صورة من Bing Image Creator
من لم يكن مستمتعًا بالتقدم التكنولوجي خاصةً في الذكاء الاصطناعي، من Alexa إلى Tesla للسيارات ذاتية القيادة وعدد لا يحصى من الابتكارات الأخرى؟ إنني مندهش من التطورات التي تحدث كل يوم ، ولكن الأمر الأكثر إثارة للاهتمام هو عندما تحصل على فكرة عما يدعم هذه الابتكارات. مرحبا بك في الذكاء الاصطناعي وإلى الاحتمالات اللانهائية التعلم العميق. إذا كنت تتساءل عما هو عليه ، فأنت في المنزل.
في هذا البرنامج التعليمي ، سأقوم بتفكيك المصطلحات وأخذك في جولة حول كيفية أداء مهمة التعلم العميق في R. للإشارة إلى أن هذه المقالة ستفترض أن لديك بعض الفهم الأساسي لـ آلة التعلم مفاهيم مثل تراجعوالتصنيف و المجموعات.
لنبدأ بتعريفات بعض المصطلحات المحيطة بمفهوم التعلم العميق:
تعلم عميق هو فرع من فروع التعلم الآلي الذي يعلم أجهزة الكمبيوتر لتقليد الوظائف المعرفية للدماغ البشري. يتم تحقيق ذلك من خلال استخدام الشبكات العصبية الاصطناعية التي تساعد على فك الأنماط المعقدة في مجموعات البيانات. باستخدام التعلم العميق ، يمكن لجهاز الكمبيوتر تصنيف الأصوات أو الصور أو حتى النصوص.
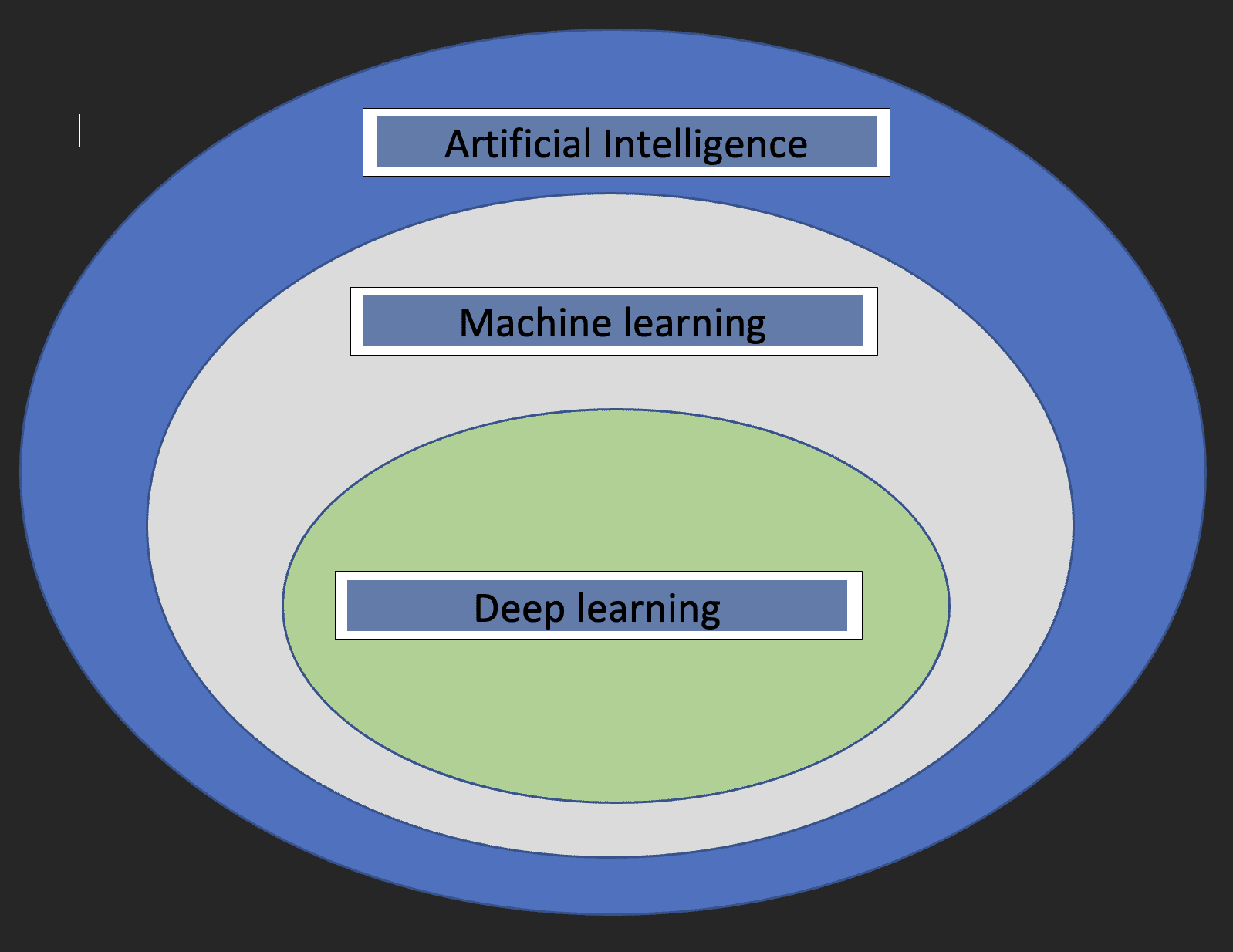
قبل أن نتعمق في تفاصيل التعلم العميق ، سيكون من الجيد أن نفهم ما هو التعلم الآلي والذكاء الاصطناعي وكيف ترتبط المفاهيم الثلاثة ببعضها البعض.
