كيفية استخدام دفتر بيانات Azure Databricks لإجراء العمليات المتعلقة بالبيانات فيه. لنذهب!
Databricks
علوم وهندسة البيانات Databricks (تسمى أحيانًا ببساطة "مساحة العمل") عبارة عن منصة تحليلات تستند إلى Apache Spark. يتكامل مع Azureو AWS و GCP لتوفير إعداد بنقرة واحدة ، وسير عمل مبسط ، ومساحة عمل تفاعلية تتيح التعاون بين مهندسي البيانات وعلماء البيانات ومهندسي التعلم الآلي.
Azure Databricks عبارة عن نظام أساسي لتحليل البيانات مُحسَّن لمنصة خدمات Microsoft Azure السحابية. تقدم Azure Databricks بيئتين لتطوير التطبيقات كثيفة البيانات: علوم وهندسة البيانات Databricks ، و Databricks آلة التعلم. Azure هو موفر خدمة الطرف الأول لـ Databricks (بمعنى أن Azure ستوفر جميع خدمات الدعم لقواعد البيانات على السحابة الخاصة بها). يمكنك أن ترى مساحة عمل قواعد البيانات أدناه: -
خطوات إنشاء خدمة قواعد بيانات Azure
المتطلبات المسبقة
يجب أن يكون لديك اشتراك Azure مجاني من الطبقة على الأقل.
خطوة 1 - افتح بوابة Azure (portal.azure.com)
الخطوة 2: - لإنشاء خدمة Databricks ، تحتاج إلى النقر فوق رمز "إنشاء مورد".
الخطوة 2.1: - ابحث الآن عن ملف "Azure Databricks" الخدمة ثم انقر فوق خيار إنشاء الزر.
الخطوة 2.2: - املأ الآن التفاصيل المطلوبة لإنشاء الخدمة في قسم تفاصيل المشروع.
حدد المناسب اشتراك من القائمة المنسدلة ، بالنسبة لي ، أنا أستخدم نسخة تجريبية مجانية لذلك سأختار الخيار الافتراضي المتاح.
الآن عليك إنشاء ملف مجموعة الموارد، فقط انقر فوق إنشاء جديد إذا لم يكن لديك خلاف ذلك اختر واحدًا من خيارات القائمة المنسدلة.
الآن عليك أن تملأ تفاصيل المثيل توفر الأقسام أدناه
اسم مساحة العمل: - أدخل اسم مساحة العمل الخاصة بك
بلد المنشأ: - اختر المنطقة المناسبة لك. سأختار الافتراضي.
فئة التسعير: - سأختار المعيار القياسي.
الخطوة 2.3: - الآن سأحتفظ بأشياء أخرى بشكل افتراضي وانقر فوق التالي في أقسام الشبكات والتقدم والعلامة.
الخطوة 2.5: - بمجرد ظهور الرسالة "تم التحقق من الصحة" is عرض، اضغط على "خلق" .
الخطوة 2.6: - الآن انقر فوق go to service وسيتم إعادة توجيهك إلى صفحة خدمة قاعدة بيانات azure الخاصة بك ، انقر فوق "إطلاق مساحة العمل" وستتم إعادة توجيهك إلى مساحة العمل الخاصة بك.
الآن تم إنشاء خدمة قواعد البيانات اللازوردية الخاصة بنا. حان الوقت لإنشاء مجموعة لتشغيل دفتر الملاحظات. لنقم بإنشاء ...
إنشاء الكتلة في Databricks
الخطوة 1:- من خيارات قائمة مجموعات قواعد البيانات المتوفرة ، انقر فوق "حساب" لإنشاء مجموعة.
الخطوة 2:- ستتم إعادة توجيهك إلى صفحة الحساب ، هنا ستحصل على نوعين من خيارات إنشاء المجموعات ، أحدهما "مجموعات لجميع الأغراض" والآخر هو "مجموعة الوظائف".
مجموعة لجميع الأغراض: - هم تُستخدم لتحليل البيانات باستخدام أجهزة الكمبيوتر المحمولة وتنفيذ أعمال استيعاب البيانات وتحويلها باستخدام أجهزة الكمبيوتر المحمولة.
