المُقدّمة
يتضمن تصنيف المشاعر في نص الجملة باستخدام الشبكات العصبية إسناد المشاعر إلى جزء من النص. يمكن تحقيقه من خلال تقنيات مثل الشبكات العصبية أو الأساليب القائمة على المعجم. تتضمن الشبكات العصبية تدريب نموذج على بيانات نصية مميزة للتنبؤ بالعواطف في نص جديد. تستخدم الأساليب القائمة على المعجم قواميس الكلمات المرتبطة بالعاطفة. على الرغم من صعوبة تصنيف المشاعر النصية ، إلا أن تصنيف المشاعر النصية له العديد من التطبيقات المحتملة.

الهدف الرئيسي من تصنيف المشاعر النصية هو:
- لفهم الحالة العاطفية للمؤلف. يمكن أن يكون هذا مفيدًا في مجموعة متنوعة من السياقات ، مثل خدمة العملاء والرعاية الصحية والتعليم.
- لتحسين دقة أنظمة الترجمة الآلية. غالبًا ما تكافح أنظمة الترجمة الآلية لترجمة النص المشحون عاطفيًا بشكل صحيح.
- لتطوير تطبيقات جديدة لوسائل التواصل الاجتماعي وغيرها من المنصات عبر الإنترنت. على سبيل المثال ، يمكن استخدام تصنيف المشاعر النصية للتوصية بالمحتوى للمستخدمين بناءً على حالتهم العاطفية.
بناءً على هذه الأهداف ، سنقوم بتصنيف المشاعر في نص الجملة باستخدام خوارزمية الشبكة العصبية لتطوير نموذج يمكنه تصنيف الحالة العاطفية على النص بدقة. ستوجهك هذه المقالة خلال خطوة بخطوة في تصنيف مدخلات المستخدم النصية بمشاعر محددة.
جدول المحتويات
الخطوة 1: استيراد مكتبة
import pandas as pd
import numpy as np
import keras
import tensorflow
from keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers import Embedding, Flatten, Denseنقوم باستيراد "Tokenizer" لتحويل النص إلى سلسلة من الرموز المميزة. يتم استخدام 'pad_sequences' لتضخيم التتابعات إلى طول ثابت. إنه ضروري لأن الشبكات العصبية تتوقع مدخلات بحجم ثابت. يتم استخدام "LabelEncoder" لتحويل البيانات الفئوية إلى بيانات رقمية. يتم استخدام المتسلسلة لإنشاء حزمة خطية من الطبقات. بعد ذلك ، يتم استخدام "التضمين" لتحويل الكلمات إلى متجهات لتمثيل معنى الكلمات. يتم استخدام "التسطيح" لتسطيح موتر متعدد الأبعاد إلى موتر 1D. أخيرًا ، يتم استخدام 'Dense' لتطبيق تحويل غير خطي إلى موتر إدخال.
الخطوة 2: اقرأ البيانات
مجموعة البيانات التي حمّلها Praveen عليها Kaggle مناسب لمهمة تصنيف المشاعر في النص ، وهو مناسب جدًا في هذه الحالة. ومع ذلك ، فقد وضعته على GitHub الخاص بي لتسهيل المزيد من التحليل.
url = "https://raw.githubusercontent.com/ataislucky/Data-Science/main/dataset/emotion_train.txt"
data = pd.read_csv(url, sep=';')
data.columns = ["Text", "Emotions"]
print(data.head())
يصف الكود كيفية قراءة ملف نصي من عنوان URL وتخزينه في Pandas DataFrame. يحتوي الملف النصي على قائمة بالجمل وتسميات المشاعر. لذا ، فإن مجموعة البيانات التي نستخدمها تتكون فقط من عمودين.
الخطوة 3: المعالجة المسبقة للبيانات
تعد المعالجة المسبقة للبيانات خطوة مهمة في تصنيف المشاعر النصية. يتضمن ذلك عملية تنظيف البيانات وإعدادها لاستخدامها بواسطة نماذج التعلم الآلي. تتضمن بعض خطوات المعالجة المسبقة للبيانات الشائعة لتصنيف عاطفة النص الترميز ، وإيقاف إزالة الكلمات ، وإزالة اللمات ، وما إلى ذلك بشكل عام ، تتمثل التحديات في تنفيذ عملية المعالجة الأولية في تنظيف البيانات واختيار البيانات وتنسيقات البيانات.
الرمز المميز هو وظيفة تقوم بتقسيم سلسلة نصية إلى كلمات فردية أو رموز مميزة. لذلك ، لوضع علامة على السلاسل النصية ، يجب أولاً تغيير نوع بيانات السلسلة إلى قائمة. هذا لأن القائمة عبارة عن مجموعة من الكائنات ، ويمكن أن يكون كل كائن في القائمة كلمة أو رمزًا مميزًا.
texts = data["Text"].tolist()
labels = data["Emotions"].tolist()ثم يتم محاذاة الكائن المميز مع قائمة النص. يهدف إلى تعلم الرموز المميزة الفريدة في البيانات النصية. من خلال ترميز البيانات النصية ، يمكن للكائنات المميزة تحويل البيانات النصية إلى تنسيق يمكن استخدامه بواسطة نماذج التعلم الآلي.
# Tokenize the text data
tokenizer = Tokenizer()
tokenizer.fit_on_texts(texts)الآن ، كل ما علينا فعله هو وضع طبقات متتابعة متساوية الطول وإدخالها في الشبكة العصبية. إليك كيف يمكننا وضع سلسلة من النصوص في طبقات بحيث تكون بنفس الطول:
sequences = tokenizer.texts_to_sequences(texts)
max_length = max([len(seq) for seq in sequences])
padded_sequences = pad_sequences(sequences, maxlen=max_length)بعد ذلك ، سوف نستخدم طريقة تشفير التسمية لتحويل نوع البيانات من سلسلة إلى بيانات رقمية.