الذكاء الاصطناعي: هذا فرع من فروع علوم الكمبيوتر يهتم بتطوير الآلات التي يحاكي عملها الدماغ البشري.
تعلم الآلة: هذه مجموعة فرعية من الذكاء الاصطناعي تمكن أجهزة الكمبيوتر من التعلم من البيانات.
مع التعريفات المذكورة أعلاه ، لدينا الآن فكرة عن مدى ارتباط التعلم العميق بالذكاء الاصطناعي والتعلم الآلي.
سيساعد الرسم البياني أدناه في إظهار العلاقة.
هناك شيئان مهمان يجب ملاحظتهما حول التعلم العميق هما:
- يتطلب كميات ضخمة من البيانات
- يتطلب قوة حوسبة عالية الأداء
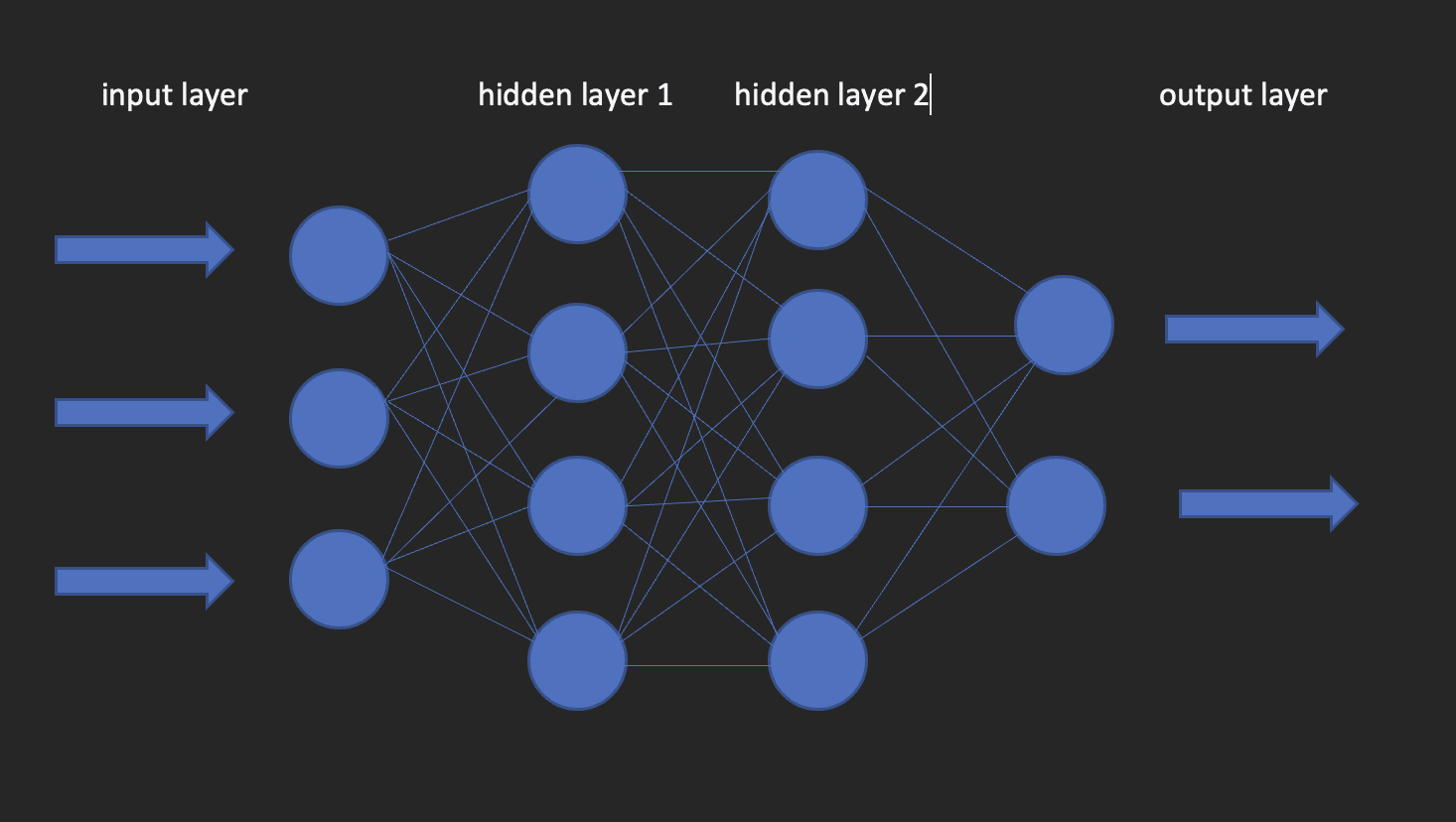
هذه هي اللبنات الأساسية لنماذج التعلم العميق. كما يوحي الاسم ، تأتي كلمة عصبي من الخلايا العصبية ، تمامًا مثل الخلايا العصبية في الدماغ البشري. في الواقع ، تستمد بنية الشبكات العصبية العميقة إلهامها من بنية الدماغ البشري.
تحتوي الشبكة العصبية على طبقة إدخال وطبقة مخفية وطبقة إخراج. تسمى هذه الشبكة بالشبكة العصبية الضحلة. عندما يكون لدينا أكثر من طبقة مخفية ، فإنها تصبح شبكة عصبية عميقة ، حيث يمكن أن يصل عدد الطبقات إلى 100.
توضح الصورة أدناه كيف تبدو الشبكة العصبية.
هذا يقودنا إلى مسألة كيفية بناء نماذج التعلم العميق في R؟ أدخل كيرا!