مجموعة الوظائف: - يتم استخدامها لتنفيذ المهمة أو جدولة الغرض من أجهزة الكمبيوتر المحمولة لأداء العمليات المكتوبة داخل أجهزة الكمبيوتر المحمولة.
هنا سنقوم بإنشاء مجموعات لجميع الأغراض ، انقر الآن على زر إنشاء مجموعة.
الخطوة 3:- الآن سيتم نقلك إلى صفحة إنشاء الكتلة الجديدة. هنا سيكون عليك ضبط التفاصيل التالية: -
اسم الكتلة: - اختر الاسم الذي تريد أن تطلقه على مجموعتك. لقد قدمت "blogdemocls".
وضع الكتلة: - هنا سوف تحصل على ثلاثة خيارات "التزامن مرتفع", "ستاندارد" و "عقدة واحدة". حاليًا ، أنا في المستوى المجاني لذلك سأختار "عقدة واحدة". يمكنك اختيار خيارات أخرى حسب متطلبات الحوسبة الخاصة بك.
إصدار Databricks Runtime: - في هذا ، سيتم تزويدك بإصدارات مختلفة لوقت التشغيل من Scala و Spark. في هذا ، سأختار أحدث إصدار مع خيار LTS (دعم طويل الأجل). يمكنك الاختيار حسب متطلباتك.
خيارات الطيار الآلي: - في هذا ، يمكنك تحديد وقت الخمول. يتم إيقاف الكتلة إذا أصبحت خاملة لوقت الخمول المحدد.
ملاحظة: - إذا اخترت وضع مجموعة آخر ، فستحصل على خيارين آخرين "نوع العامل" و "نوع برنامج التشغيل". لكننا حاليًا في المستوى المجاني ، لذلك ، تم تعطيل هذين الخيارين بالنسبة لنا.
نوع العقدة: - هنا سوف تحدد تكوين جهازك الذي تحتاجه لمعالجة بياناتك. مثل مقدار الذاكرة والأنوية التي تحتاجها. ستحصل على الكثير من الخيارات ، سواء كانت حاجتك للحساب أو الذاكرة أو التخزين ، يمكنك الاختيار من بينها. في هذا ، سوف نختار أ للأغراض العامة ، جهاز قياسي D4a_v4 مع ذاكرة 16 جيجا بايت و 4 مراكز. يمكنك العثور على هذا الجهاز في فئة الأغراض العامة ثم النقر فوق المزيد من الخيارات.
انقر الآن على زر إنشاء الكتلة وانتظر إنشائها. الآن عندما يتم إنشاؤه ، انقر الآن على زر البدء وسيبدأ في غضون 3 إلى 5 دقائق.
إنشاء دفتر الملاحظات
الآن يتم تشغيل مجموعتنا وسنقوم بإنشاء أول دفتر ملاحظات خاص بنا من وحدات قاعدة البيانات.
الخطوة 1:- انتقل إلى مساحة العمل وانقر عليها ثم انقر فوق سهم القائمة المنسدلة في مساحة العمل وأنشئ مجلدًا جديدًا للاحتفاظ بجميع دفاتر الملاحظات بداخله. سنقوم بتسمية هذا المجلد "inshortsnews".
الخطوة 2:- انقر الآن على سهم مجلد القائمة المنسدلة "inshortsnews" وانقر على إنشاء ثم انقر على دفتر الملاحظات.
الخطوة 2.1:- قدم الآن جميع التفاصيل لإنشاء دفتر ملاحظات مثل اسم، أعطي اسم "إحاطة-أخبار-بيانات-كشط" لمفكرتنا ، اللغة الافتراضية، سوف نختار "Python". إذا كنت تريد ، يمكنك أيضًا الاختيار بين R و Scala و SQL كلغة افتراضية لمشروعك.
الخطوة 2.2:- انقر فوق إنشاء وسيتم إنشاء دفتر الملاحظات باللغة المتوفرة.
تخريد الأخبار الداخلية
سنقوم الآن بكشط بيانات الأخبار من تطبيق الويب الإخباري Inshorts باستخدام Python و pandas والمكتبات الأخرى.