# Encode the string labels to integers
label_encoder = LabelEncoder()
labels = label_encoder.fit_transform(labels)نقوم بعد ذلك بإجراء تشفير واحد ساخن لتمثيل البيانات الفئوية في نموذج التعلم الآلي. هذا لأن العديد من نماذج التعلم الآلي ، مثل الشبكات العصبية ، تتوقع أن تكون بيانات الإدخال بتنسيق رقمي. دعنا نقوم به.
# One-hot encode the labels
one_hot_labels = keras.utils.to_categorical(labels)الخطوة 4: بناء نموذج وعمل تنبؤات
بعد إجراء المعالجة المسبقة ، سنبدأ في الإنشاء نماذج التعلم الآلي.
قد ننفذ تقنية ، وهي تقسيم مجموعة البيانات إلى مجموعة تدريب ومجموعة اختبار ، لتسهيل تقييم أداء النموذج على البيانات التي لم يسبق رؤيتها من قبل. إن القدرة على التحقق من أن النموذج لا يلائم مجموعة البيانات التدريبية تجعل هذا أمرًا بالغ الأهمية.
# Split the data into training and testing sets
xtrain, xtest, ytrain, ytest = train_test_split(padded_sequences, one_hot_labels, test_size=0.2)دعنا الآن نحدد بنية الشبكة العصبية لتدريب النموذج وتصنيف المشاعر.
# Define the model
model = Sequential()
model.add(Embedding(input_dim=len(tokenizer.word_index) + 1, output_dim=128, input_length=max_length))
model.add(Flatten())
model.add(Dense(units=128, activation="relu"))
model.add(Dense(units=len(one_hot_labels[0]), activation="softmax")) model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
model.fit(xtrain, ytrain, epochs=10, batch_size=32, validation_data=(xtest, ytest))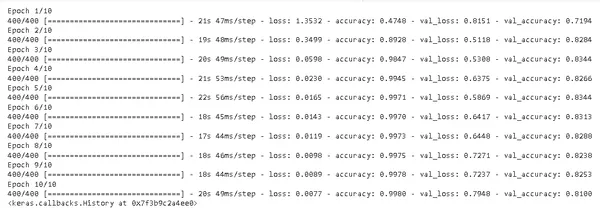
يتم تدريب النموذج لمدة عشر فترات ، وتتكون كل فترة من تدريب النموذج على بيانات التدريب ثم تقييمه على بيانات التحقق من الصحة. يتم استخدام التحقق من صحة البيانات لتقييم أداء النموذج مقابل البيانات غير المرئية سابقًا. هذا مهم لأنه يضمن أن النموذج لا يفرط في بيانات التدريب.
بعد تدريب النموذج ، يصبح جاهزًا لاستخدامه في عمل تنبؤات بشأن البيانات الجديدة.
#input_text from user
input_text = input("Please input sentence here : ") # Preprocess the input text
input_sequence = tokenizer.texts_to_sequences([input_text])
padded_input_sequence = pad_sequences(input_sequence, maxlen=max_length)
prediction = model.predict(padded_input_sequence)
predicted_label = label_encoder.inverse_transform([np.argmax(prediction[0])])
print(predicted_label)
في الناتج الناتج ، أدخل المستخدم الجملة "لم تأت اليوم لأن والدتها ماتت أمس". يتنبأ النموذج بأن عاطفة الجملة هي الحزن.
يتم تدريبه على مجموعة بيانات من الجمل المصنفة بمشاعرهم. يتعلم هذا النموذج ربط كلمات وعبارات معينة بمشاعر معينة. كثيرا ما يرتبط مصطلح "مات" بالحزن. عندما تكتشف الخوارزمية كلمة "مات" في عبارة ما ، فإنها على الأرجح تتنبأ بالحزن.
وفي الختام
تبدأ هذه المقالة بالمعالجة المسبقة ، والتي تتضمن تغيير تنسيق إطار البيانات إلى قائمة ، وعملية الترميز ، وتسميات التشفير ، وما إلى ذلك. بالمناسبة ، في هذا المنشور ، ناقشنا ما يلي:
- تصنيف العواطف في نص الجملة باستخدام الشبكات العصبية يمكن تصنيف المشاعر المعبر عنها في البيانات النصية.
- تلعب هندسة الميزات دورًا مهمًا في تصنيف المشاعر النصية لأن استخراج الميزات ذات الصلة من النص يمكن أن يحسن أداء النموذج.
- تدريب نموذج شبكة عصبية على بيانات نصية معنونة لتعلم النماذج الأصلية والارتباطات بين النص والمشاعر المقابلة.
- توفر الشبكات العصبية ميزة التقاط الأنماط والعلاقات المعقدة في البيانات النصية ، مما يتيح التصنيف الدقيق للعواطف.
بشكل عام ، تقدم هذه المقالة دليلاً شاملاً لتصنيف المشاعر النصية باستخدام شبكة عصبية باستخدام Python. لا تتردد في طرح أسئلة قيمة في قسم التعليقات أدناه. الكود الكامل هو هنا.
مقالات ذات صلة
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- أفلاطونايستريم. ذكاء بيانات Web3. تضخيم المعرفة. الوصول هنا.
- سك المستقبل مع أدرين أشلي. الوصول هنا.
- شراء وبيع الأسهم في شركات ما قبل الاكتتاب مع PREIPO®. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2023/05/classifying-emotions-in-sentence-text-using-neural-networks/