Keras هي مكتبة تعلم عميق مفتوحة المصدر تسهل استخدام الشبكات العصبية في التعلم الآلي. هذه المكتبة عبارة عن غلاف يستخدم TensorFlow كمحرك خلفي. ومع ذلك ، هناك خيارات أخرى للواجهة الخلفية مثل Theano أو CNTK.
دعونا الآن نثبت كلاهما TensorFlow وكيراس.
ابدأ بإنشاء بيئة افتراضية باستخدام شبكي
library(reticulate)
virtualenv_create("virtualenv", python = "/path/to/your/python3") install.packages(“tensorflow”) #This is only done once! library(tensorflow) install_tensorflow(envname = "/path/to/your/virtualenv", version = "cpu") install.packages(“keras”) #do this once! library(keras) install_keras(envname = "/path/to/your/virtualenv") # confirm the installation was successful
tf$constant("Hello TensorFlow!")
الآن بعد أن تم تعيين التكوينات الخاصة بنا ، يمكننا التوجه إلى كيفية استخدام التعلم العميق لحل مشكلة التصنيف.
البيانات التي سأستخدمها في هذا البرنامج التعليمي مأخوذة من مسح الرواتب المستمر الذي تم إجراؤه بواسطة https://www.askamanager.org.
السؤال الرئيسي المطروح في النموذج هو مقدار الأموال التي تجنيها ، بالإضافة إلى بعض التفاصيل الأخرى مثل الصناعة والعمر وسنوات الخبرة وما إلى ذلك. يتم جمع التفاصيل في ورقة Google التي حصلت منها على البيانات.