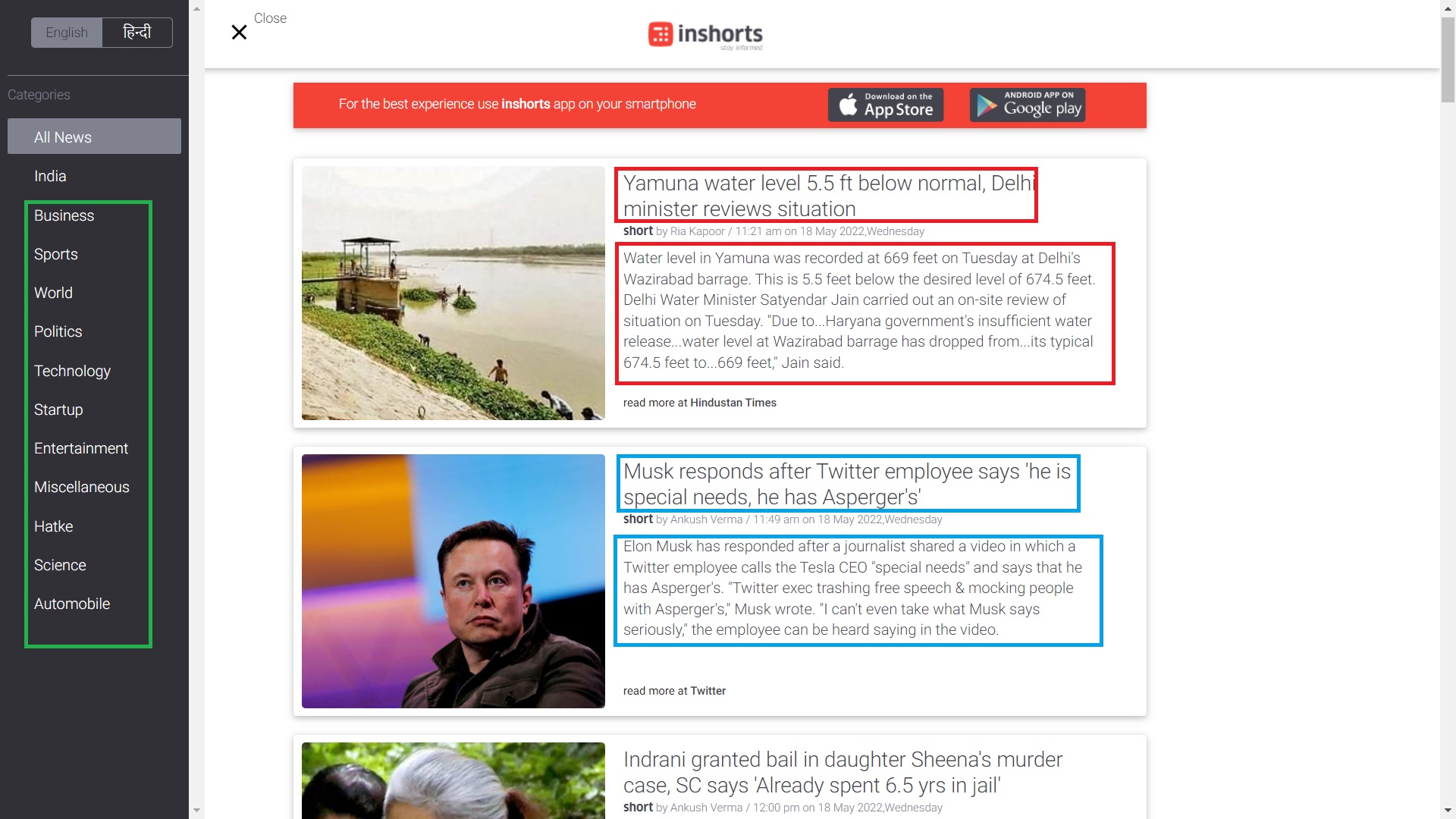
في سراويل هو تطبيق مجمّع يلخص المقالات الإخبارية في 60 كلمة ويغطي مجموعة واسعة من الموضوعات ، بما في ذلك التكنولوجيا والأعمال والمحتويات الأخرى مثل مقاطع الفيديو والرسوم البيانية والمدونات. في الصورة أدناه ، سنقوم بكشط البيانات الموجودة داخل المربعات المستطيلة.
في هذا ، سنقوم بكشط المقال عناوين الأخبار, محتويات الأخبار، و فئة المقالات الإخبارية.
عنوان الأخبار: - عبارة عن جملة مكونة من سطر واحد تحتوي على نظرة عامة على المقالة الإخبارية.
مقالة أخبار: - إنها جملة متعددة الأسطر وتحتوي على المعلومات الكاملة عن الأخبار في 60 كلمة.
الأخبار الفئة: - يروي فئة المقال الإخباري.
مثال
news_headline: - تشارك شركة Musk's Boring Company لمحة عن محطة Las Vegas Loop.
news_article: - شاركت شركة Boring Company مقطعًا قصيرًا على Twitter يظهر إحدى محطات مترو الأنفاق التي تبنيها الشركة كجزء من حلقة مركز مؤتمرات لاس فيجاس (LVCC). في سبتمبر ، قال المؤسس إيلون ماسك إن أول نفق تشغيلي تحت فيغاس قد اكتمل تقريبًا. وأضاف: "ستبدو الأنفاق تحت المدن ذات السيارات الكهربائية ذاتية القيادة وكأنها قيادة ملتوية".
new_category: - تكنولوجيا
تم تصنيف المقالات إلى العديد من الفئات ولكننا سنقوم بكشط 7 فئات مختلفة فقط وهي كالتالي: - technology, sports, politics, entertainment, world, automobile و science.
لنبدأ الترميز
لجمع هذه البيانات ، استخدمت المكتبات التالية requests, BeautifulSoup4و pandas. لذا لاستخدام هذه المكتبات ، يتعين علينا أولاً تثبيتها في دفتر ملاحظاتنا. نحن بحاجة فقط للتثبيت شوربة جميلة lib والباقيان مزودان بالفعل بدفترنا الدفتري.
الخطوة 1:- لتثبيت مكتبات داخل دفاتر قواعد البيانات نستخدم الطريقة التالية: -
الخطوة 2:- الآن قم باستيراد جميع المكتبات المطلوبة
الخطوة 3:- حدد الآن نقاط النهاية لكل فئة من حيث نريد كشط البيانات.
الخطوة 04:- سنرسل الآن طلبات لكل من "عناوين URL" المحددة أعلاه ثم نقوم بتجميل بيانات الاستجابة. ثم استخدمنا قائمة الفهم للعثور على جميع عناوين الأخبار والمحتوى الجديد من بيانات الاستجابة. قمنا أيضًا بتقسيم عناوين URL للحصول على فئة الأخبار.
الخطوة 05:- قم بإنشاء إطار البيانات من قاموس البيانات التي قمنا بكشطها من تطبيق الويب الإخباري Inshorts.
هتافات!!! عند الوصول إلى نهاية الدليل وتعلم أنواع مثيرة جدًا من الأشياء حول Azure Databricks. من هذا الدليل ، تعلمت بنجاح كيفية تشغيل خدمات قواعد البيانات في سحابة أزور. إلى جانب ذلك ، تعلمت أيضًا كيفية إنشاء مجموعات لأجهزة الكمبيوتر المحمولة في قوالب البيانات وأساسيات تجميع البيانات باستخدام Python و pandas.
الآن في المقالة التالية سوف نستكشف أzure Data Lake Storage Gen2 (ADLS Gen2)، وكيفية إنشاء خدمات تخزين ADLS gen2 ، وإلى جانب ذلك ، سنقوم بحفظ بياناتنا المسردة في حساب التخزين هذا عن طريق جدولة دفتر ملاحظاتنا على أساس كل ساعة باستخدام مصنع بيانات Azure (ADF) أساليب. من خلال القيام بذلك ، نقوم بإنشاء مجموعة البيانات النصية الخاصة بنا لمهام البرمجة اللغوية العصبية.
لا تتردد في الاتصال بي على لينكدين: و جيثب لمزيد من المحتوى حول هندسة البيانات والتعلم الآلي!
تعلم سعيد !!!
الوسائط الموضحة في هذه المقالة ليست مملوكة لـ Analytics Vidhya ويتم استخدامها وفقًا لتقدير المؤلف.














.png)