المشكلة التي نريد حلها بالبيانات هي أن نكون قادرين على التوصل إلى نموذج تعلم عميق يتنبأ بالمقدار الذي يمكن أن يكسبه شخص ما بمعلومات معينة مثل العمر والجنس وسنوات الخبرة وأعلى مستوى من التعليم.
قم بتحميل المكتبات التي سنطلبها.
library(dplyr)
library(keras)
library(caTools)
استيراد البيانات
url - “https://raw.githubusercontent.com/oyogo/salary_dashboard/master/data/salary_data_cleaned.csv” salary_data - read.csv(url)
حدد الأعمدة التي نحتاجها
salary_data - salary_data %>% select(age,professional_experience_years,gender,highest_edu_level,annual_salary)
هل تتذكر مفهوم GIGO لعلوم الكمبيوتر؟ (القمامة في القمامة). حسنًا ، هذا المفهوم قابل للتطبيق تمامًا هنا كما هو الحال في المجالات الأخرى. ستعتمد نتائج تدريبنا إلى حد كبير على جودة البيانات التي نستخدمها. هذا هو ما يجلب تنظيف البيانات وتحويلها ، وهي خطوة حاسمة في أي العلوم البيانات مشروع.
بعض القضايا الرئيسية التي يسعى تنظيف البيانات إلى معالجتها هي ؛ التناسق والقيم المفقودة ومشكلات التهجئة والقيم المتطرفة وأنواع البيانات. لن أخوض في التفاصيل حول كيفية معالجة هذه المشكلات وهذا لسبب بسيط هو عدم الرغبة في الاستغناء عن موضوع هذه المقالة. لذلك ، سأستخدم النسخة النظيفة من البيانات ولكن إذا كنت مهتمًا بمعرفة كيفية التعامل مع لقمة التنظيف ، فراجع هذه المقالة.
تقبل الشبكات العصبية الاصطناعية المتغيرات الرقمية فقط ونرى أن بعض المتغيرات لدينا ذات طبيعة فئوية ، سنحتاج إلى ترميز هذه المتغيرات إلى أرقام. هذا ما يشكل جزءًا من معالجة البيانات خطوة ضرورية لأنه في أغلب الأحيان ، لن تحصل على بيانات جاهزة للنمذجة.
# create an encoder function
encode_ordinal - function(x, order = unique(x)) { x - as.numeric(factor(x, levels = order, exclude = NULL))
} salary_data - salary_data %>% mutate( highest_edu_level = encode_ordinal(highest_edu_level, order = c("High School","College degree","Master's degree","Professional degree (MD, JD, etc.)","PhD")), professional_experience_years = encode_ordinal(professional_experience_years, order = c("1 year or less", "2 - 4 years","5-7 years", "8 - 10 years", "11 - 20 years", "21 - 30 years", "31 - 40 years", "41 years or more")), age = encode_ordinal(age, order = c( "under 18", "18-24","25-34", "35-44", "45-54", "55-64","65 or over")), gender = case_when(gender== "Woman" ~ 0, gender == "Man" ~ 1))
نظرًا لأننا نريد حل تصنيف ، نحتاج إلى تصنيف الراتب السنوي إلى فئتين حتى نستخدمه كمتغير استجابة.
salary_data - salary_data %>% mutate(categories = case_when( annual_salary = 100000 ~ 0, annual_salary > 100000 ~ 1)) salary_data - salary_data %>% select(-annual_salary)كما هو الحال في مناهج التعلم الآلي الأساسية ؛ الانحدار والتصنيف والتكتل ، سنحتاج إلى تقسيم بياناتنا إلى مجموعات تدريب واختبار. نقوم بذلك باستخدام قواعد 80-20 ، والتي تمثل 80٪ من مجموعة البيانات للتدريب و 20٪ للاختبار. هذا لا يتم إلقاؤه على الحجارة ، حيث يمكنك أن تقرر استخدام أي نسب مقسمة كما تراه مناسبًا ، ولكن ضع في اعتبارك أن مجموعة التدريب يجب أن يكون لها نصيب جيد من النسب المئوية.
set.seed(123) sample_split - sample.split(Y = salary_data$categories, SplitRatio = 0.7)
train_set - subset(x=salary_data, sample_split == TRUE)
test_set - subset(x = salary_data, sample_split == FALSE) y_train - train_set$categories
y_test - test_set$categories
x_train - train_set %>% select(-categories)
x_test - test_set %>% select(-categories)
يأخذ Keras المدخلات في شكل مصفوفات أو مصفوفات. نستخدم الدالة as.matrix للتحويل. نحتاج أيضًا إلى قياس متغيرات التوقع ثم نقوم بتحويل متغير الاستجابة إلى نوع بيانات فئوي.
x - as.matrix(apply(x_train, 2, function(x) (x-min(x))/(max(x) - min(x)))) y - to_categorical(y_train, num_classes = 2)تجسيد النموذج
قم بإنشاء نموذج تسلسلي نضيف إليه طبقات باستخدام مشغل الأنابيب.
model = keras_model_sequential()تكوين الطبقات
• إدخال_الشكل يحدد شكل بيانات الإدخال. في حالتنا ، حصلنا على ذلك باستخدام ncol وظيفة. تفعيل: هنا نحدد وظيفة التنشيط ؛ دالة رياضية تحول الإخراج إلى تنسيق غير خطي مرغوب قبل تمريره إلى الطبقة التالية.
الوحدات: عدد الخلايا العصبية في كل طبقة من طبقات الشبكة العصبية.
model %>% layer_dense(input_shape = ncol(x), units = 10, activation = "relu") %>% layer_dense(units = 10, activation = "relu") %>% layer_dense(units = 2, activation = "sigmoid")نحن نستخدم طريقة الترجمة للقيام بذلك. تأخذ الوظيفة ثلاث حجج ؛
محسن : هذا الكائن يحدد إجراء التدريب. خسارة : هذه هي وظيفة التقليل أثناء التحسين. الخيارات المتاحة هي mse (متوسط الخطأ التربيعي) و binary_crossentropy و categorical_crossentropy.
المقاييس : ما نستخدمه لمراقبة التدريب. الدقة لمشاكل التصنيف.
model %>% compile( loss = "binary_crossentropy", optimizer = "adagrad", metrics = "accuracy"
)يمكننا الآن ملاءمة النموذج باستخدام طريقة الملاءمة من Keras. بعض الحجج المناسبة هي:
عهود : الحقبة هي تكرار لمجموعة بيانات التدريب.
حجم الدفعة : يقوم النموذج بتقسيم المصفوفة / المصفوفة التي تم تمريرها إليها إلى مجموعات أصغر يتم تكرارها أثناء التدريب.
Validation_split : سيحتاج Keras إلى تقسيم جزء من بيانات التدريب للحصول على مجموعة التحقق التي سيتم استخدامها لتقييم أداء النموذج لكل فترة.
خلط ورق اللعب : هنا تحدد ما إذا كنت تريد خلط بيانات التدريب قبل كل فترة.
fit = model %>% fit( x = x, y = y, shuffle = T, validation_split = 0.2, epochs = 100, batch_size = 5
)قيم النموذج
للحصول على قيمة دقة النموذج ، استخدم وظيفة التقييم على النحو التالي.
y_test - to_categorical(y_test, num_classes = 2)
model %>% evaluate(as.matrix(x_test),y_test)تنبؤ
للتنبؤ بالبيانات الجديدة ، استخدم وظيفة التنبؤ من مكتبة keras على النحو التالي.
model %>% predict(as.matrix(x_test))لقد أخذك هذا المقال من خلال أساسيات التعلم العميق باستخدام Keras in R. فنحن نرحب بك للغطس بشكل أعمق من أجل فهم أفضل ، والتلاعب بالمعايير ، وتسخير يديك في إعداد البيانات ، وربما توسيع نطاق الحسابات من خلال الاستفادة من القوة الحوسبة السحابية.
كلينتون أويجو الكاتب في زحل سحابة يعتقد أن تحليل البيانات للحصول على رؤى قابلة للتنفيذ جزء مهم من عمله اليومي. بفضل مهاراته في تصور البيانات ، ومناقشة البيانات ، والتعلم الآلي ، يفخر بعمله كعالم بيانات.
أصلي. تم إعادة النشر بإذن.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- أفلاطونايستريم. ذكاء بيانات Web3. تضخيم المعرفة. الوصول هنا.
- سك المستقبل مع أدرين أشلي. الوصول هنا.
- شراء وبيع الأسهم في شركات ما قبل الاكتتاب مع PREIPO®. الوصول هنا.
- المصدر https://www.kdnuggets.com/2023/05/deep-learning-r.html?utm_source=rss&utm_medium=rss&utm_campaign=deep-learning-with-r

